 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhijian Wu
DMKD: Improving Feature-based Knowledge Distillation for Object Detection Via Dual Masking Augmentation
Sep 07, 2023




Recent mainstream masked distillation methods function by reconstructing selectively masked areas of a student network from the feature map of its teacher counterpart. In these methods, the masked regions need to be properly selected, such that reconstructed features encode sufficient discrimination and representation capability like the teacher feature. However, previous masked distillation methods only focus on spatial masking, making the resulting masked areas biased towards spatial importance without encoding informative channel clues. In this study, we devise a Dual Masked Knowledge Distillation (DMKD) framework which can capture both spatially important and channel-wise informative clues for comprehensive masked feature reconstruction. More specifically, we employ dual attention mechanism for guiding the respective masking branches, leading to reconstructed feature encoding dual significance. Furthermore, fusing the reconstructed features is achieved by self-adjustable weighting strategy for effective feature distillation. Our experiments on object detection task demonstrate that the student networks achieve performance gains of 4.1% and 4.3% with the help of our method when RetinaNet and Cascade Mask R-CNN are respectively used as the teacher networks, while outperforming the other state-of-the-art distillation methods.
EfficientFace: An Efficient Deep Network with Feature Enhancement for Accurate Face Detection
Feb 23, 2023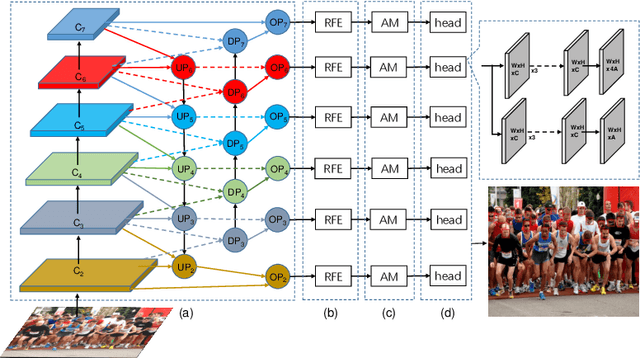

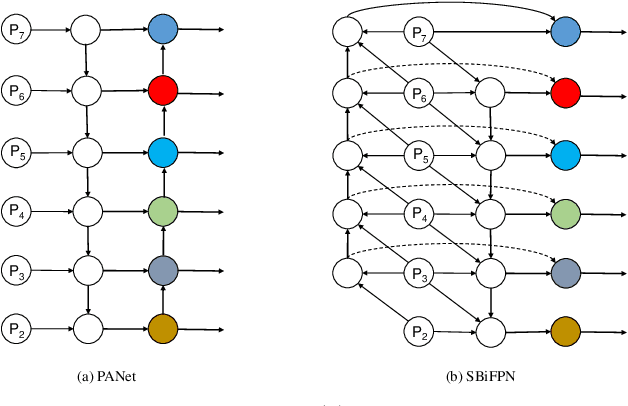
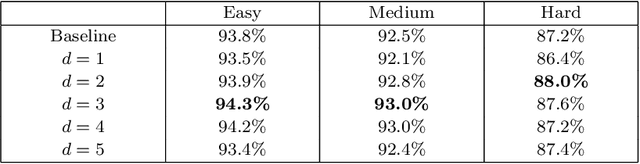
In recent years, deep convolutional neural networks (CNN) have significantly advanced face detection. In particular, lightweight CNNbased architectures have achieved great success due to their lowcomplexity structure facilitating real-time detection tasks. However, current lightweight CNN-based face detectors trading accuracy for efficiency have inadequate capability in handling insufficient feature representation, faces with unbalanced aspect ratios and occlusion. Consequently, they exhibit deteriorated performance far lagging behind the deep heavy detectors. To achieve efficient face detection without sacrificing accuracy, we design an efficient deep face detector termed EfficientFace in this study, which contains three modules for feature enhancement. To begin with, we design a novel cross-scale feature fusion strategy to facilitate bottom-up information propagation, such that fusing low-level and highlevel features is further strengthened. Besides, this is conducive to estimating the locations of faces and enhancing the descriptive power of face features. Secondly, we introduce a Receptive Field Enhancement module to consider faces with various aspect ratios. Thirdly, we add an Attention Mechanism module for improving the representational capability of occluded faces. We have evaluated EfficientFace on four public benchmarks and experimental results demonstrate the appealing performance of our method. In particular, our model respectively achieves 95.1% (Easy), 94.0% (Medium) and 90.1% (Hard) on validation set of WIDER Face dataset, which is competitive with heavyweight models with only 1/15 computational costs of the state-of-the-art MogFace detector.