 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhichao Wang
Nonlinear spiked covariance matrices and signal propagation in deep neural networks
Feb 15, 2024
Many recent works have studied the eigenvalue spectrum of the Conjugate Kernel (CK) defined by the nonlinear feature map of a feedforward neural network. However, existing results only establish weak convergence of the empirical eigenvalue distribution, and fall short of providing precise quantitative characterizations of the ''spike'' eigenvalues and eigenvectors that often capture the low-dimensional signal structure of the learning problem. In this work, we characterize these signal eigenvalues and eigenvectors for a nonlinear version of the spiked covariance model, including the CK as a special case. Using this general result, we give a quantitative description of how spiked eigenstructure in the input data propagates through the hidden layers of a neural network with random weights. As a second application, we study a simple regime of representation learning where the weight matrix develops a rank-one signal component over training and characterize the alignment of the target function with the spike eigenvector of the CK on test data.
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Feb 07, 2024Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech, and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experimental results demonstrate StreamVoice's streaming conversion capability while maintaining zero-shot performance comparable to non-streaming VC systems.
FedRec+: Enhancing Privacy and Addressing Heterogeneity in Federated Recommendation Systems
Oct 31, 2023Preserving privacy and reducing communication costs for edge users pose significant challenges in recommendation systems. Although federated learning has proven effective in protecting privacy by avoiding data exchange between clients and servers, it has been shown that the server can infer user ratings based on updated non-zero gradients obtained from two consecutive rounds of user-uploaded gradients. Moreover, federated recommendation systems (FRS) face the challenge of heterogeneity, leading to decreased recommendation performance. In this paper, we propose FedRec+, an ensemble framework for FRS that enhances privacy while addressing the heterogeneity challenge. FedRec+ employs optimal subset selection based on feature similarity to generate near-optimal virtual ratings for pseudo items, utilizing only the user's local information. This approach reduces noise without incurring additional communication costs. Furthermore, we utilize the Wasserstein distance to estimate the heterogeneity and contribution of each client, and derive optimal aggregation weights by solving a defined optimization problem. Experimental results demonstrate the state-of-the-art performance of FedRec+ across various reference datasets.
U-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Oct 06, 2023Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.
VITS-Based Singing Voice Conversion Leveraging Whisper and multi-scale F0 Modeling
Oct 04, 2023This paper introduces the T23 team's system submitted to the Singing Voice Conversion Challenge 2023. Following the recognition-synthesis framework, our singing conversion model is based on VITS, incorporating four key modules: a prior encoder, a posterior encoder, a decoder, and a parallel bank of transposed convolutions (PBTC) module. We particularly leverage Whisper, a powerful pre-trained ASR model, to extract bottleneck features (BNF) as the input of the prior encoder. Before BNF extraction, we perform pitch perturbation to the source signal to remove speaker timbre, which effectively avoids the leakage of the source speaker timbre to the target. Moreover, the PBTC module extracts multi-scale F0 as the auxiliary input to the prior encoder, thereby capturing better pitch variations of singing. We design a three-stage training strategy to better adapt the base model to the target speaker with limited target speaker data. Official challenge results show that our system has superior performance in naturalness, ranking 1st and 2nd respectively in Task 1 and 2. Further ablation justifies the effectiveness of our system design.
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023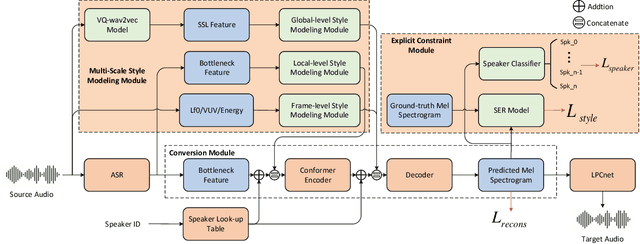
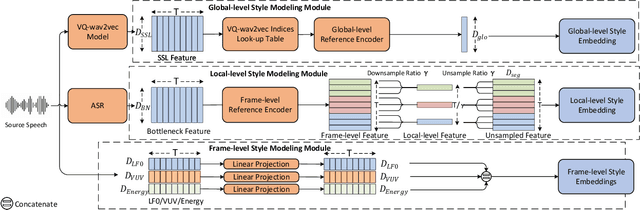
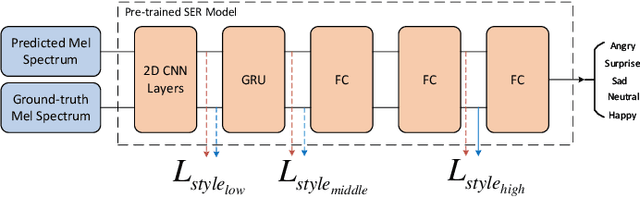
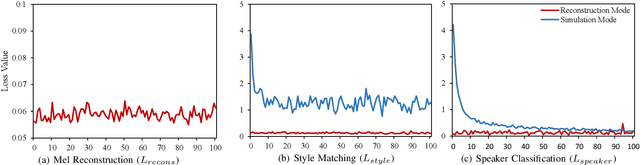
In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
Text-to-Video: a Two-stage Framework for Zero-shot Identity-agnostic Talking-head Generation
Aug 12, 2023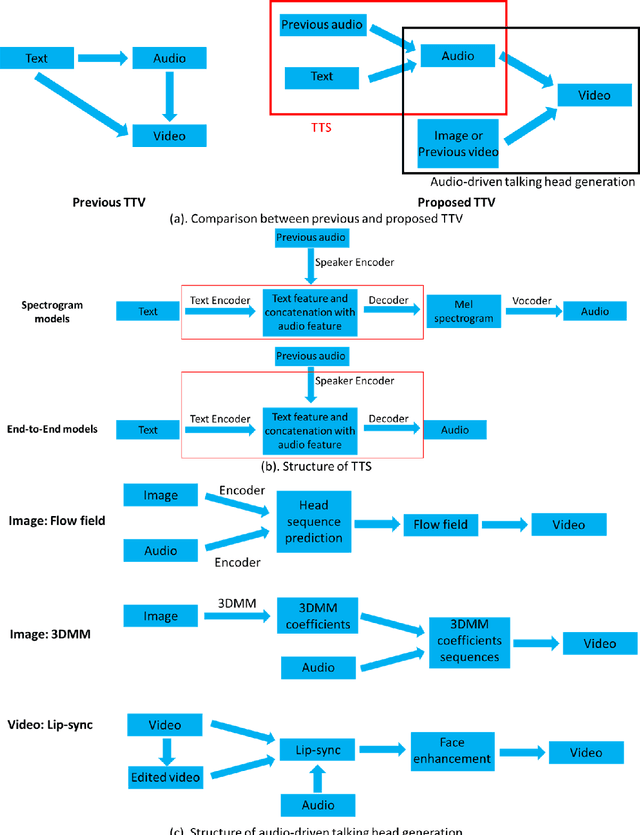

The advent of ChatGPT has introduced innovative methods for information gathering and analysis. However, the information provided by ChatGPT is limited to text, and the visualization of this information remains constrained. Previous research has explored zero-shot text-to-video (TTV) approaches to transform text into videos. However, these methods lacked control over the identity of the generated audio, i.e., not identity-agnostic, hindering their effectiveness. To address this limitation, we propose a novel two-stage framework for person-agnostic video cloning, specifically focusing on TTV generation. In the first stage, we leverage pretrained zero-shot models to achieve text-to-speech (TTS) conversion. In the second stage, an audio-driven talking head generation method is employed to produce compelling videos privided the audio generated in the first stage. This paper presents a comparative analysis of different TTS and audio-driven talking head generation methods, identifying the most promising approach for future research and development. Some audio and videos samples can be found in the following link: https://github.com/ZhichaoWang970201/Text-to-Video/tree/main.
Auxiliary-Tasks Learning for Physics-Informed Neural Network-Based Partial Differential Equations Solving
Jul 12, 2023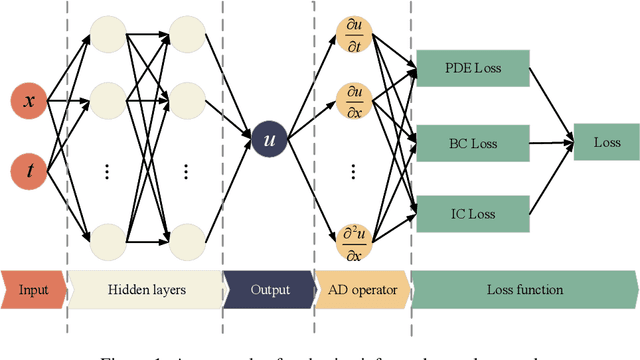
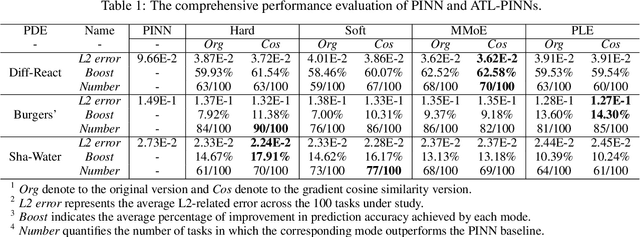
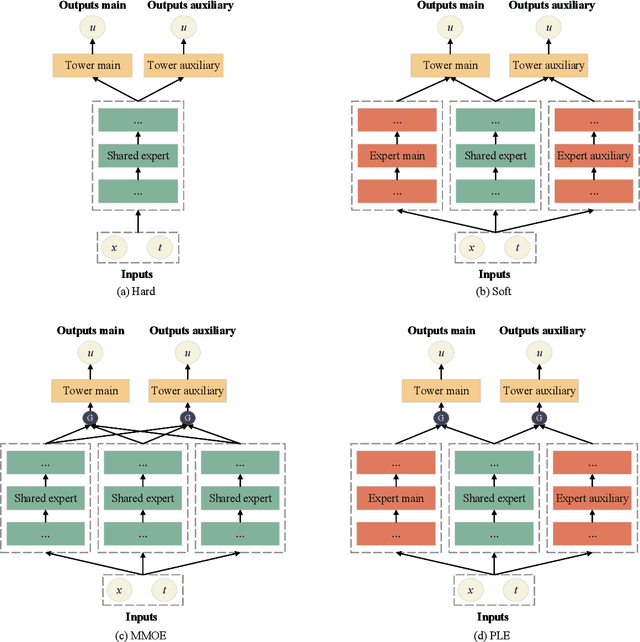

Physics-informed neural networks (PINNs) have emerged as promising surrogate modes for solving partial differential equations (PDEs). Their effectiveness lies in the ability to capture solution-related features through neural networks. However, original PINNs often suffer from bottlenecks, such as low accuracy and non-convergence, limiting their applicability in complex physical contexts. To alleviate these issues, we proposed auxiliary-task learning-based physics-informed neural networks (ATL-PINNs), which provide four different auxiliary-task learning modes and investigate their performance compared with original PINNs. We also employ the gradient cosine similarity algorithm to integrate auxiliary problem loss with the primary problem loss in ATL-PINNs, which aims to enhance the effectiveness of the auxiliary-task learning modes. To the best of our knowledge, this is the first study to introduce auxiliary-task learning modes in the context of physics-informed learning. We conduct experiments on three PDE problems across different fields and scenarios. Our findings demonstrate that the proposed auxiliary-task learning modes can significantly improve solution accuracy, achieving a maximum performance boost of 96.62% (averaging 28.23%) compared to the original single-task PINNs. The code and dataset are open source at https://github.com/junjun-yan/ATL-PINN.
LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
Jun 18, 2023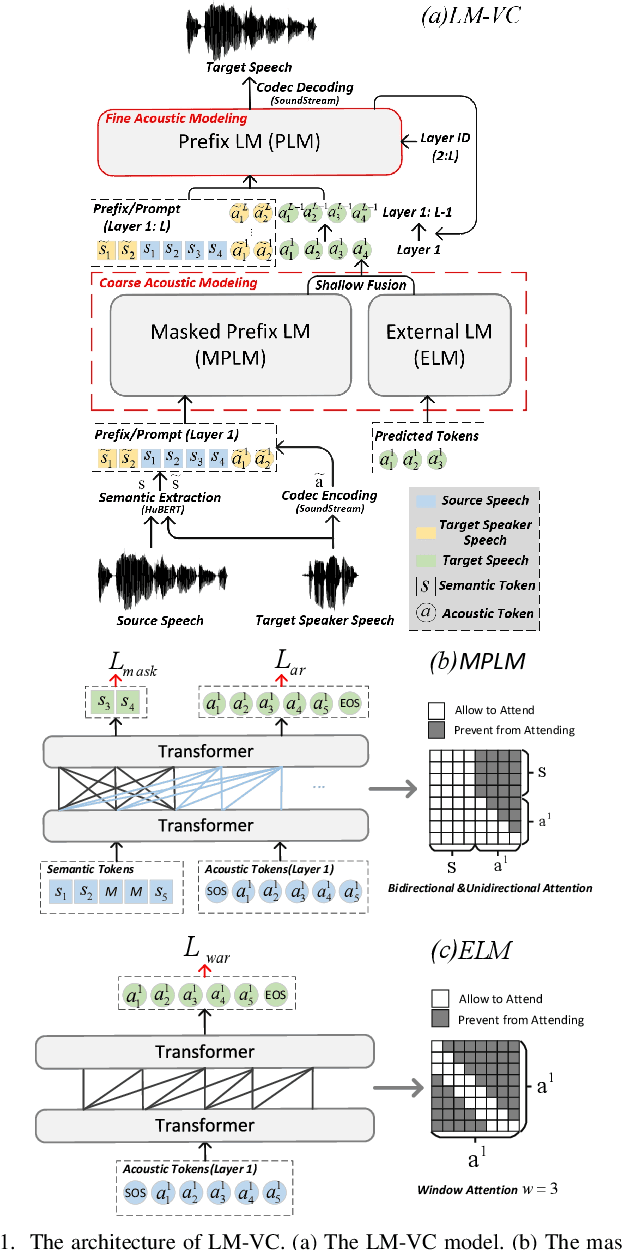
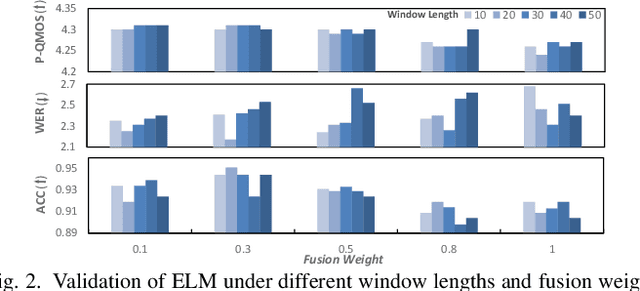
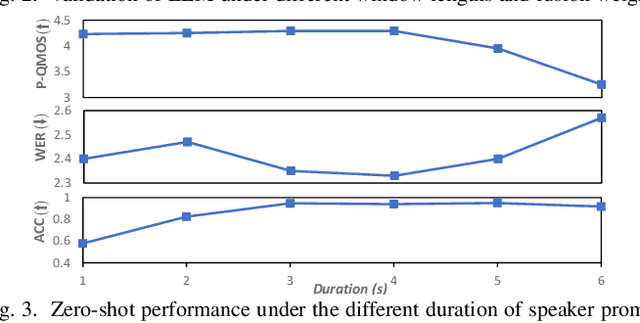
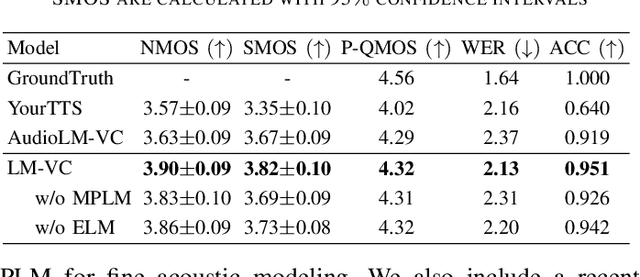
Language model (LM) based audio generation frameworks, e.g., AudioLM, have recently achieved new state-of-the-art performance in zero-shot audio generation. In this paper, we explore the feasibility of LMs for zero-shot voice conversion. An intuitive approach is to follow AudioLM - Tokenizing speech into semantic and acoustic tokens respectively by HuBERT and SoundStream, and converting source semantic tokens to target acoustic tokens conditioned on acoustic tokens of the target speaker. However, such an approach encounters several issues: 1) the linguistic content contained in semantic tokens may get dispersed during multi-layer modeling while the lengthy speech input in the voice conversion task makes contextual learning even harder; 2) the semantic tokens still contain speaker-related information, which may be leaked to the target speech, lowering the target speaker similarity; 3) the generation diversity in the sampling of the LM can lead to unexpected outcomes during inference, leading to unnatural pronunciation and speech quality degradation. To mitigate these problems, we propose LM-VC, a two-stage language modeling approach that generates coarse acoustic tokens for recovering the source linguistic content and target speaker's timbre, and then reconstructs the fine for acoustic details as converted speech. Specifically, to enhance content preservation and facilitates better disentanglement, a masked prefix LM with a mask prediction strategy is used for coarse acoustic modeling. This model is encouraged to recover the masked content from the surrounding context and generate target speech based on the target speaker's utterance and corrupted semantic tokens. Besides, to further alleviate the sampling error in the generation, an external LM, which employs window attention to capture the local acoustic relations, is introduced to participate in the coarse acoustic modeling.
ST-PINN: A Self-Training Physics-Informed Neural Network for Partial Differential Equations
Jun 15, 2023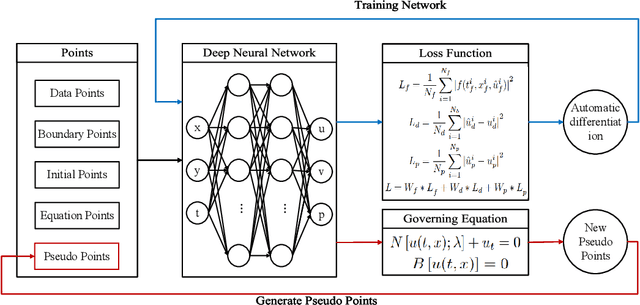
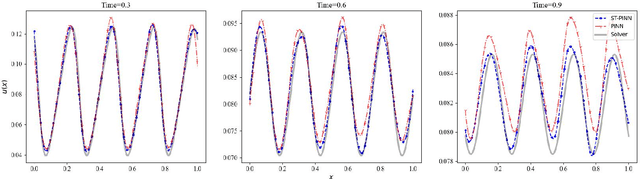
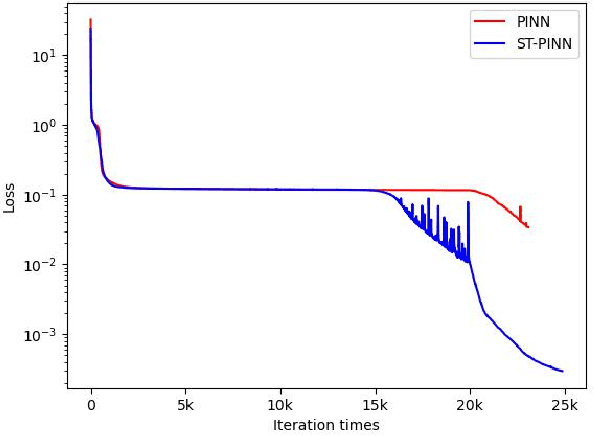
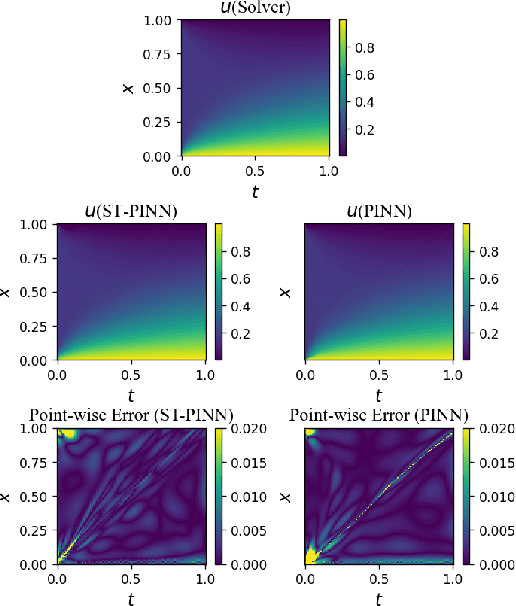
Partial differential equations (PDEs) are an essential computational kernel in physics and engineering. With the advance of deep learning, physics-informed neural networks (PINNs), as a mesh-free method, have shown great potential for fast PDE solving in various applications. To address the issue of low accuracy and convergence problems of existing PINNs, we propose a self-training physics-informed neural network, ST-PINN. Specifically, ST-PINN introduces a pseudo label based self-learning algorithm during training. It employs governing equation as the pseudo-labeled evaluation index and selects the highest confidence examples from the sample points to attach the pseudo labels. To our best knowledge, we are the first to incorporate a self-training mechanism into physics-informed learning. We conduct experiments on five PDE problems in different fields and scenarios. The results demonstrate that the proposed method allows the network to learn more physical information and benefit convergence. The ST-PINN outperforms existing physics-informed neural network methods and improves the accuracy by a factor of 1.33x-2.54x. The code of ST-PINN is available at GitHub: https://github.com/junjun-yan/ST-PINN.