 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhibo Gong
Reward Design in Cooperative Multi-agent Reinforcement Learning for Packet Routing
Mar 05, 2020
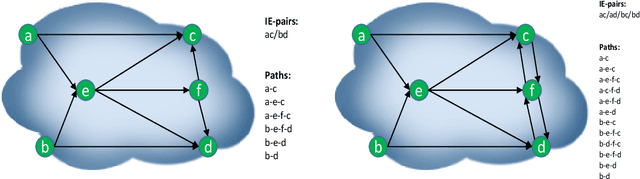
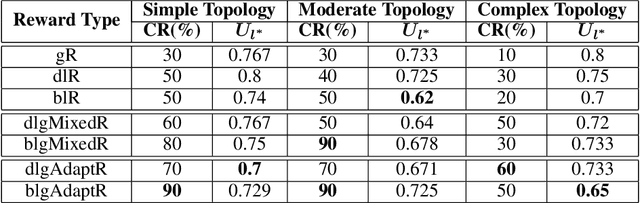

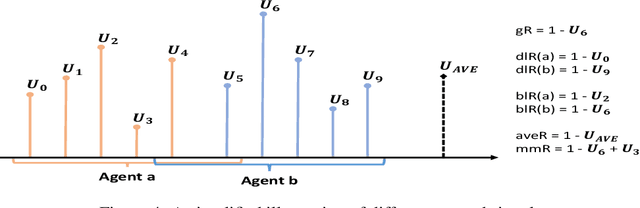
In cooperative multi-agent reinforcement learning (MARL), how to design a suitable reward signal to accelerate learning and stabilize convergence is a critical problem. The global reward signal assigns the same global reward to all agents without distinguishing their contributions, while the local reward signal provides different local rewards to each agent based solely on individual behavior. Both of the two reward assignment approaches have some shortcomings: the former might encourage lazy agents, while the latter might produce selfish agents. In this paper, we study reward design problem in cooperative MARL based on packet routing environments. Firstly, we show that the above two reward signals are prone to produce suboptimal policies. Then, inspired by some observations and considerations, we design some mixed reward signals, which are off-the-shelf to learn better policies. Finally, we turn the mixed reward signals into the adaptive counterparts, which achieve best results in our experiments. Other reward signals are also discussed in this paper. As reward design is a very fundamental problem in RL and especially in MARL, we hope that MARL researchers can rethink the rewards used in their systems.
Learning Agent Communication under Limited Bandwidth by Message Pruning
Dec 03, 2019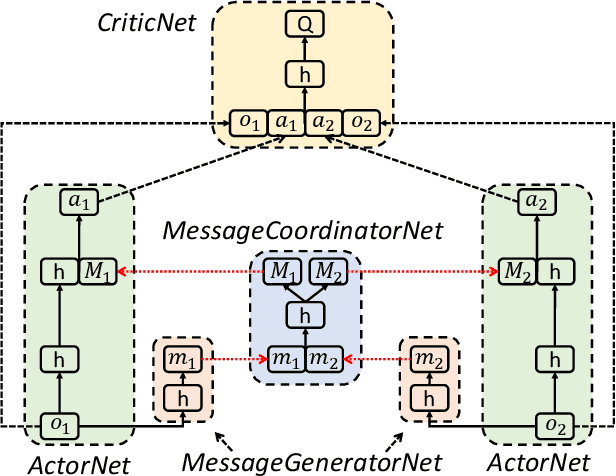
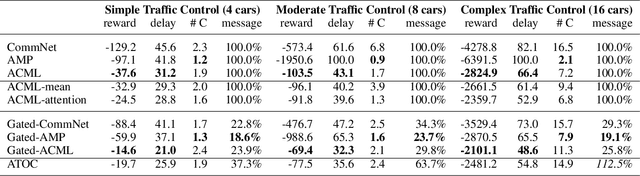
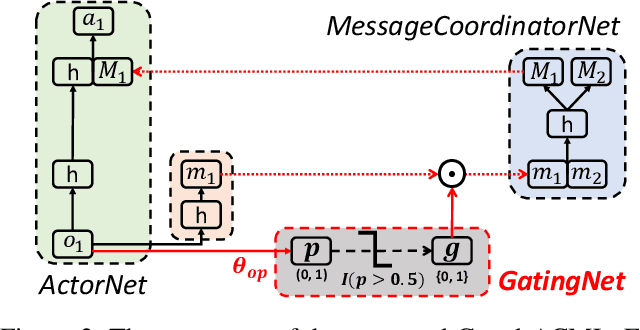
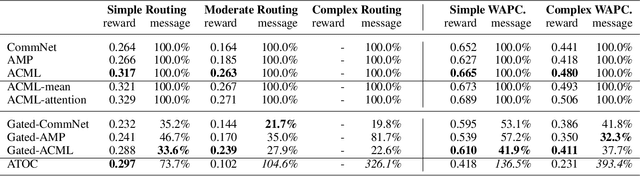
Communication is a crucial factor for the big multi-agent world to stay organized and productive. Recently, Deep Reinforcement Learning (DRL) has been applied to learn the communication strategy and the control policy for multiple agents. However, the practical \emph{\textbf{limited bandwidth}} in multi-agent communication has been largely ignored by the existing DRL methods. Specifically, many methods keep sending messages incessantly, which consumes too much bandwidth. As a result, they are inapplicable to multi-agent systems with limited bandwidth. To handle this problem, we propose a gating mechanism to adaptively prune less beneficial messages. We evaluate the gating mechanism on several tasks. Experiments demonstrate that it can prune a lot of messages with little impact on performance. In fact, the performance may be greatly improved by pruning redundant messages. Moreover, the proposed gating mechanism is applicable to several previous methods, equipping them the ability to address bandwidth restricted settings.
Learning Multi-agent Communication under Limited-bandwidth Restriction for Internet Packet Routing
Feb 26, 2019
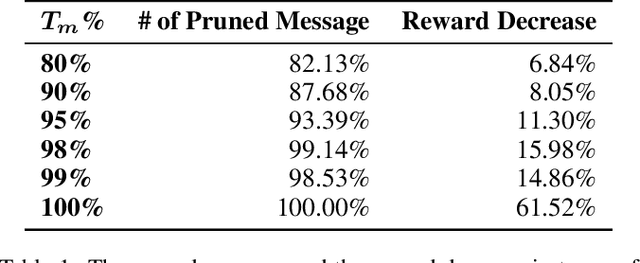

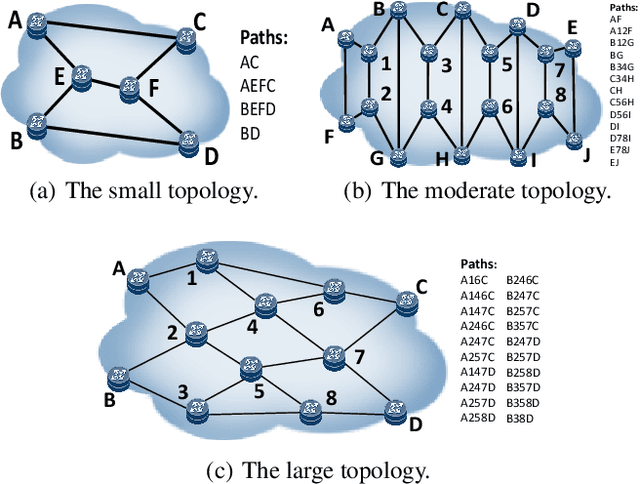
Communication is an important factor for the big multi-agent world to stay organized and productive. Recently, the AI community has applied the Deep Reinforcement Learning (DRL) to learn the communication strategy and the control policy for multiple agents. However, when implementing the communication for real-world multi-agent applications, there is a more practical limited-bandwidth restriction, which has been largely ignored by the existing DRL-based methods. Specifically, agents trained by most previous methods keep sending messages incessantly in every control cycle; due to emitting too many messages, these methods are unsuitable to be applied to the real-world systems that have a limited bandwidth to transmit the messages. To handle this problem, we propose a gating mechanism to adaptively prune unprofitable messages. Results show that the gating mechanism can prune more than 80% messages with little damage to the performance. Moreover, our method outperforms several state-of-the-art DRL-based and rule-based methods by a large margin in both the real-world packet routing tasks and four benchmark tasks.
Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG
Nov 13, 2018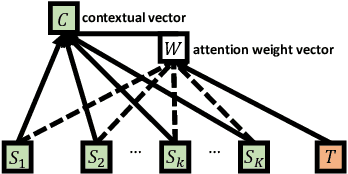
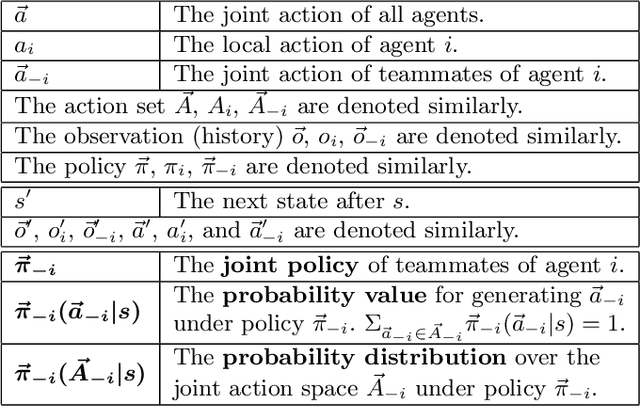
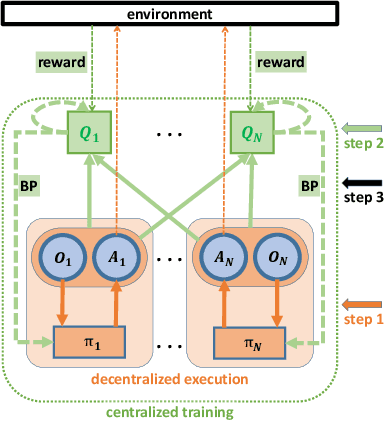
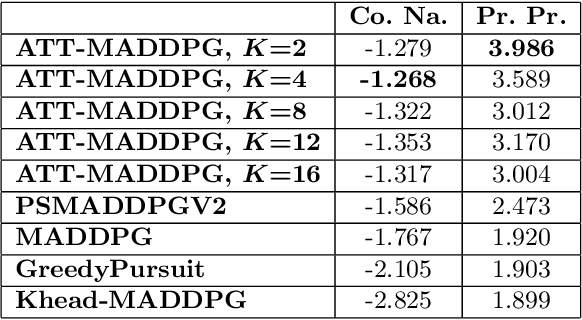
Modelling and exploiting teammates' policies in cooperative multi-agent systems have long been an interest and also a big challenge for the reinforcement learning (RL) community. The interest lies in the fact that if the agent knows the teammates' policies, it can adjust its own policy accordingly to arrive at proper cooperations; while the challenge is that the agents' policies are changing continuously due to they are learning concurrently, which imposes difficulty to model the dynamic policies of teammates accurately. In this paper, we present \emph{ATTention Multi-Agent Deep Deterministic Policy Gradient} (ATT-MADDPG) to address this challenge. ATT-MADDPG extends DDPG, a single-agent actor-critic RL method, with two special designs. First, in order to model the teammates' policies, the agent should get access to the observations and actions of teammates. ATT-MADDPG adopts a centralized critic to collect such information. Second, to model the teammates' policies using the collected information in an effective way, ATT-MADDPG enhances the centralized critic with an attention mechanism. This attention mechanism introduces a special structure to explicitly model the dynamic joint policy of teammates, making sure that the collected information can be processed efficiently. We evaluate ATT-MADDPG on both benchmark tasks and the real-world packet routing tasks. Experimental results show that it not only outperforms the state-of-the-art RL-based methods and rule-based methods by a large margin, but also achieves better performance in terms of scalability and robustness.
ACCNet: Actor-Coordinator-Critic Net for "Learning-to-Communicate" with Deep Multi-agent Reinforcement Learning
Oct 29, 2017
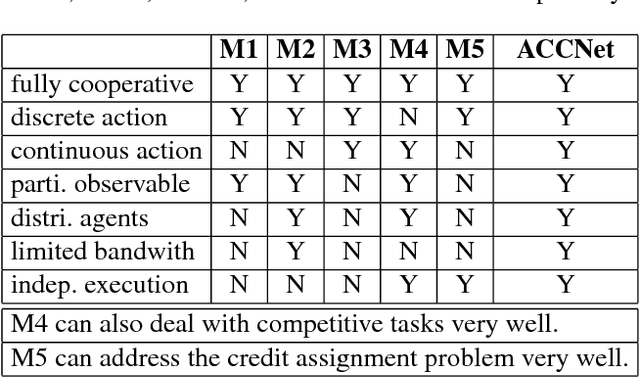
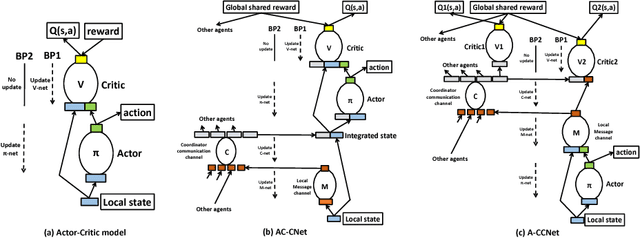
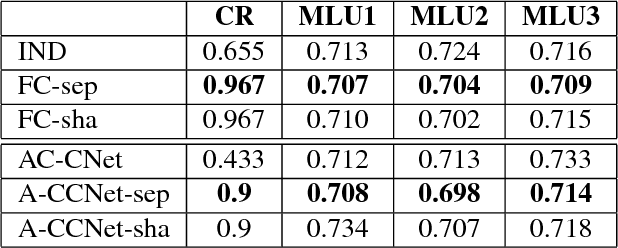
Communication is a critical factor for the big multi-agent world to stay organized and productive. Typically, most previous multi-agent "learning-to-communicate" studies try to predefine the communication protocols or use technologies such as tabular reinforcement learning and evolutionary algorithm, which can not generalize to changing environment or large collection of agents. In this paper, we propose an Actor-Coordinator-Critic Net (ACCNet) framework for solving "learning-to-communicate" problem. The ACCNet naturally combines the powerful actor-critic reinforcement learning technology with deep learning technology. It can efficiently learn the communication protocols even from scratch under partially observable environment. We demonstrate that the ACCNet can achieve better results than several baselines under both continuous and discrete action space environments. We also analyse the learned protocols and discuss some design considerations.