 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhida Sun
EL-VIT: Probing Vision Transformer with Interactive Visualization
Jan 23, 2024
Nowadays, Vision Transformer (ViT) is widely utilized in various computer vision tasks, owing to its unique self-attention mechanism. However, the model architecture of ViT is complex and often challenging to comprehend, leading to a steep learning curve. ViT developers and users frequently encounter difficulties in interpreting its inner workings. Therefore, a visualization system is needed to assist ViT users in understanding its functionality. This paper introduces EL-VIT, an interactive visual analytics system designed to probe the Vision Transformer and facilitate a better understanding of its operations. The system consists of four layers of visualization views. The first three layers include model overview, knowledge background graph, and model detail view. These three layers elucidate the operation process of ViT from three perspectives: the overall model architecture, detailed explanation, and mathematical operations, enabling users to understand the underlying principles and the transition process between layers. The fourth interpretation view helps ViT users and experts gain a deeper understanding by calculating the cosine similarity between patches. Our two usage scenarios demonstrate the effectiveness and usability of EL-VIT in helping ViT users understand the working mechanism of ViT.
VoiceCoach: Interactive Evidence-based Training for Voice Modulation Skills in Public Speaking
Jan 22, 2020
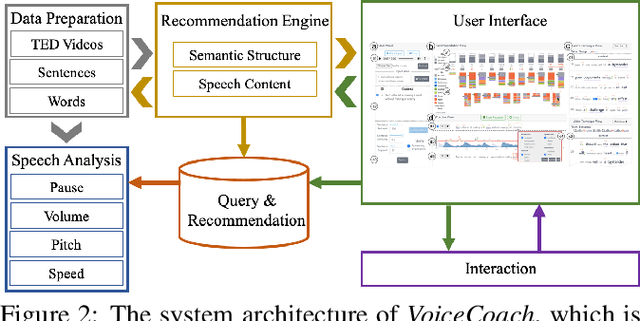

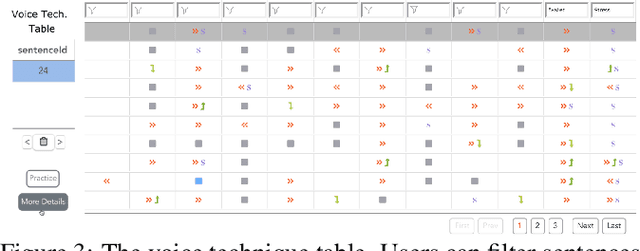
The modulation of voice properties, such as pitch, volume, and speed, is crucial for delivering a successful public speech. However, it is challenging to master different voice modulation skills. Though many guidelines are available, they are often not practical enough to be applied in different public speaking situations, especially for novice speakers. We present VoiceCoach, an interactive evidence-based approach to facilitate the effective training of voice modulation skills. Specifically, we have analyzed the voice modulation skills from 2623 high-quality speeches (i.e., TED Talks) and use them as the benchmark dataset. Given a voice input, VoiceCoach automatically recommends good voice modulation examples from the dataset based on the similarity of both sentence structures and voice modulation skills. Immediate and quantitative visual feedback is provided to guide further improvement. The expert interviews and the user study provide support for the effectiveness and usability of VoiceCoach.