 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang Cai
A Structure-Guided Gauss-Newton Method for Shallow ReLU Neural Network
Apr 07, 2024
In this paper, we propose a structure-guided Gauss-Newton (SgGN) method for solving least squares problems using a shallow ReLU neural network. The method effectively takes advantage of both the least squares structure and the neural network structure of the objective function. By categorizing the weights and biases of the hidden and output layers of the network as nonlinear and linear parameters, respectively, the method iterates back and forth between the nonlinear and linear parameters. The nonlinear parameters are updated by a damped Gauss-Newton method and the linear ones are updated by a linear solver. Moreover, at the Gauss-Newton step, a special form of the Gauss-Newton matrix is derived for the shallow ReLU neural network and is used for efficient iterations. It is shown that the corresponding mass and Gauss-Newton matrices in the respective linear and nonlinear steps are symmetric and positive definite under reasonable assumptions. Thus, the SgGN method naturally produces an effective search direction without the need of additional techniques like shifting in the Levenberg-Marquardt method to achieve invertibility of the Gauss-Newton matrix. The convergence and accuracy of the method are demonstrated numerically for several challenging function approximation problems, especially those with discontinuities or sharp transition layers that pose significant challenges for commonly used training algorithms in machine learning.
Qubit-Wise Architecture Search Method for Variational Quantum Circuits
Mar 07, 2024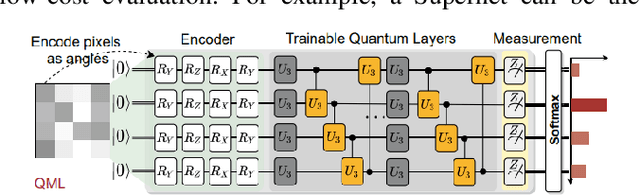

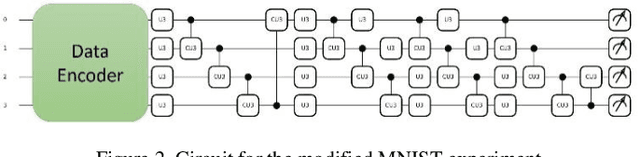
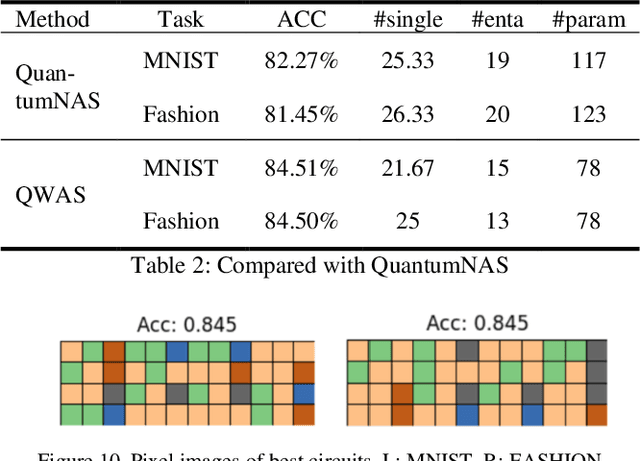
Considering the noise level limit, one crucial aspect for quantum machine learning is to design a high-performing variational quantum circuit architecture with small number of quantum gates. As the classical neural architecture search (NAS), quantum architecture search methods (QAS) employ methods like reinforcement learning, evolutionary algorithms and supernet optimiza-tion to improve the search efficiency. In this paper, we propose a novel qubit-wise architec-ture search (QWAS) method, which progres-sively search one-qubit configuration per stage, and combine with Monte Carlo Tree Search al-gorithm to find good quantum architectures by partitioning the search space into several good and bad subregions. The numerical experimental results indicate that our proposed method can balance the exploration and exploitation of cir-cuit performance and size in some real-world tasks, such as MNIST, Fashion and MOSI. As far as we know, QWAS achieves the state-of-art re-sults of all tasks in the terms of accuracy and circuit size.
Residual-Quantile Adjustment for Adaptive Training of Physics-informed Neural Network
Sep 09, 2022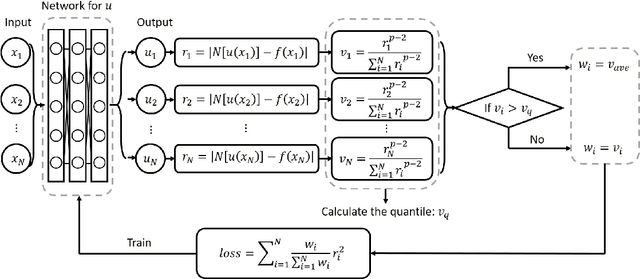

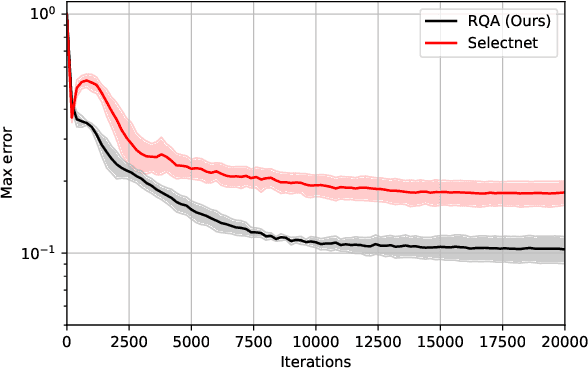
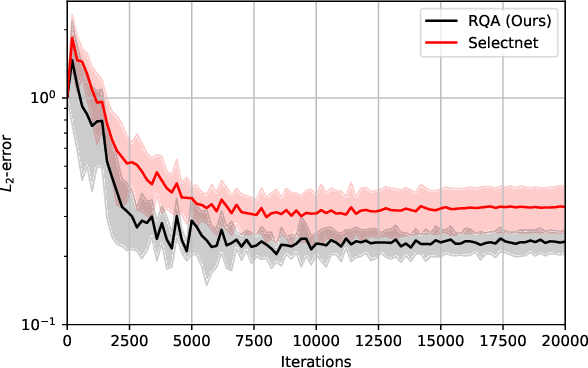
Adaptive training methods for physical-informed neural network (PINN) require dedicated constructions of the distribution of weights assigned at each training sample. To efficiently seek such an optimal weight distribution is not a simple task and most existing methods choose the adaptive weights based on approximating the full distribution or the maximum of residuals. In this paper, we show that the bottleneck in the adaptive choice of samples for training efficiency is the behavior of the tail distribution of the numerical residual. Thus, we propose the Residual-Quantile Adjustment (RQA) method for a better weight choice for each training sample. After initially setting the weights proportional to the $p$-th power of the residual, our RQA method reassign all weights above $q$-quantile ($90\%$ for example) to the median value, so that the weight follows a quantile-adjusted distribution derived from the residuals. With the iterative reweighting technique, RQA is also very easy to implement. Experiment results show that the proposed method can outperform several adaptive methods on various partial differential equation (PDE) problems.
Learn Quasi-stationary Distributions of Finite State Markov Chain
Nov 19, 2021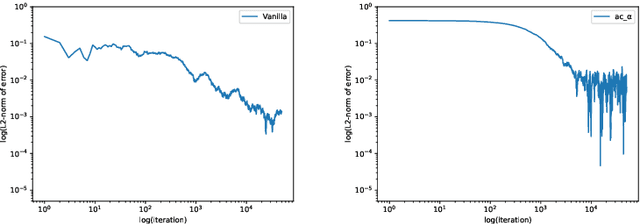
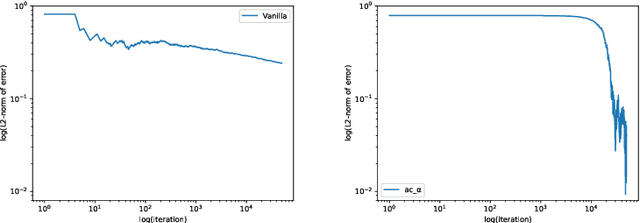
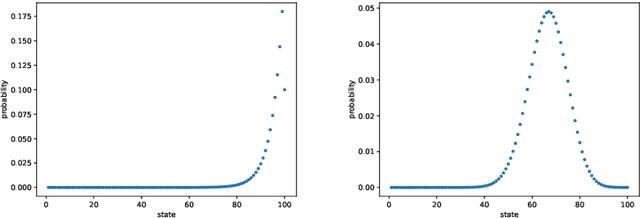
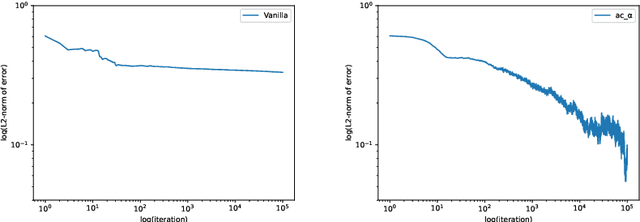
We propose a reinforcement learning (RL) approach to compute the expression of quasi-stationary distribution. Based on the fixed-point formulation of quasi-stationary distribution, we minimize the KL-divergence of two Markovian path distributions induced by the candidate distribution and the true target distribution. To solve this challenging minimization problem by gradient descent, we apply the reinforcement learning technique by introducing the corresponding reward and value functions. We derive the corresponding policy gradient theorem and design an actor-critic algorithm to learn the optimal solution and value function. The numerical examples of finite state Markov chain are tested to demonstrate the new methods
Finite Volume Least-Squares Neural Network (FV-LSNN) Method for Scalar Nonlinear Hyperbolic Conservation Laws
Oct 21, 2021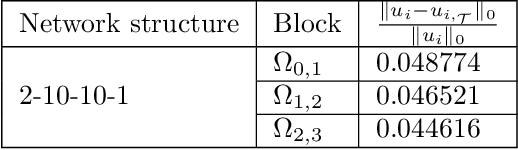
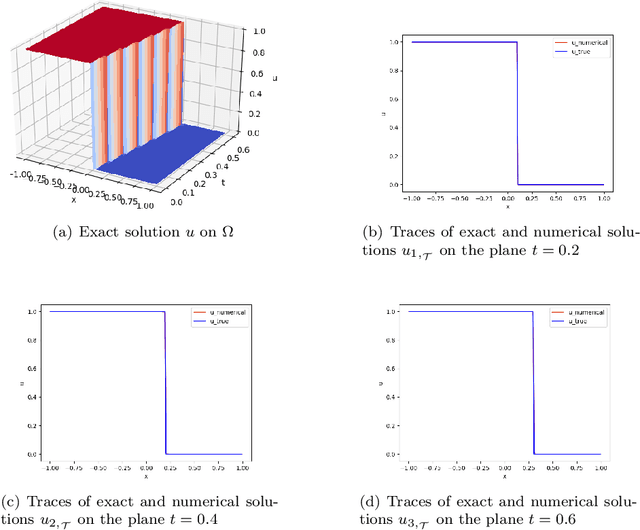
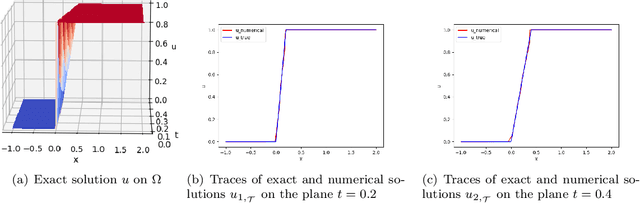
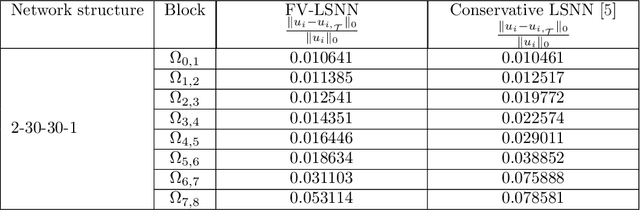
In [4], we introduced the least-squares ReLU neural network (LSNN) method for solving the linear advection-reaction problem with discontinuous solution and showed that the number of degrees of freedom for the LSNN method is significantly less than that of traditional mesh-based methods. The LSNN method is a discretization of an equivalent least-squares (LS) formulation in the class of neural network functions with the ReLU activation function; and evaluation of the LS functional is done by using numerical integration and proper numerical differentiation. By developing a novel finite volume approximation (FVA) to the divergence operator, this paper studies the LSNN method for scalar nonlinear hyperbolic conservation laws. The FVA introduced in this paper is tailored to the LSNN method and is more accurate than traditional, well-studied FV schemes used in mesh-based numerical methods. Numerical results of some benchmark test problems with both convex and non-convex fluxes show that the finite volume LSNN (FV-LSNN) method is capable of computing the physical solution for problems with rarefaction waves and capturing the shock of the underlying problem automatically through the free hyper-planes of the ReLU neural network. Moreover, the method does not exhibit the common Gibbs phenomena along the discontinuous interface.
Self-adaptive deep neural network: Numerical approximation to functions and PDEs
Sep 07, 2021
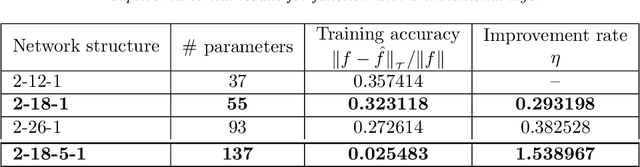
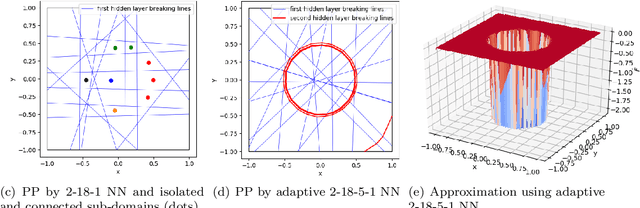
Designing an optimal deep neural network for a given task is important and challenging in many machine learning applications. To address this issue, we introduce a self-adaptive algorithm: the adaptive network enhancement (ANE) method, written as loops of the form train, estimate and enhance. Starting with a small two-layer neural network (NN), the step train is to solve the optimization problem at the current NN; the step estimate is to compute a posteriori estimator/indicators using the solution at the current NN; the step enhance is to add new neurons to the current NN. Novel network enhancement strategies based on the computed estimator/indicators are developed in this paper to determine how many new neurons and when a new layer should be added to the current NN. The ANE method provides a natural process for obtaining a good initialization in training the current NN; in addition, we introduce an advanced procedure on how to initialize newly added neurons for a better approximation. We demonstrate that the ANE method can automatically design a nearly minimal NN for learning functions exhibiting sharp transitional layers as well as discontinuous solutions of hyperbolic partial differential equations.
Least-Squares ReLU Neural Network (LSNN) Method For Linear Advection-Reaction Equation
May 25, 2021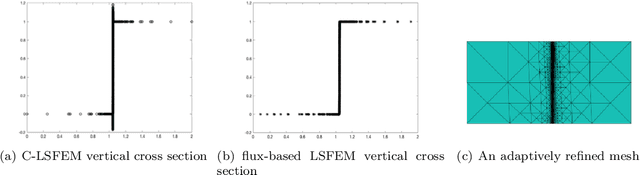
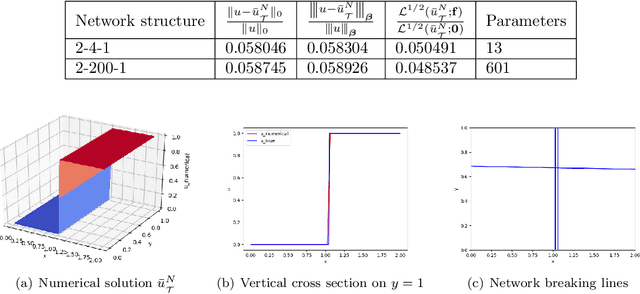
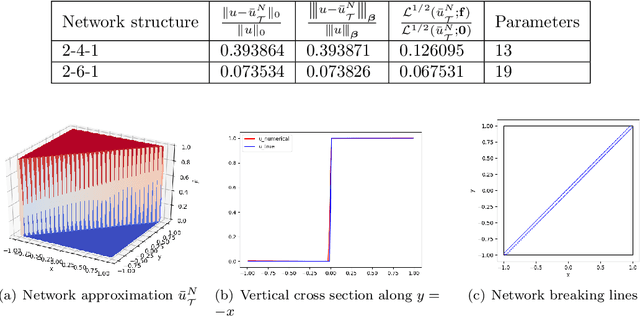

This paper studies least-squares ReLU neural network method for solving the linear advection-reaction problem with discontinuous solution. The method is a discretization of an equivalent least-squares formulation in the set of neural network functions with the ReLU activation function. The method is capable of approximating the discontinuous interface of the underlying problem automatically through the free hyper-planes of the ReLU neural network and, hence, outperforms mesh-based numerical methods in terms of the number of degrees of freedom. Numerical results of some benchmark test problems show that the method can not only approximate the solution with the least number of parameters, but also avoid the common Gibbs phenomena along the discontinuous interface. Moreover, a three-layer ReLU neural network is necessary and sufficient in order to well approximate a discontinuous solution with an interface in $\mathbb{R}^2$ that is not a straight line.
Least-Squares ReLU Neural Network (LSNN) Method For Scalar Nonlinear Hyperbolic Conservation Law
May 25, 2021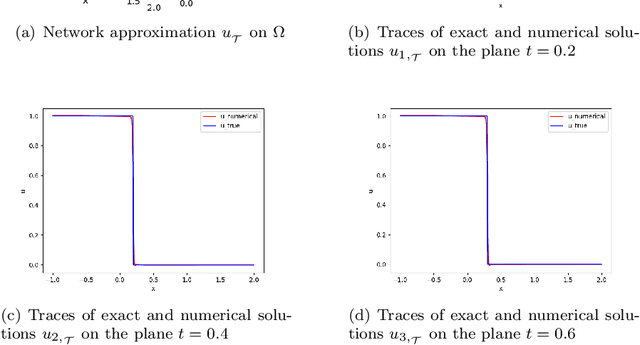
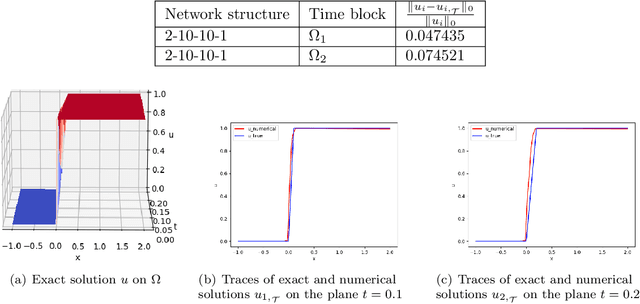
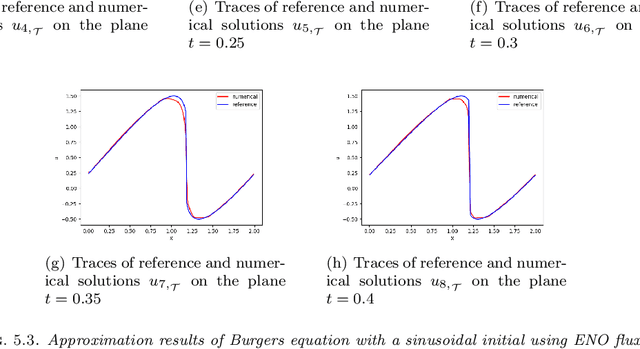
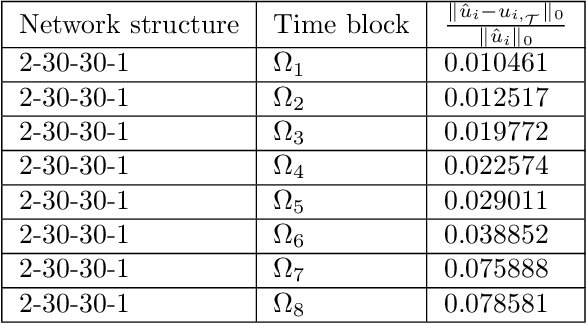
We introduced the least-squares ReLU neural network (LSNN) method for solving the linear advection-reaction problem with discontinuous solution and showed that the method outperforms mesh-based numerical methods in terms of the number of degrees of freedom. This paper studies the LSNN method for scalar nonlinear hyperbolic conservation law. The method is a discretization of an equivalent least-squares (LS) formulation in the set of neural network functions with the ReLU activation function. Evaluation of the LS functional is done by using numerical integration and conservative finite volume scheme. Numerical results of some test problems show that the method is capable of approximating the discontinuous interface of the underlying problem automatically through the free breaking lines of the ReLU neural network. Moreover, the method does not exhibit the common Gibbs phenomena along the discontinuous interface.
Deep least-squares methods: an unsupervised learning-based numerical method for solving elliptic PDEs
Nov 05, 2019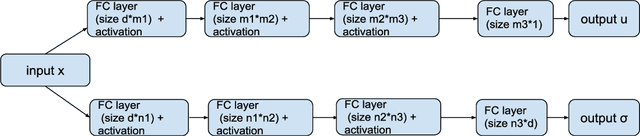
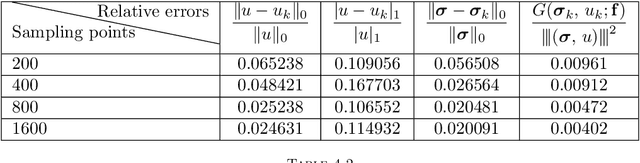

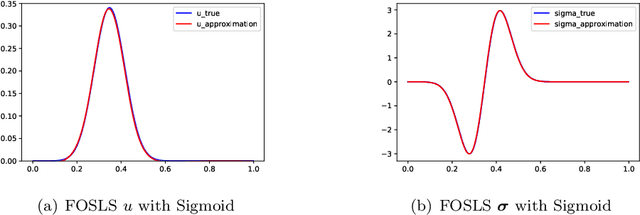
This paper studies an unsupervised deep learning-based numerical approach for solving partial differential equations (PDEs). The approach makes use of the deep neural network to approximate solutions of PDEs through the compositional construction and employs least-squares functionals as loss functions to determine parameters of the deep neural network. There are various least-squares functionals for a partial differential equation. This paper focuses on the so-called first-order system least-squares (FOSLS) functional studied in [3], which is based on a first-order system of scalar second-order elliptic PDEs. Numerical results for second-order elliptic PDEs in one dimension are presented.
An Empirical Study on Academic Commentary and Its Implications on Reading and Writing
Feb 12, 2016



The relationship between reading and writing (RRW) is one of the major themes in learning science. One of its obstacles is that it is difficult to define or measure the latent background knowledge of the individual. However, in an academic research setting, scholars are required to explicitly list their background knowledge in the citation sections of their manuscripts. This unique opportunity was taken advantage of to observe RRW, especially in the published academic commentary scenario. RRW was visualized under a proposed topic process model by using a state of the art version of latent Dirichlet allocation (LDA). The empirical study showed that the academic commentary is modulated both by its target paper and the author's background knowledge. Although this conclusion was obtained in a unique environment, we suggest its implications can also shed light on other similar interesting areas, such as dialog and conversation, group discussion, and social media.