 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongwei Qiu
Bridging the Semantic-Numerical Gap: A Numerical Reasoning Method of Cross-modal Knowledge Graph for Material Property Prediction
Dec 15, 2023
Using machine learning (ML) techniques to predict material properties is a crucial research topic. These properties depend on numerical data and semantic factors. Due to the limitations of small-sample datasets, existing methods typically adopt ML algorithms to regress numerical properties or transfer other pre-trained knowledge graphs (KGs) to the material. However, these methods cannot simultaneously handle semantic and numerical information. In this paper, we propose a numerical reasoning method for material KGs (NR-KG), which constructs a cross-modal KG using semantic nodes and numerical proxy nodes. It captures both types of information by projecting KG into a canonical KG and utilizes a graph neural network to predict material properties. In this process, a novel projection prediction loss is proposed to extract semantic features from numerical information. NR-KG facilitates end-to-end processing of cross-modal data, mining relationships and cross-modal information in small-sample datasets, and fully utilizes valuable experimental data to enhance material prediction. We further propose two new High-Entropy Alloys (HEA) property datasets with semantic descriptions. NR-KG outperforms state-of-the-art (SOTA) methods, achieving relative improvements of 25.9% and 16.1% on two material datasets. Besides, NR-KG surpasses SOTA methods on two public physical chemistry molecular datasets, showing improvements of 22.2% and 54.3%, highlighting its potential application and generalizability. We hope the proposed datasets, algorithms, and pre-trained models can facilitate the communities of KG and AI for materials.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023
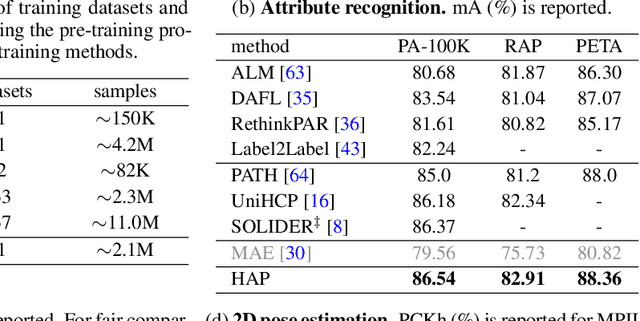
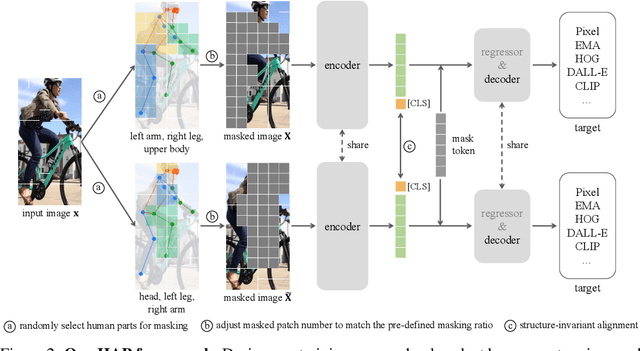

Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
MM-NeRF: Multimodal-Guided 3D Multi-Style Transfer of Neural Radiance Field
Sep 24, 2023
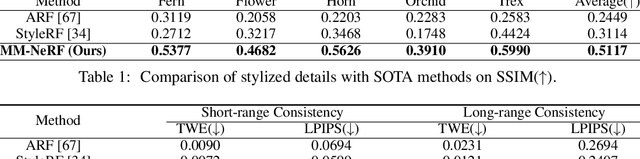
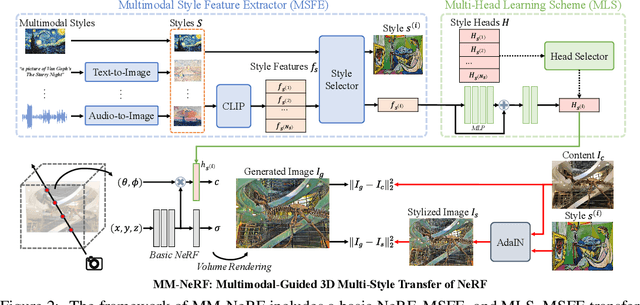
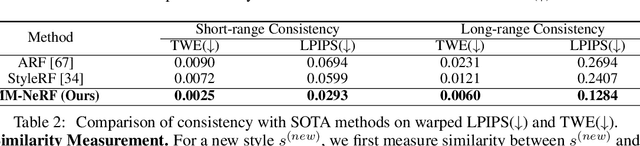
3D style transfer aims to render stylized novel views of 3D scenes with the specified style, which requires high-quality rendering and keeping multi-view consistency. Benefiting from the ability of 3D representation from Neural Radiance Field (NeRF), existing methods learn the stylized NeRF by giving a reference style from an image. However, they suffer the challenges of high-quality stylization with texture details for multi-style transfer and stylization with multimodal guidance. In this paper, we reveal that the same objects in 3D scenes show various states (color tone, details, etc.) from different views after stylization since previous methods optimized by single-view image-based style loss functions, leading NeRF to tend to smooth texture details, further resulting in low-quality rendering. To tackle these problems, we propose a novel Multimodal-guided 3D Multi-style transfer of NeRF, termed MM-NeRF, which achieves high-quality 3D multi-style rendering with texture details and can be driven by multimodal-style guidance. First, MM-NeRF adopts a unified framework to project multimodal guidance into CLIP space and extracts multimodal style features to guide the multi-style stylization. To relieve the problem of lacking details, we propose a novel Multi-Head Learning Scheme (MLS), in which each style head predicts the parameters of the color head of NeRF. MLS decomposes the learning difficulty caused by the inconsistency of multi-style transfer and improves the quality of stylization. In addition, the MLS can generalize pre-trained MM-NeRF to any new styles by adding heads with small training costs (a few minutes). Extensive experiments on three real-world 3D scene datasets show that MM-NeRF achieves high-quality 3D multi-style stylization with multimodal guidance, keeps multi-view consistency, and keeps semantic consistency of multimodal style guidance. Codes will be released later.
Learning Structure-Guided Diffusion Model for 2D Human Pose Estimation
Jun 29, 2023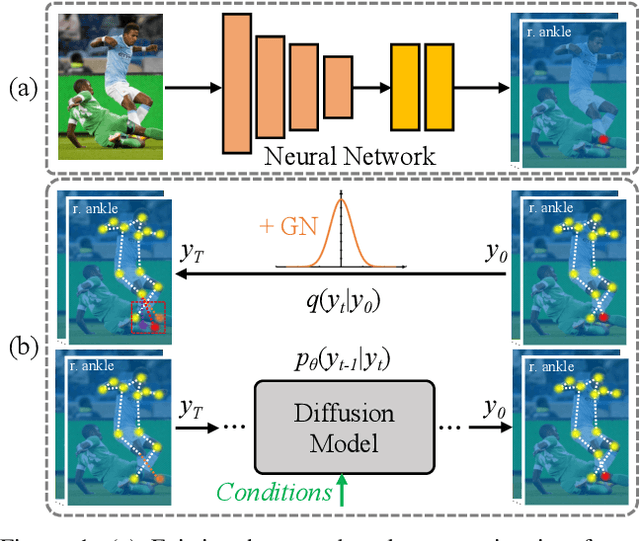

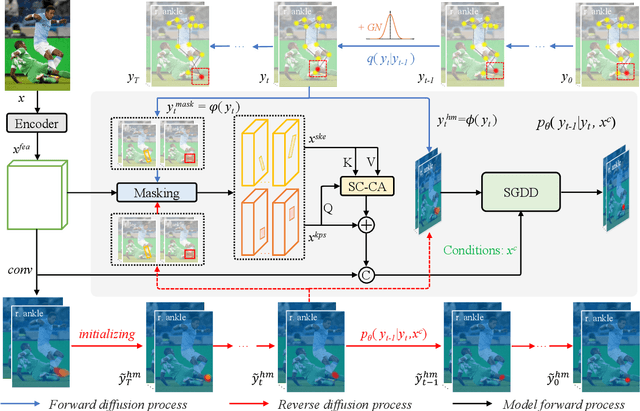
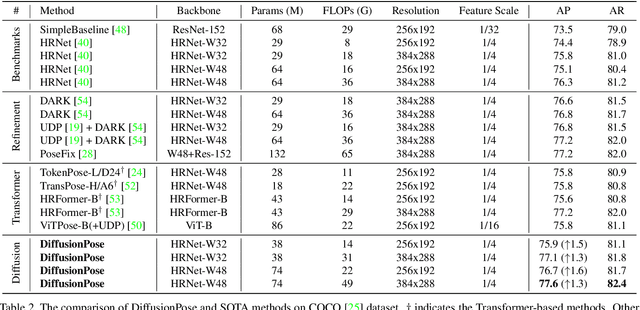
One of the mainstream schemes for 2D human pose estimation (HPE) is learning keypoints heatmaps by a neural network. Existing methods typically improve the quality of heatmaps by customized architectures, such as high-resolution representation and vision Transformers. In this paper, we propose \textbf{DiffusionPose}, a new scheme that formulates 2D HPE as a keypoints heatmaps generation problem from noised heatmaps. During training, the keypoints are diffused to random distribution by adding noises and the diffusion model learns to recover ground-truth heatmaps from noised heatmaps with respect to conditions constructed by image feature. During inference, the diffusion model generates heatmaps from initialized heatmaps in a progressive denoising way. Moreover, we further explore improving the performance of DiffusionPose with conditions from human structural information. Extensive experiments show the prowess of our DiffusionPose, with improvements of 1.6, 1.2, and 1.2 mAP on widely-used COCO, CrowdPose, and AI Challenge datasets, respectively.
Stable Diffusion is Unstable
Jun 06, 2023



Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.
PSVT: End-to-End Multi-person 3D Pose and Shape Estimation with Progressive Video Transformers
Mar 16, 2023



Existing methods of multi-person video 3D human Pose and Shape Estimation (PSE) typically adopt a two-stage strategy, which first detects human instances in each frame and then performs single-person PSE with temporal model. However, the global spatio-temporal context among spatial instances can not be captured. In this paper, we propose a new end-to-end multi-person 3D Pose and Shape estimation framework with progressive Video Transformer, termed PSVT. In PSVT, a spatio-temporal encoder (STE) captures the global feature dependencies among spatial objects. Then, spatio-temporal pose decoder (STPD) and shape decoder (STSD) capture the global dependencies between pose queries and feature tokens, shape queries and feature tokens, respectively. To handle the variances of objects as time proceeds, a novel scheme of progressive decoding is used to update pose and shape queries at each frame. Besides, we propose a novel pose-guided attention (PGA) for shape decoder to better predict shape parameters. The two components strengthen the decoder of PSVT to improve performance. Extensive experiments on the four datasets show that PSVT achieves stage-of-the-art results.
Learning Spatiotemporal Frequency-Transformer for Low-Quality Video Super-Resolution
Dec 27, 2022



Video Super-Resolution (VSR) aims to restore high-resolution (HR) videos from low-resolution (LR) videos. Existing VSR techniques usually recover HR frames by extracting pertinent textures from nearby frames with known degradation processes. Despite significant progress, grand challenges are remained to effectively extract and transmit high-quality textures from high-degraded low-quality sequences, such as blur, additive noises, and compression artifacts. In this work, a novel Frequency-Transformer (FTVSR) is proposed for handling low-quality videos that carry out self-attention in a combined space-time-frequency domain. First, video frames are split into patches and each patch is transformed into spectral maps in which each channel represents a frequency band. It permits a fine-grained self-attention on each frequency band, so that real visual texture can be distinguished from artifacts. Second, a novel dual frequency attention (DFA) mechanism is proposed to capture the global frequency relations and local frequency relations, which can handle different complicated degradation processes in real-world scenarios. Third, we explore different self-attention schemes for video processing in the frequency domain and discover that a ``divided attention'' which conducts a joint space-frequency attention before applying temporal-frequency attention, leads to the best video enhancement quality. Extensive experiments on three widely-used VSR datasets show that FTVSR outperforms state-of-the-art methods on different low-quality videos with clear visual margins. Code and pre-trained models are available at https://github.com/researchmm/FTVSR.
Weakly-supervised Pre-training for 3D Human Pose Estimation via Perspective Knowledge
Nov 22, 2022



Modern deep learning-based 3D pose estimation approaches require plenty of 3D pose annotations. However, existing 3D datasets lack diversity, which limits the performance of current methods and their generalization ability. Although existing methods utilize 2D pose annotations to help 3D pose estimation, they mainly focus on extracting 2D structural constraints from 2D poses, ignoring the 3D information hidden in the images. In this paper, we propose a novel method to extract weak 3D information directly from 2D images without 3D pose supervision. Firstly, we utilize 2D pose annotations and perspective prior knowledge to generate the relationship of that keypoint is closer or farther from the camera, called relative depth. We collect a 2D pose dataset (MCPC) and generate relative depth labels. Based on MCPC, we propose a weakly-supervised pre-training (WSP) strategy to distinguish the depth relationship between two points in an image. WSP enables the learning of the relative depth of two keypoints on lots of in-the-wild images, which is more capable of predicting depth and generalization ability for 3D human pose estimation. After fine-tuning on 3D pose datasets, WSP achieves state-of-the-art results on two widely-used benchmarks.
Dynamic Graph Reasoning for Multi-person 3D Pose Estimation
Aug 06, 2022



Multi-person 3D pose estimation is a challenging task because of occlusion and depth ambiguity, especially in the cases of crowd scenes. To solve these problems, most existing methods explore modeling body context cues by enhancing feature representation with graph neural networks or adding structural constraints. However, these methods are not robust for their single-root formulation that decoding 3D poses from a root node with a pre-defined graph. In this paper, we propose GR-M3D, which models the \textbf{M}ulti-person \textbf{3D} pose estimation with dynamic \textbf{G}raph \textbf{R}easoning. The decoding graph in GR-M3D is predicted instead of pre-defined. In particular, It firstly generates several data maps and enhances them with a scale and depth aware refinement module (SDAR). Then multiple root keypoints and dense decoding paths for each person are estimated from these data maps. Based on them, dynamic decoding graphs are built by assigning path weights to the decoding paths, while the path weights are inferred from those enhanced data maps. And this process is named dynamic graph reasoning (DGR). Finally, the 3D poses are decoded according to dynamic decoding graphs for each detected person. GR-M3D can adjust the structure of the decoding graph implicitly by adopting soft path weights according to input data, which makes the decoding graphs be adaptive to different input persons to the best extent and more capable of handling occlusion and depth ambiguity than previous methods. We empirically show that the proposed bottom-up approach even outperforms top-down methods and achieves state-of-the-art results on three 3D pose datasets.
IVT: An End-to-End Instance-guided Video Transformer for 3D Pose Estimation
Aug 06, 2022



Video 3D human pose estimation aims to localize the 3D coordinates of human joints from videos. Recent transformer-based approaches focus on capturing the spatiotemporal information from sequential 2D poses, which cannot model the contextual depth feature effectively since the visual depth features are lost in the step of 2D pose estimation. In this paper, we simplify the paradigm into an end-to-end framework, Instance-guided Video Transformer (IVT), which enables learning spatiotemporal contextual depth information from visual features effectively and predicts 3D poses directly from video frames. In particular, we firstly formulate video frames as a series of instance-guided tokens and each token is in charge of predicting the 3D pose of a human instance. These tokens contain body structure information since they are extracted by the guidance of joint offsets from the human center to the corresponding body joints. Then, these tokens are sent into IVT for learning spatiotemporal contextual depth. In addition, we propose a cross-scale instance-guided attention mechanism to handle the variational scales among multiple persons. Finally, the 3D poses of each person are decoded from instance-guided tokens by coordinate regression. Experiments on three widely-used 3D pose estimation benchmarks show that the proposed IVT achieves state-of-the-art performances.