 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang Yan
Tri-Perspective View Decomposition for Geometry-Aware Depth Completion
Mar 22, 2024
Depth completion is a vital task for autonomous driving, as it involves reconstructing the precise 3D geometry of a scene from sparse and noisy depth measurements. However, most existing methods either rely only on 2D depth representations or directly incorporate raw 3D point clouds for compensation, which are still insufficient to capture the fine-grained 3D geometry of the scene. To address this challenge, we introduce Tri-Perspective view Decomposition (TPVD), a novel framework that can explicitly model 3D geometry. In particular, (1) TPVD ingeniously decomposes the original point cloud into three 2D views, one of which corresponds to the sparse depth input. (2) We design TPV Fusion to update the 2D TPV features through recurrent 2D-3D-2D aggregation, where a Distance-Aware Spherical Convolution (DASC) is applied. (3) By adaptively choosing TPV affinitive neighbors, the newly proposed Geometric Spatial Propagation Network (GSPN) further improves the geometric consistency. As a result, our TPVD outperforms existing methods on KITTI, NYUv2, and SUN RGBD. Furthermore, we build a novel depth completion dataset named TOFDC, which is acquired by the time-of-flight (TOF) sensor and the color camera on smartphones. Project page: https://yanzq95.github.io/projectpage/TOFDC/index.html
Scene Prior Filtering for Depth Map Super-Resolution
Feb 23, 2024Multi-modal fusion is vital to the success of super-resolution of depth maps. However, commonly used fusion strategies, such as addition and concatenation, fall short of effectively bridging the modal gap. As a result, guided image filtering methods have been introduced to mitigate this issue. Nevertheless, it is observed that their filter kernels usually encounter significant texture interference and edge inaccuracy. To tackle these two challenges, we introduce a Scene Prior Filtering network, SPFNet, which utilizes the priors surface normal and semantic map from large-scale models. Specifically, we design an All-in-one Prior Propagation that computes the similarity between multi-modal scene priors, i.e., RGB, normal, semantic, and depth, to reduce the texture interference. In addition, we present a One-to-one Prior Embedding that continuously embeds each single-modal prior into depth using Mutual Guided Filtering, further alleviating the texture interference while enhancing edges. Our SPFNet has been extensively evaluated on both real and synthetic datasets, achieving state-of-the-art performance.
SGNet: Structure Guided Network via Gradient-Frequency Awareness for Depth Map Super-Resolution
Dec 13, 2023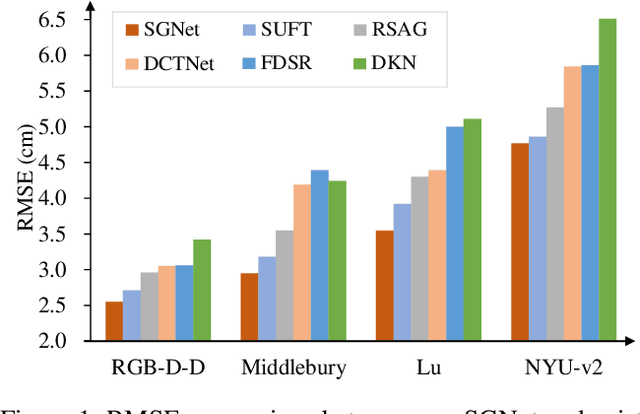

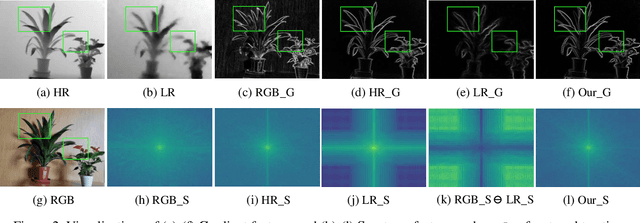
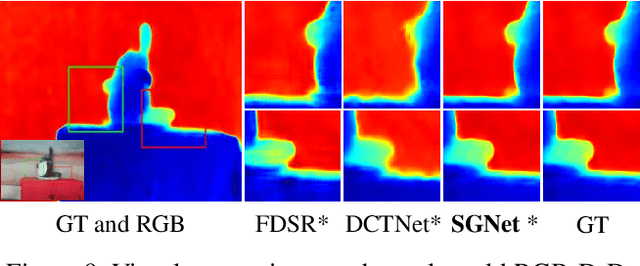
Depth super-resolution (DSR) aims to restore high-resolution (HR) depth from low-resolution (LR) one, where RGB image is often used to promote this task. Recent image guided DSR approaches mainly focus on spatial domain to rebuild depth structure. However, since the structure of LR depth is usually blurry, only considering spatial domain is not very sufficient to acquire satisfactory results. In this paper, we propose structure guided network (SGNet), a method that pays more attention to gradient and frequency domains, both of which have the inherent ability to capture high-frequency structure. Specifically, we first introduce the gradient calibration module (GCM), which employs the accurate gradient prior of RGB to sharpen the LR depth structure. Then we present the Frequency Awareness Module (FAM) that recursively conducts multiple spectrum differencing blocks (SDB), each of which propagates the precise high-frequency components of RGB into the LR depth. Extensive experimental results on both real and synthetic datasets demonstrate the superiority of our SGNet, reaching the state-of-the-art. Codes and pre-trained models are available at https://github.com/yanzq95/SGNet.
RigNet++: Efficient Repetitive Image Guided Network for Depth Completion
Sep 15, 2023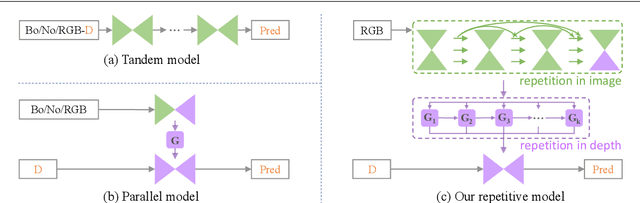
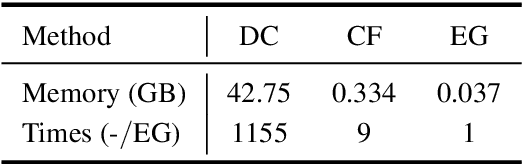
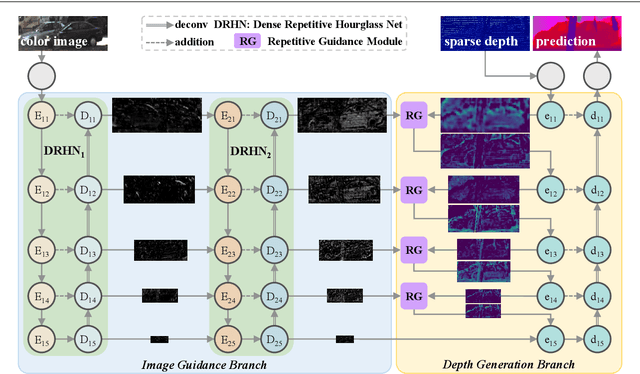

Depth completion aims to recover dense depth maps from sparse ones, where color images are often used to facilitate this task. Recent depth methods primarily focus on image guided learning frameworks. However, blurry guidance in the image and unclear structure in the depth still impede their performance. To tackle these challenges, we explore an efficient repetitive design in our image guided network to gradually and sufficiently recover depth values. Specifically, the efficient repetition is embodied in both the image guidance branch and depth generation branch. In the former branch, we design a dense repetitive hourglass network to extract discriminative image features of complex environments, which can provide powerful contextual instruction for depth prediction. In the latter branch, we introduce a repetitive guidance module based on dynamic convolution, in which an efficient convolution factorization is proposed to reduce the complexity while modeling high-frequency structures progressively. Extensive experiments indicate that our approach achieves superior or competitive results on KITTI, VKITTI, NYUv2, 3D60, and Matterport3D datasets.
AltNeRF: Learning Robust Neural Radiance Field via Alternating Depth-Pose Optimization
Aug 19, 2023
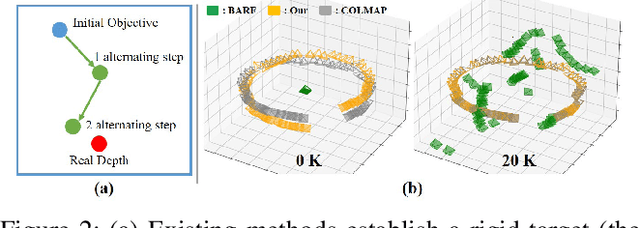
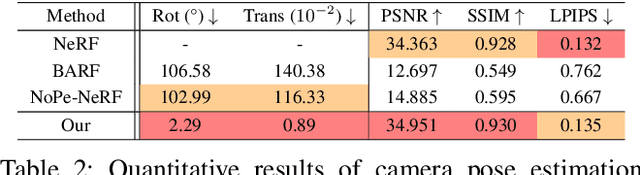
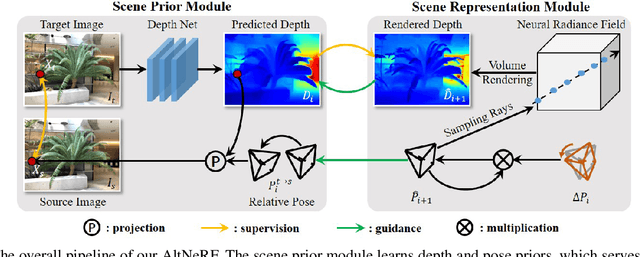
Neural Radiance Fields (NeRF) have shown promise in generating realistic novel views from sparse scene images. However, existing NeRF approaches often encounter challenges due to the lack of explicit 3D supervision and imprecise camera poses, resulting in suboptimal outcomes. To tackle these issues, we propose AltNeRF -- a novel framework designed to create resilient NeRF representations using self-supervised monocular depth estimation (SMDE) from monocular videos, without relying on known camera poses. SMDE in AltNeRF masterfully learns depth and pose priors to regulate NeRF training. The depth prior enriches NeRF's capacity for precise scene geometry depiction, while the pose prior provides a robust starting point for subsequent pose refinement. Moreover, we introduce an alternating algorithm that harmoniously melds NeRF outputs into SMDE through a consistence-driven mechanism, thus enhancing the integrity of depth priors. This alternation empowers AltNeRF to progressively refine NeRF representations, yielding the synthesis of realistic novel views. Additionally, we curate a distinctive dataset comprising indoor videos captured via mobile devices. Extensive experiments showcase the compelling capabilities of AltNeRF in generating high-fidelity and robust novel views that closely resemble reality.
Learnable Differencing Center for Nighttime Depth Perception
Jun 27, 2023
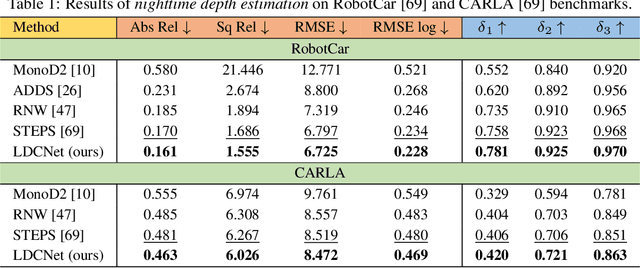
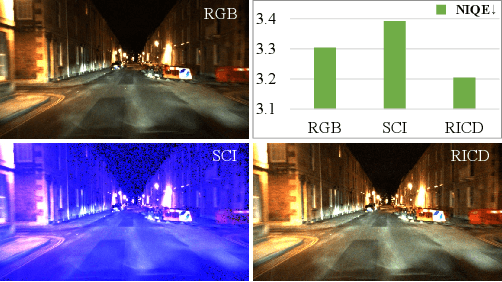

Depth completion is the task of recovering dense depth maps from sparse ones, usually with the help of color images. Existing image-guided methods perform well on daytime depth perception self-driving benchmarks, but struggle in nighttime scenarios with poor visibility and complex illumination. To address these challenges, we propose a simple yet effective framework called LDCNet. Our key idea is to use Recurrent Inter-Convolution Differencing (RICD) and Illumination-Affinitive Intra-Convolution Differencing (IAICD) to enhance the nighttime color images and reduce the negative effects of the varying illumination, respectively. RICD explicitly estimates global illumination by differencing two convolutions with different kernels, treating the small-kernel-convolution feature as the center of the large-kernel-convolution feature in a new perspective. IAICD softly alleviates local relative light intensity by differencing a single convolution, where the center is dynamically aggregated based on neighboring pixels and the estimated illumination map in RICD. On both nighttime depth completion and depth estimation tasks, extensive experiments demonstrate the effectiveness of our LDCNet, reaching the state of the art.
Variable Radiance Field for Real-Life Category-Specifc Reconstruction from Single Image
Jun 08, 2023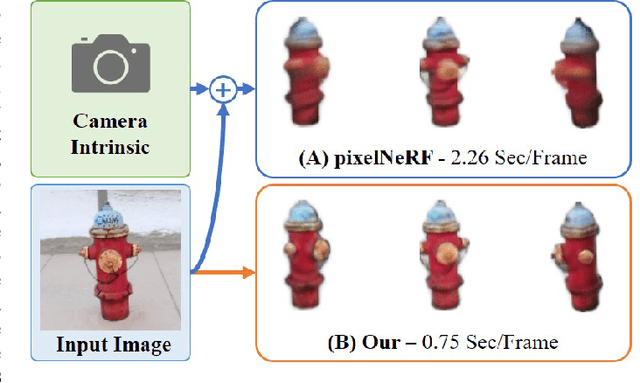


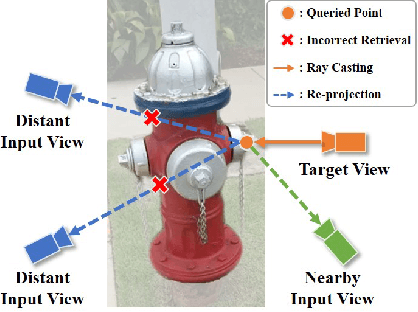
Reconstructing category-specific objects from a single image is a challenging task that requires inferring the geometry and appearance of an object from a limited viewpoint. Existing methods typically rely on local feature retrieval based on re-projection with known camera intrinsic, which are slow and prone to distortion at viewpoints distant from the input image. In this paper, we present Variable Radiance Field (VRF), a novel framework that can efficiently reconstruct category-specific objects from a single image without known camera parameters. Our key contributions are: (1) We parameterize the geometry and appearance of the object using a multi-scale global feature extractor, which avoids frequent point-wise feature retrieval and camera dependency. We also propose a contrastive learning-based pretraining strategy to improve the feature extractor. (2) We reduce the geometric complexity of the object by learning a category template, and use hypernetworks to generate a small neural radiance field for fast and instance-specific rendering. (3) We align each training instance to the template space using a learned similarity transformation, which enables semantic-consistent learning across different objects. We evaluate our method on the CO3D dataset and show that it outperforms existing methods in terms of quality and speed. We also demonstrate its applicability to shape interpolation and object placement tasks.
DesNet: Decomposed Scale-Consistent Network for Unsupervised Depth Completion
Nov 20, 2022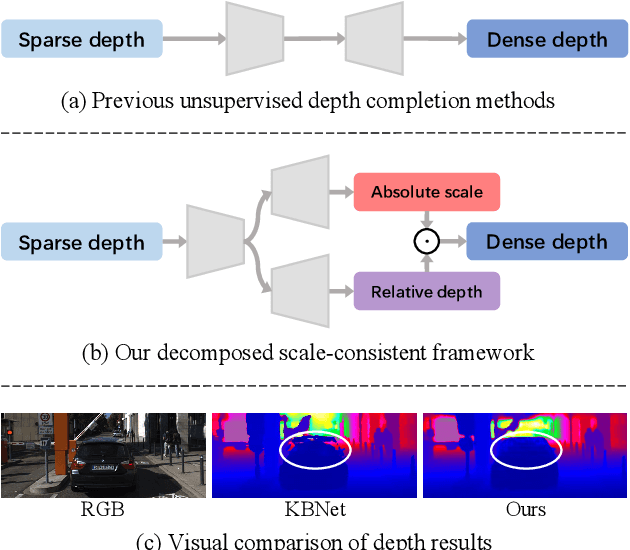
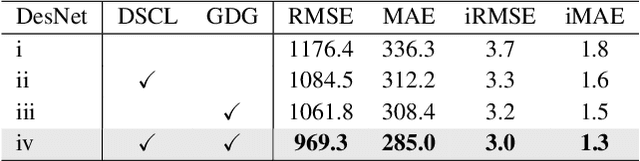

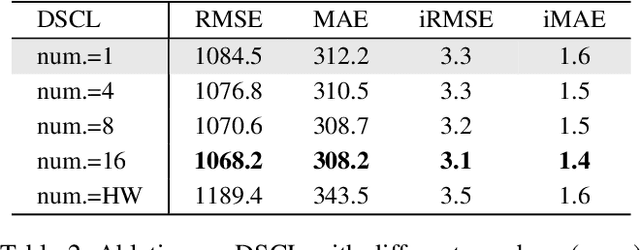
Unsupervised depth completion aims to recover dense depth from the sparse one without using the ground-truth annotation. Although depth measurement obtained from LiDAR is usually sparse, it contains valid and real distance information, i.e., scale-consistent absolute depth values. Meanwhile, scale-agnostic counterparts seek to estimate relative depth and have achieved impressive performance. To leverage both the inherent characteristics, we thus suggest to model scale-consistent depth upon unsupervised scale-agnostic frameworks. Specifically, we propose the decomposed scale-consistent learning (DSCL) strategy, which disintegrates the absolute depth into relative depth prediction and global scale estimation, contributing to individual learning benefits. But unfortunately, most existing unsupervised scale-agnostic frameworks heavily suffer from depth holes due to the extremely sparse depth input and weak supervised signal. To tackle this issue, we introduce the global depth guidance (GDG) module, which attentively propagates dense depth reference into the sparse target via novel dense-to-sparse attention. Extensive experiments show the superiority of our method on outdoor KITTI benchmark, ranking 1st and outperforming the best KBNet more than 12% in RMSE. In addition, our approach achieves state-of-the-art performance on indoor NYUv2 dataset.
Spacecraft depth completion based on the gray image and the sparse depth map
Aug 30, 2022
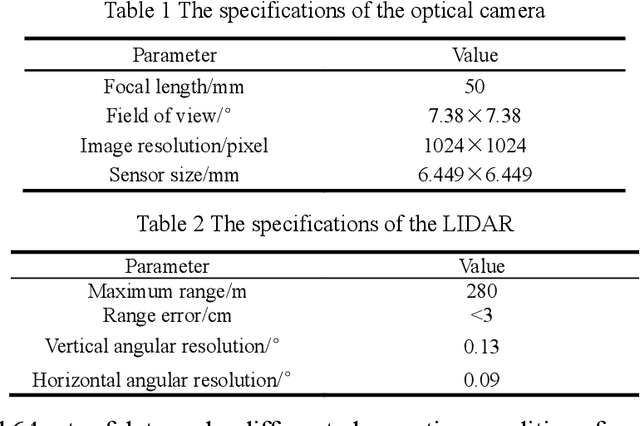

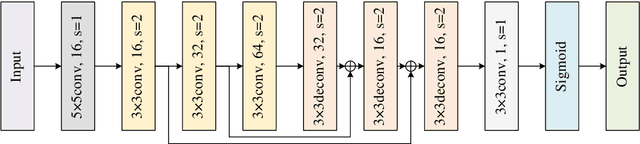
Perceiving the three-dimensional (3D) structure of the spacecraft is a prerequisite for successfully executing many on-orbit space missions, and it can provide critical input for many downstream vision algorithms. In this paper, we propose to sense the 3D structure of spacecraft using light detection and ranging sensor (LIDAR) and a monocular camera. To this end, Spacecraft Depth Completion Network (SDCNet) is proposed to recover the dense depth map based on gray image and sparse depth map. Specifically, SDCNet decomposes the object-level spacecraft depth completion task into foreground segmentation subtask and foreground depth completion subtask, which segments the spacecraft region first and then performs depth completion on the segmented foreground area. In this way, the background interference to foreground spacecraft depth completion is effectively avoided. Moreover, an attention-based feature fusion module is also proposed to aggregate the complementary information between different inputs, which deduces the correlation between different features along the channel and the spatial dimension sequentially. Besides, four metrics are also proposed to evaluate object-level depth completion performance, which can more intuitively reflect the quality of spacecraft depth completion results. Finally, a large-scale satellite depth completion dataset is constructed for training and testing spacecraft depth completion algorithms. Empirical experiments on the dataset demonstrate the effectiveness of the proposed SDCNet, which achieves 0.25m mean absolute error of interest and 0.759m mean absolute truncation error, surpassing state-of-the-art methods by a large margin. The spacecraft pose estimation experiment is also conducted based on the depth completion results, and the experimental results indicate that the predicted dense depth map could meet the needs of downstream vision tasks.
Multi-Modal Masked Pre-Training for Monocular Panoramic Depth Completion
Mar 23, 2022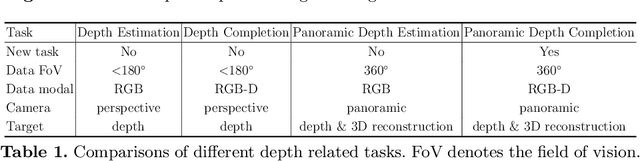


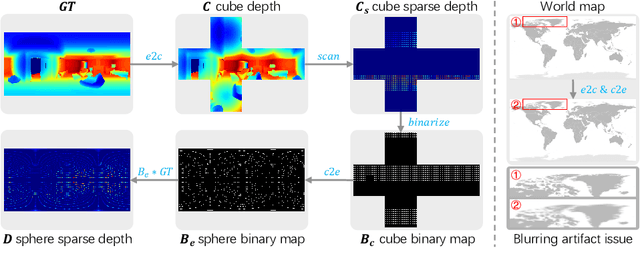
In this paper, we formulate a potentially valuable panoramic depth completion (PDC) task as panoramic 3D cameras often produce 360{\deg} depth with missing data in complex scenes. Its goal is to recover dense panoramic depths from raw sparse ones and panoramic RGB images. To deal with the PDC task, we train a deep network that takes both depth and image as inputs for the dense panoramic depth recovery. However, it needs to face a challenging optimization problem of the network parameters due to its non-convex objective function. To address this problem, we propose a simple yet effective approach termed M{^3}PT: multi-modal masked pre-training. Specifically, during pre-training, we simultaneously cover up patches of the panoramic RGB image and sparse depth by shared random mask, then reconstruct the sparse depth in the masked regions. To our best knowledge, it is the first time that we show the effectiveness of masked pre-training in a multi-modal vision task, instead of the single-modal task resolved by masked autoencoders (MAE). Different from MAE where fine-tuning completely discards the decoder part of pre-training, there is no architectural difference between the pre-training and fine-tuning stages in our M$^{3}$PT as they only differ in the prediction density, which potentially makes the transfer learning more convenient and effective. Extensive experiments verify the effectiveness of M{^3}PT on three panoramic datasets. Notably, we improve the state-of-the-art baselines by averagely 26.2% in RMSE, 51.7% in MRE, 49.7% in MAE, and 37.5% in RMSElog on three benchmark datasets. Codes and pre-trained models are available at https://github.com/anonymoustbd/MMMPT.