 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhong Liu
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Apr 06, 2024
Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Conversational Crowdsensing: A Parallel Intelligence Powered Novel Sensing Approach
Feb 04, 2024The transition from CPS-based Industry 4.0 to CPSS-based Industry 5.0 brings new requirements and opportunities to current sensing approaches, especially in light of recent progress in Chatbots and Large Language Models (LLMs). Therefore, the advancement of parallel intelligence-powered Crowdsensing Intelligence (CSI) is witnessed, which is currently advancing towards linguistic intelligence. In this paper, we propose a novel sensing paradigm, namely conversational crowdsensing, for Industry 5.0. It can alleviate workload and professional requirements of individuals and promote the organization and operation of diverse workforce, thereby facilitating faster response and wider popularization of crowdsensing systems. Specifically, we design the architecture of conversational crowdsensing to effectively organize three types of participants (biological, robotic, and digital) from diverse communities. Through three levels of effective conversation (i.e., inter-human, human-AI, and inter-AI), complex interactions and service functionalities of different workers can be achieved to accomplish various tasks across three sensing phases (i.e., requesting, scheduling, and executing). Moreover, we explore the foundational technologies for realizing conversational crowdsensing, encompassing LLM-based multi-agent systems, scenarios engineering and conversational human-AI cooperation. Finally, we present potential industrial applications of conversational crowdsensing and discuss its implications. We envision that conversations in natural language will become the primary communication channel during crowdsensing process, enabling richer information exchange and cooperative problem-solving among humans, robots, and AI.
Reconfigurable Intelligent Surface-Enabled Array Radar for Interference Mitigation
Jan 28, 2024Conventional active array radars often jointly design the transmit and receive beamforming for effectively suppressing interferences. To further promote the interference suppression performance, this paper introduces a reconfigurable intelligent surface (RIS) to assist the radar receiver because the RIS has the ability to bring plentiful additional degrees-of-freedom. To maximize the output signal-to-interference-plus-noise ratio (SINR) of receive array, we formulate the codesign of transmit beamforming and RIS-assisted receive beamforming into a nonconvex constrained fractional programming problem, and then propose an alternating minimization-based algorithm to jointly optimize the transmitor beamfmer, receive beamformer and RIS reflection coefficients. Concretely, we translate the RIS reflection coefficients design into a series of unimodular quadratic programming (UQP) subproblems by employing the Dinkelbach transform, and offer the closed-form optimal solutions of transmit and receive beamformers according to the minimum variance distortionless response principle. To tackle the UQP subproblems efficiently, we propose a second-order Riemannian Newton method (RNM) with improved Riemannian Newton direction, which avoids the line search and has better convergence speed than typical first-order Riemannian manifold optimization methods. Moreover, we derive the convergence of the proposed codesign algorithm by deducing the explicit convergence condition of RNM. We also analyze the computational complexity. Numerical results demonstrate that the proposed RIS-assisted array radar has superior performance of interference suppression to the RIS-free one, and the SINR improvement is proportional to the number of RIS elements.
Machine Learning for the Multi-Dimensional Bin Packing Problem: Literature Review and Empirical Evaluation
Dec 13, 2023The Bin Packing Problem (BPP) is a well-established combinatorial optimization (CO) problem. Since it has many applications in our daily life, e.g. logistics and resource allocation, people are seeking efficient bin packing algorithms. On the other hand, researchers have been making constant advances in machine learning (ML), which is famous for its efficiency. In this article, we first formulate BPP, introducing its variants and practical constraints. Then, a comprehensive survey on ML for multi-dimensional BPP is provided. We further collect some public benchmarks of 3D BPP, and evaluate some online methods on the Cutting Stock Dataset. Finally, we share our perspective on challenges and future directions in BPP. To the best of our knowledge, this is the first systematic review of ML-related methods for BPP.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023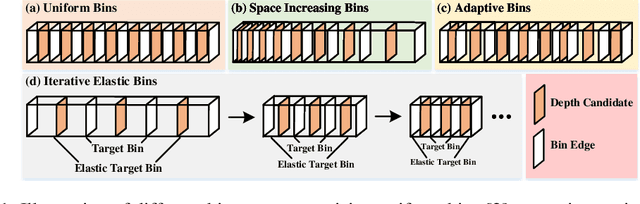
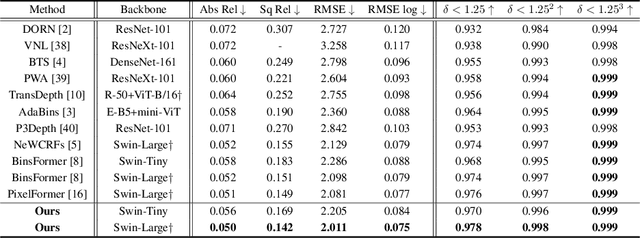
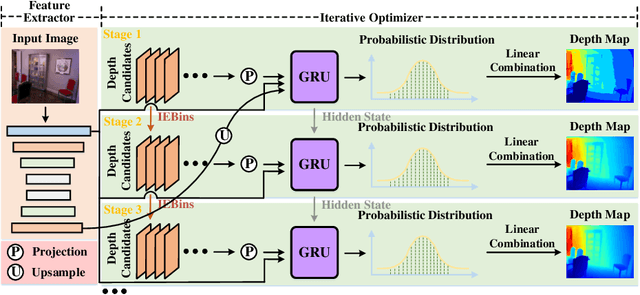

Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
The Expressive Power of Graph Neural Networks: A Survey
Aug 16, 2023

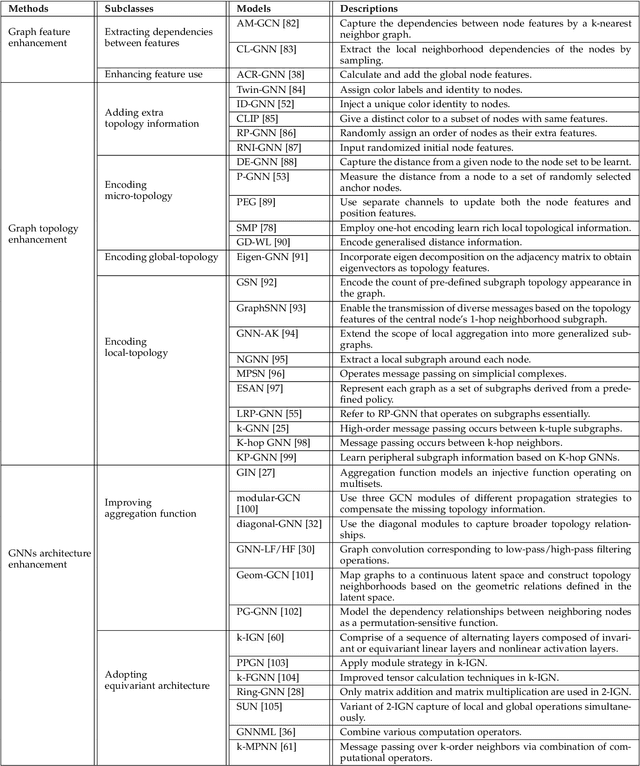
Graph neural networks (GNNs) are effective machine learning models for many graph-related applications. Despite their empirical success, many research efforts focus on the theoretical limitations of GNNs, i.e., the GNNs expressive power. Early works in this domain mainly focus on studying the graph isomorphism recognition ability of GNNs, and recent works try to leverage the properties such as subgraph counting and connectivity learning to characterize the expressive power of GNNs, which are more practical and closer to real-world. However, no survey papers and open-source repositories comprehensively summarize and discuss models in this important direction. To fill the gap, we conduct a first survey for models for enhancing expressive power under different forms of definition. Concretely, the models are reviewed based on three categories, i.e., Graph feature enhancement, Graph topology enhancement, and GNNs architecture enhancement.
Inductive Meta-path Learning for Schema-complex Heterogeneous Information Networks
Jul 08, 2023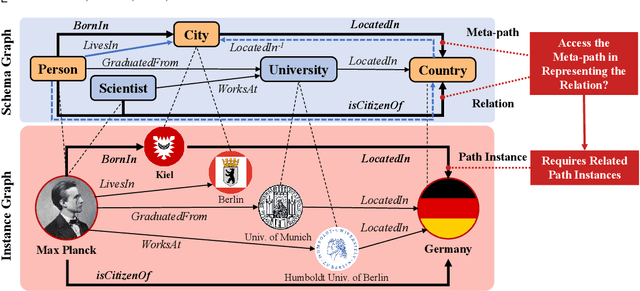
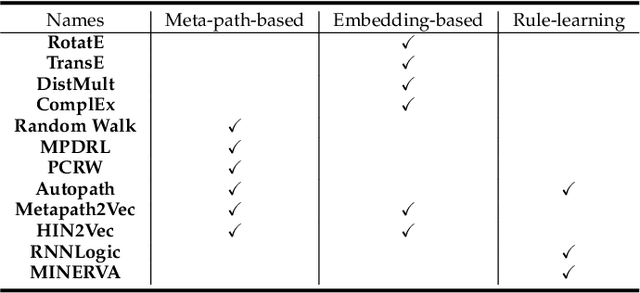
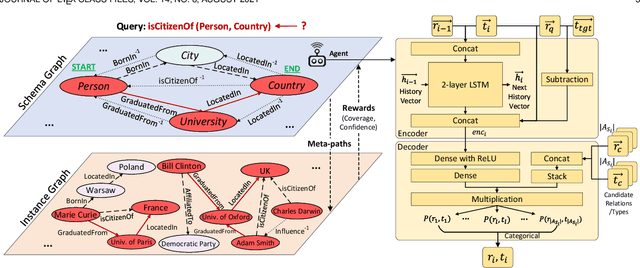
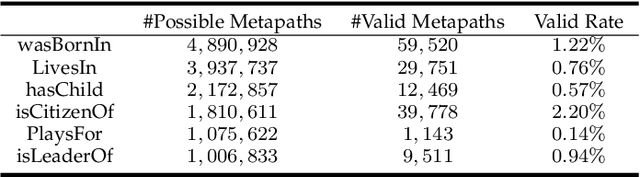
Heterogeneous Information Networks (HINs) are information networks with multiple types of nodes and edges. The concept of meta-path, i.e., a sequence of entity types and relation types connecting two entities, is proposed to provide the meta-level explainable semantics for various HIN tasks. Traditionally, meta-paths are primarily used for schema-simple HINs, e.g., bibliographic networks with only a few entity types, where meta-paths are often enumerated with domain knowledge. However, the adoption of meta-paths for schema-complex HINs, such as knowledge bases (KBs) with hundreds of entity and relation types, has been limited due to the computational complexity associated with meta-path enumeration. Additionally, effectively assessing meta-paths requires enumerating relevant path instances, which adds further complexity to the meta-path learning process. To address these challenges, we propose SchemaWalk, an inductive meta-path learning framework for schema-complex HINs. We represent meta-paths with schema-level representations to support the learning of the scores of meta-paths for varying relations, mitigating the need of exhaustive path instance enumeration for each relation. Further, we design a reinforcement-learning based path-finding agent, which directly navigates the network schema (i.e., schema graph) to learn policies for establishing meta-paths with high coverage and confidence for multiple relations. Extensive experiments on real data sets demonstrate the effectiveness of our proposed paradigm.
Online Unsupervised Video Object Segmentation via Contrastive Motion Clustering
Jun 21, 2023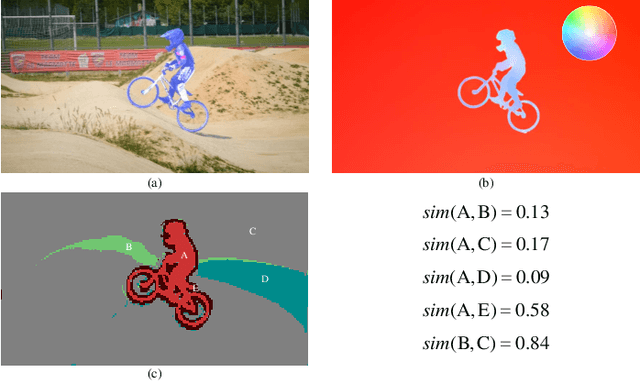
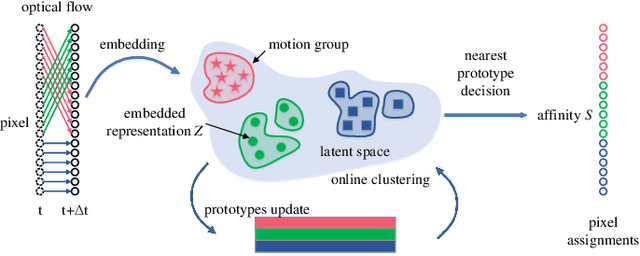
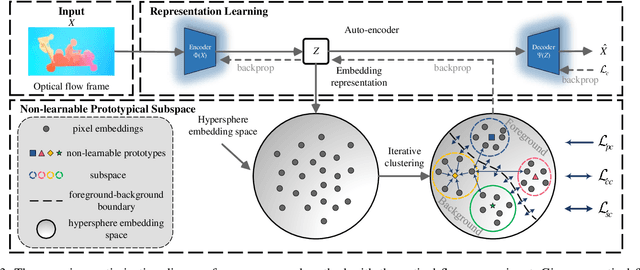
Online unsupervised video object segmentation (UVOS) uses the previous frames as its input to automatically separate the primary object(s) from a streaming video without using any further manual annotation. A major challenge is that the model has no access to the future and must rely solely on the history, i.e., the segmentation mask is predicted from the current frame as soon as it is captured. In this work, a novel contrastive motion clustering algorithm with an optical flow as its input is proposed for the online UVOS by exploiting the common fate principle that visual elements tend to be perceived as a group if they possess the same motion pattern. We build a simple and effective auto-encoder to iteratively summarize non-learnable prototypical bases for the motion pattern, while the bases in turn help learn the representation of the embedding network. Further, a contrastive learning strategy based on a boundary prior is developed to improve foreground and background feature discrimination in the representation learning stage. The proposed algorithm can be optimized on arbitrarily-scale data i.e., frame, clip, dataset) and performed in an online fashion. Experiments on $\textit{DAVIS}_{\textit{16}}$, $\textit{FBMS}$, and $\textit{SegTrackV2}$ datasets show that the accuracy of our method surpasses the previous state-of-the-art (SoTA) online UVOS method by a margin of 0.8%, 2.9%, and 1.1%, respectively. Furthermore, by using an online deep subspace clustering to tackle the motion grouping, our method is able to achieve higher accuracy at $3\times$ faster inference time compared to SoTA online UVOS method, and making a good trade-off between effectiveness and efficiency.
Self-Supervised Monocular Depth Estimation with Self-Reference Distillation and Disparity Offset Refinement
Feb 20, 2023
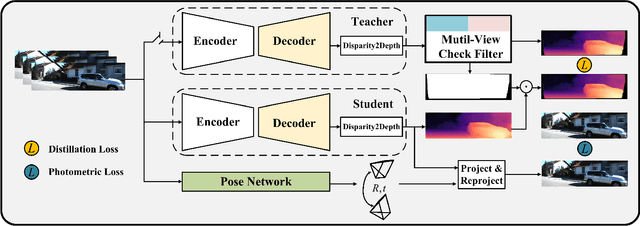
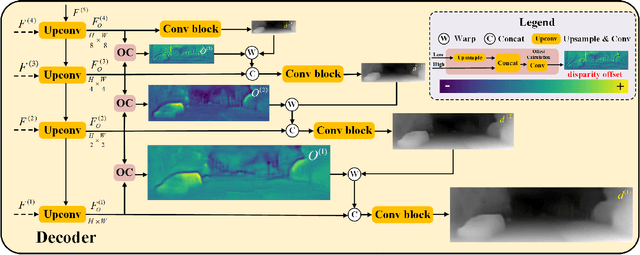
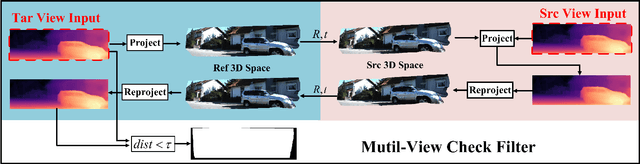
Monocular depth estimation plays a fundamental role in computer vision. Due to the costly acquisition of depth ground truth, self-supervised methods that leverage adjacent frames to establish a supervisory signal have emerged as the most promising paradigms. In this work, we propose two novel ideas to improve self-supervised monocular depth estimation: 1) self-reference distillation and 2) disparity offset refinement. Specifically, we use a parameter-optimized model as the teacher updated as the training epochs to provide additional supervision during the training process. The teacher model has the same structure as the student model, with weights inherited from the historical student model. In addition, a multiview check is introduced to filter out the outliers produced by the teacher model. Furthermore, we leverage the contextual consistency between high-scale and low-scale features to obtain multiscale disparity offsets, which are used to refine the disparity output incrementally by aligning disparity information at different scales. The experimental results on the KITTI and Make3D datasets show that our method outperforms previous state-of-the-art competitors.
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023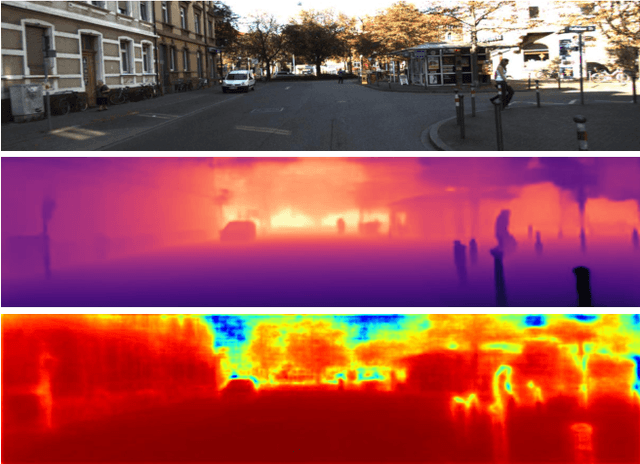
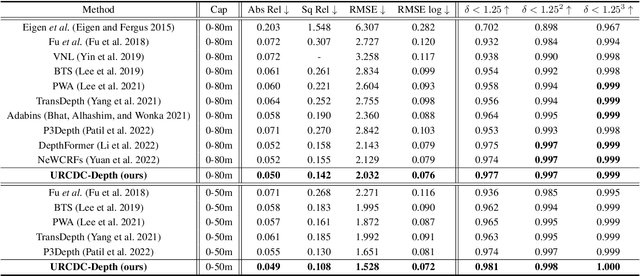
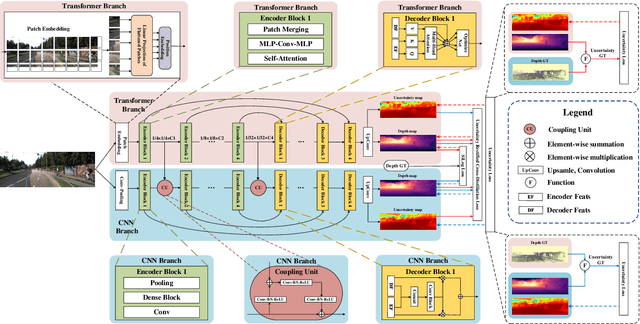
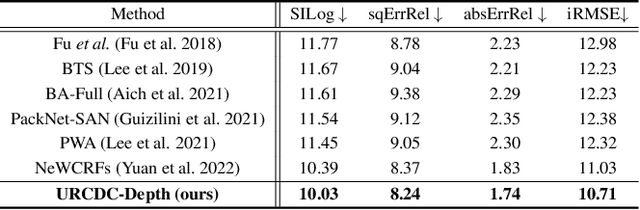
This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.