 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiheng Zhou
Improve Cross-domain Mixed Sampling with Guidance Training for Adaptive Segmentation
Mar 22, 2024
Unsupervised Domain Adaptation (UDA) endeavors to adjust models trained on a source domain to perform well on a target domain without requiring additional annotations. In the context of domain adaptive semantic segmentation, which tackles UDA for dense prediction, the goal is to circumvent the need for costly pixel-level annotations. Typically, various prevailing methods baseline rely on constructing intermediate domains via cross-domain mixed sampling techniques to mitigate the performance decline caused by domain gaps. However, such approaches generate synthetic data that diverge from real-world distributions, potentially leading the model astray from the true target distribution. To address this challenge, we propose a novel auxiliary task called Guidance Training. This task facilitates the effective utilization of cross-domain mixed sampling techniques while mitigating distribution shifts from the real world. Specifically, Guidance Training guides the model to extract and reconstruct the target-domain feature distribution from mixed data, followed by decoding the reconstructed target-domain features to make pseudo-label predictions. Importantly, integrating Guidance Training incurs minimal training overhead and imposes no additional inference burden. We demonstrate the efficacy of our approach by integrating it with existing methods, consistently improving performance. The implementation will be available at https://github.com/Wenlve-Zhou/Guidance-Training.
Exploring Hardware Friendly Bottleneck Architecture in CNN for Embedded Computing Systems
Mar 11, 2024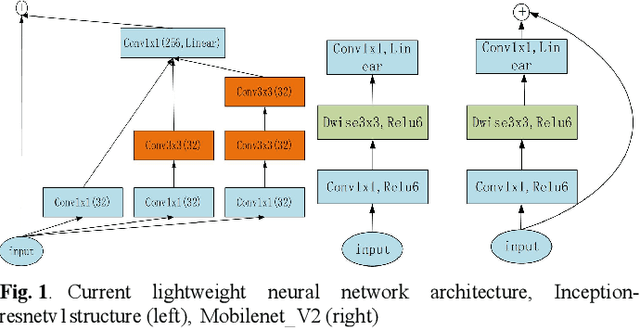

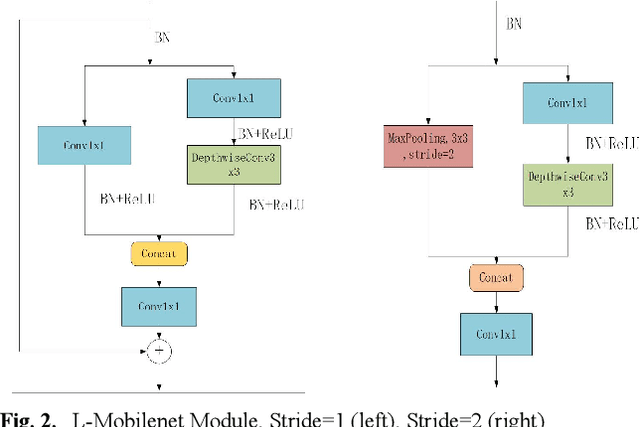
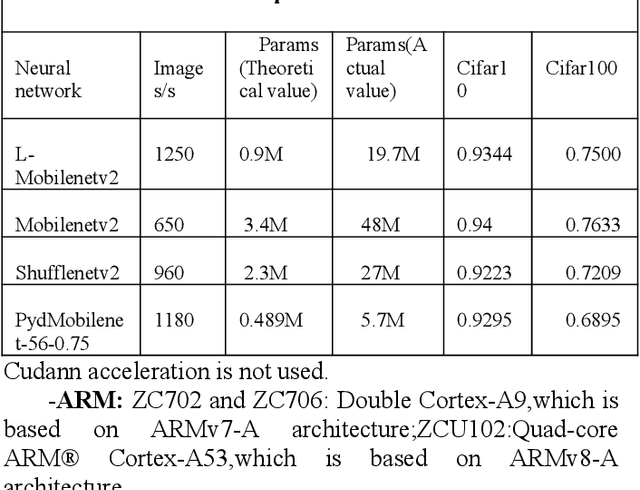
In this paper, we explore how to design lightweight CNN architecture for embedded computing systems. We propose L-Mobilenet model for ZYNQ based hardware platform. L-Mobilenet can adapt well to the hardware computing and accelerating, and its network structure is inspired by the state-of-the-art work of Inception-ResnetV1 and MobilenetV2, which can effectively reduce parameters and delay while maintaining the accuracy of inference. We deploy our L-Mobilenet model to ZYNQ embedded platform for fully evaluating the performance of our design. By measuring in cifar10 and cifar100 datasets, L-Mobilenet model is able to gain 3x speed up and 3.7x fewer parameters than MobileNetV2 while maintaining a similar accuracy. It also can obtain 2x speed up and 1.5x fewer parameters than ShufflenetV2 while maintaining the same accuracy. Experiments show that our network model can obtain better performance because of the special considerations for hardware accelerating and software-hardware co-design strategies in our L-Mobilenet bottleneck architecture.