 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongwang Zhang
Loss Jump During Loss Switch in Solving PDEs with Neural Networks
May 06, 2024
Using neural networks to solve partial differential equations (PDEs) is gaining popularity as an alternative approach in the scientific computing community. Neural networks can integrate different types of information into the loss function. These include observation data, governing equations, and variational forms, etc. These loss functions can be broadly categorized into two types: observation data loss directly constrains and measures the model output, while other loss functions indirectly model the performance of the network, which can be classified as model loss. However, this alternative approach lacks a thorough understanding of its underlying mechanisms, including theoretical foundations and rigorous characterization of various phenomena. This work focuses on investigating how different loss functions impact the training of neural networks for solving PDEs. We discover a stable loss-jump phenomenon: when switching the loss function from the data loss to the model loss, which includes different orders of derivative information, the neural network solution significantly deviates from the exact solution immediately. Further experiments reveal that this phenomenon arises from the different frequency preferences of neural networks under different loss functions. We theoretically analyze the frequency preference of neural networks under model loss. This loss-jump phenomenon provides a valuable perspective for examining the underlying mechanisms of neural networks in solving PDEs.
Anchor function: a type of benchmark functions for studying language models
Jan 16, 2024Understanding transformer-based language models is becoming increasingly crucial, particularly as they play pivotal roles in advancing towards artificial general intelligence. However, language model research faces significant challenges, especially for academic research groups with constrained resources. These challenges include complex data structures, unknown target functions, high computational costs and memory requirements, and a lack of interpretability in the inference process, etc. Drawing a parallel to the use of simple models in scientific research, we propose the concept of an anchor function. This is a type of benchmark function designed for studying language models in learning tasks that follow an "anchor-key" pattern. By utilizing the concept of an anchor function, we can construct a series of functions to simulate various language tasks. The anchor function plays a role analogous to that of mice in diabetes research, particularly suitable for academic research. We demonstrate the utility of the anchor function with an example, revealing two basic operations by attention structures in language models: shifting tokens and broadcasting one token from one position to many positions. These operations are also commonly observed in large language models. The anchor function framework, therefore, opens up a series of valuable and accessible research questions for further exploration, especially for theoretical study.
Optimistic Estimate Uncovers the Potential of Nonlinear Models
Jul 18, 2023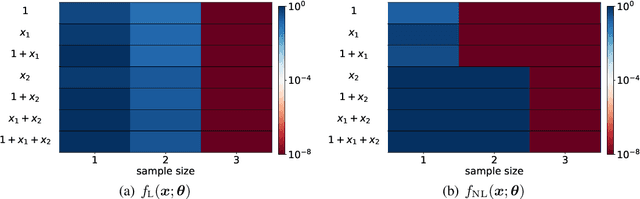
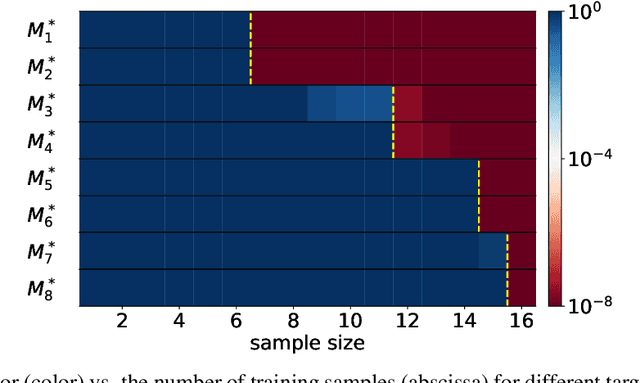
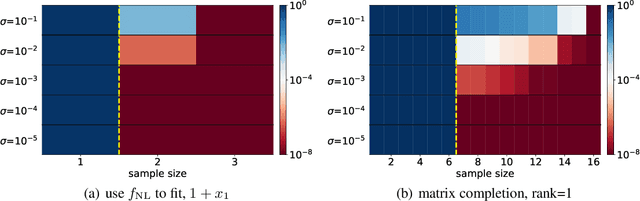

We propose an optimistic estimate to evaluate the best possible fitting performance of nonlinear models. It yields an optimistic sample size that quantifies the smallest possible sample size to fit/recover a target function using a nonlinear model. We estimate the optimistic sample sizes for matrix factorization models, deep models, and deep neural networks (DNNs) with fully-connected or convolutional architecture. For each nonlinear model, our estimates predict a specific subset of targets that can be fitted at overparameterization, which are confirmed by our experiments. Our optimistic estimate reveals two special properties of the DNN models -- free expressiveness in width and costly expressiveness in connection. These properties suggest the following architecture design principles of DNNs: (i) feel free to add neurons/kernels; (ii) restrain from connecting neurons. Overall, our optimistic estimate theoretically unveils the vast potential of nonlinear models in fitting at overparameterization. Based on this framework, we anticipate gaining a deeper understanding of how and why numerous nonlinear models such as DNNs can effectively realize their potential in practice in the near future.
Stochastic Modified Equations and Dynamics of Dropout Algorithm
May 25, 2023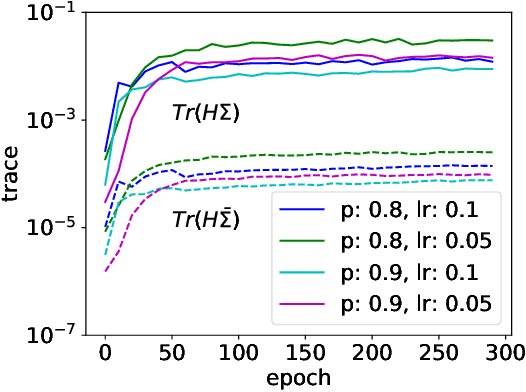
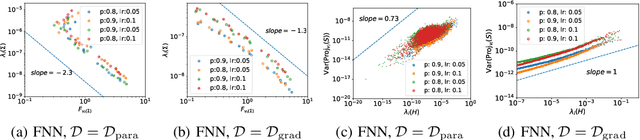
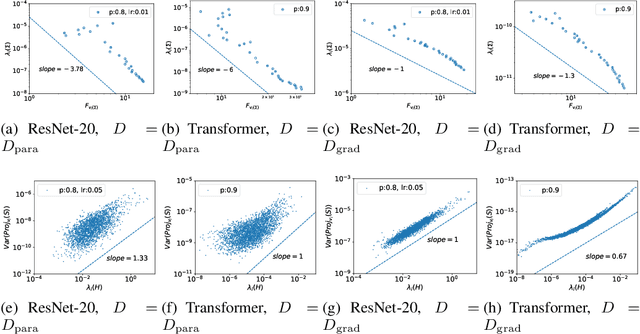
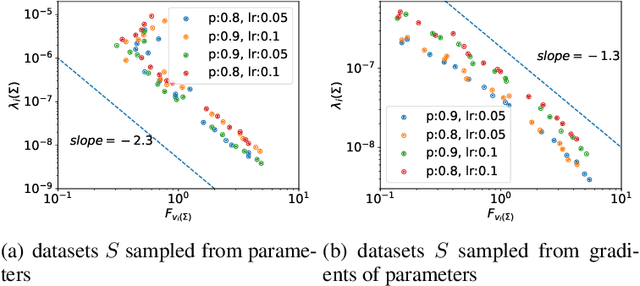
Dropout is a widely utilized regularization technique in the training of neural networks, nevertheless, its underlying mechanism and its impact on achieving good generalization abilities remain poorly understood. In this work, we derive the stochastic modified equations for analyzing the dynamics of dropout, where its discrete iteration process is approximated by a class of stochastic differential equations. In order to investigate the underlying mechanism by which dropout facilitates the identification of flatter minima, we study the noise structure of the derived stochastic modified equation for dropout. By drawing upon the structural resemblance between the Hessian and covariance through several intuitive approximations, we empirically demonstrate the universal presence of the inverse variance-flatness relation and the Hessian-variance relation, throughout the training process of dropout. These theoretical and empirical findings make a substantial contribution to our understanding of the inherent tendency of dropout to locate flatter minima.
Loss Spike in Training Neural Networks
May 20, 2023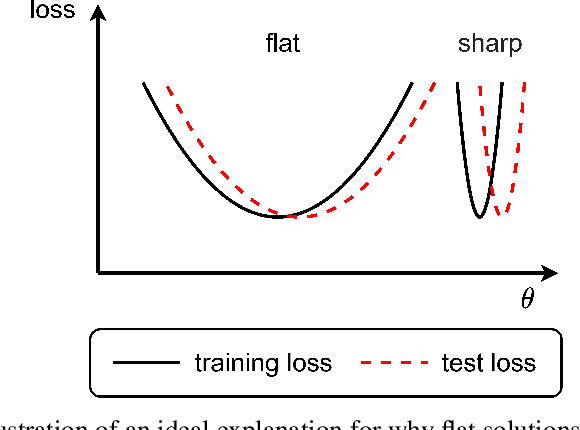
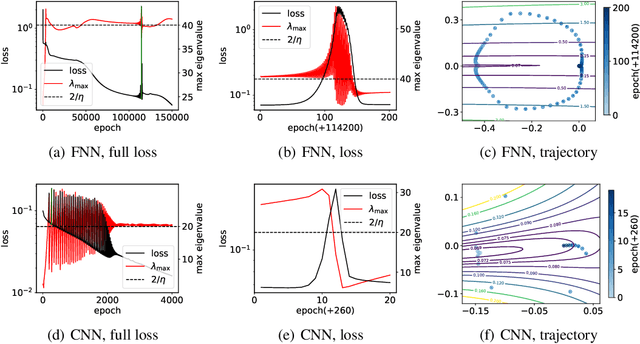

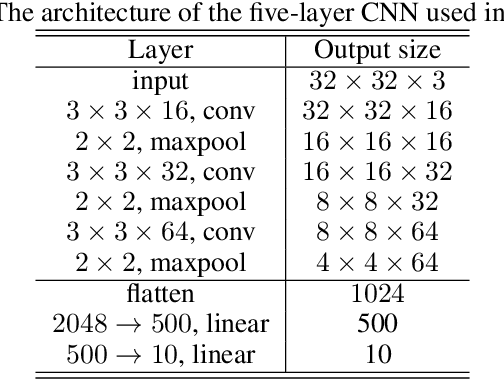
In this work, we study the mechanism underlying loss spikes observed during neural network training. When the training enters a region, which has a smaller-loss-as-sharper (SLAS) structure, the training becomes unstable and loss exponentially increases once it is too sharp, i.e., the rapid ascent of the loss spike. The training becomes stable when it finds a flat region. The deviation in the first eigen direction (with maximum eigenvalue of the loss Hessian ($\lambda_{\mathrm{max}}$) is found to be dominated by low-frequency. Since low-frequency is captured very fast (frequency principle), the rapid descent is then observed. Inspired by our analysis of loss spikes, we revisit the link between $\lambda_{\mathrm{max}}$ flatness and generalization. For real datasets, low-frequency is often dominant and well-captured by both the training data and the test data. Then, a solution with good generalization and a solution with bad generalization can both learn low-frequency well, thus, they have little difference in the sharpest direction. Therefore, although $\lambda_{\mathrm{max}}$ can indicate the sharpness of the loss landscape, deviation in its corresponding eigen direction is not responsible for the generalization difference. We also find that loss spikes can facilitate condensation, i.e., input weights evolve towards the same, which may be the underlying mechanism for why the loss spike improves generalization, rather than simply controlling the value of $\lambda_{\mathrm{max}}$.
Linear Stability Hypothesis and Rank Stratification for Nonlinear Models
Nov 21, 2022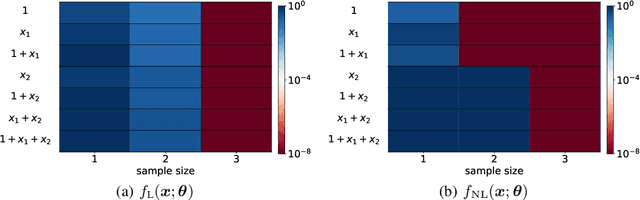


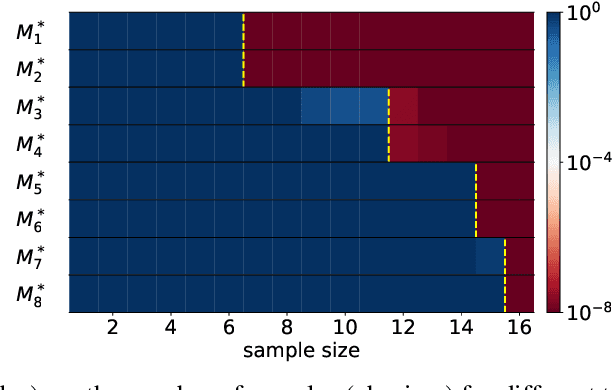
Models with nonlinear architectures/parameterizations such as deep neural networks (DNNs) are well known for their mysteriously good generalization performance at overparameterization. In this work, we tackle this mystery from a novel perspective focusing on the transition of the target recovery/fitting accuracy as a function of the training data size. We propose a rank stratification for general nonlinear models to uncover a model rank as an "effective size of parameters" for each function in the function space of the corresponding model. Moreover, we establish a linear stability theory proving that a target function almost surely becomes linearly stable when the training data size equals its model rank. Supported by our experiments, we propose a linear stability hypothesis that linearly stable functions are preferred by nonlinear training. By these results, model rank of a target function predicts a minimal training data size for its successful recovery. Specifically for the matrix factorization model and DNNs of fully-connected or convolutional architectures, our rank stratification shows that the model rank for specific target functions can be much lower than the size of model parameters. This result predicts the target recovery capability even at heavy overparameterization for these nonlinear models as demonstrated quantitatively by our experiments. Overall, our work provides a unified framework with quantitative prediction power to understand the mysterious target recovery behavior at overparameterization for general nonlinear models.
Implicit regularization of dropout
Jul 13, 2022

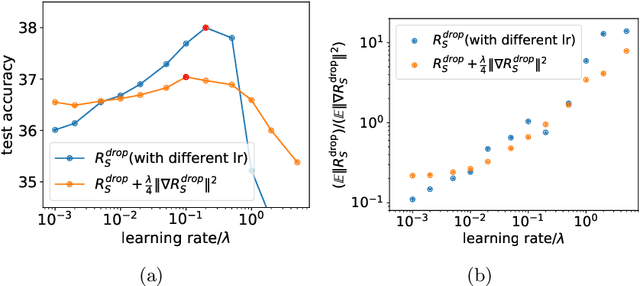

It is important to understand how the popular regularization method dropout helps the neural network training find a good generalization solution. In this work, we theoretically derive the implicit regularization of dropout and study the relation between the Hessian matrix of the loss function and the covariance matrix of the dropout noise, supported by a series of experiments. We then numerically study two implications of the implicit regularization of dropout, which intuitively rationalize why dropout helps generalization. First, we find that the training with dropout finds the neural network with a flatter minimum compared with standard gradient descent training in experiments, and the implicit regularization is the key for finding flat solutions. Second, trained with dropout, input weights of hidden neurons (the input weight of a hidden neuron consists of the weight from its input layer to the hidden neuron and its bias term) would tend to condense on isolated orientations. Condensation is a feature in non-linear learning process, which makes the neural network low complexity. Although our theory mainly focuses on the dropout used in the last hidden layer, our experiments apply for general dropout in training neural networks. This work points out the distinct characteristics of dropout compared with stochastic gradient descent and serves as an important basis for fully understanding dropout.
Embedding Principle: a hierarchical structure of loss landscape of deep neural networks
Nov 30, 2021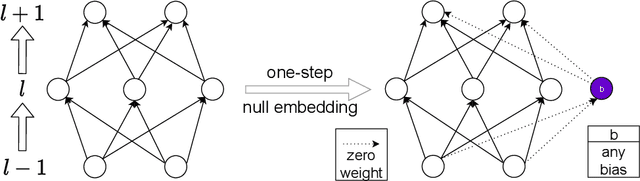


We prove a general Embedding Principle of loss landscape of deep neural networks (NNs) that unravels a hierarchical structure of the loss landscape of NNs, i.e., loss landscape of an NN contains all critical points of all the narrower NNs. This result is obtained by constructing a class of critical embeddings which map any critical point of a narrower NN to a critical point of the target NN with the same output function. By discovering a wide class of general compatible critical embeddings, we provide a gross estimate of the dimension of critical submanifolds embedded from critical points of narrower NNs. We further prove an irreversiblility property of any critical embedding that the number of negative/zero/positive eigenvalues of the Hessian matrix of a critical point may increase but never decrease as an NN becomes wider through the embedding. Using a special realization of general compatible critical embedding, we prove a stringent necessary condition for being a "truly-bad" critical point that never becomes a strict-saddle point through any critical embedding. This result implies the commonplace of strict-saddle points in wide NNs, which may be an important reason underlying the easy optimization of wide NNs widely observed in practice.
A variance principle explains why dropout finds flatter minima
Nov 01, 2021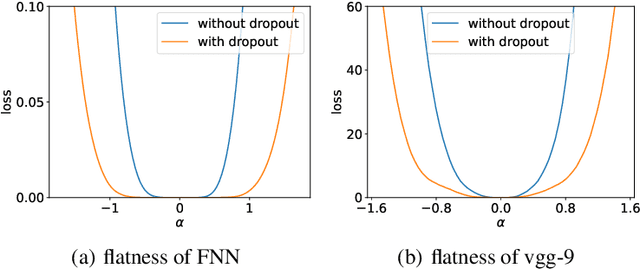
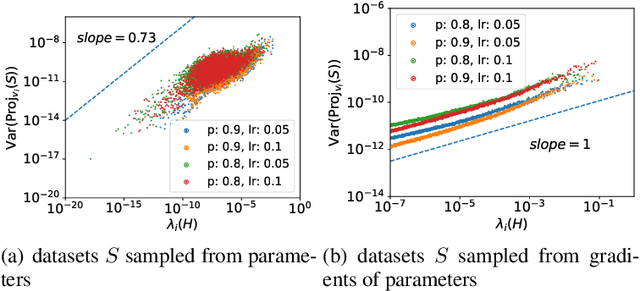
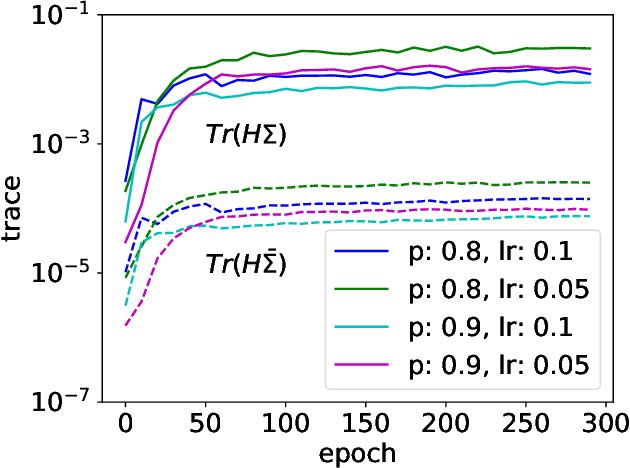
Although dropout has achieved great success in deep learning, little is known about how it helps the training find a good generalization solution in the high-dimensional parameter space. In this work, we show that the training with dropout finds the neural network with a flatter minimum compared with standard gradient descent training. We further study the underlying mechanism of why dropout finds flatter minima through experiments. We propose a {\it Variance Principle} that the variance of a noise is larger at the sharper direction of the loss landscape. Existing works show that SGD satisfies the variance principle, which leads the training to flatter minima. Our work show that the noise induced by the dropout also satisfies the variance principle that explains why dropout finds flatter minima. In general, our work points out that the variance principle is an important similarity between dropout and SGD that lead the training to find flatter minima and obtain good generalization.
Embedding Principle of Loss Landscape of Deep Neural Networks
May 30, 2021
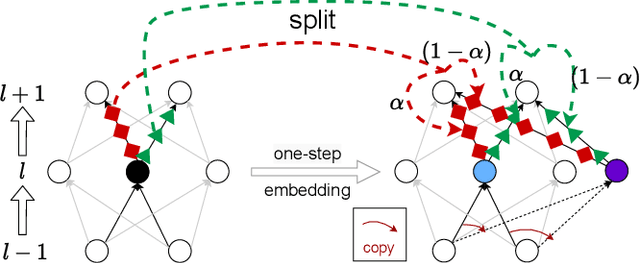
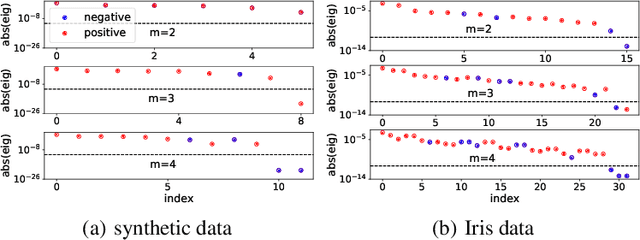

Understanding the structure of loss landscape of deep neural networks (DNNs)is obviously important. In this work, we prove an embedding principle that the loss landscape of a DNN "contains" all the critical points of all the narrower DNNs. More precisely, we propose a critical embedding such that any critical point, e.g., local or global minima, of a narrower DNN can be embedded to a critical point/hyperplane of the target DNN with higher degeneracy and preserving the DNN output function. The embedding structure of critical points is independent of loss function and training data, showing a stark difference from other nonconvex problems such as protein-folding. Empirically, we find that a wide DNN is often attracted by highly-degenerate critical points that are embedded from narrow DNNs. The embedding principle provides an explanation for the general easy optimization of wide DNNs and unravels a potential implicit low-complexity regularization during the training. Overall, our work provides a skeleton for the study of loss landscape of DNNs and its implication, by which a more exact and comprehensive understanding can be anticipated in the near