 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhuo Zheng
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024

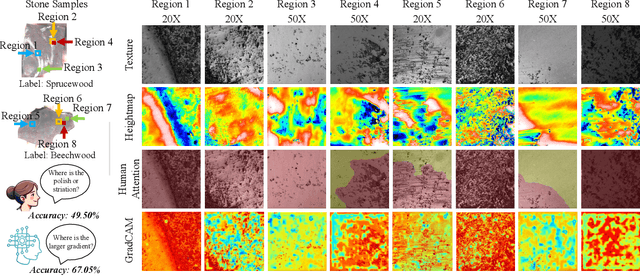
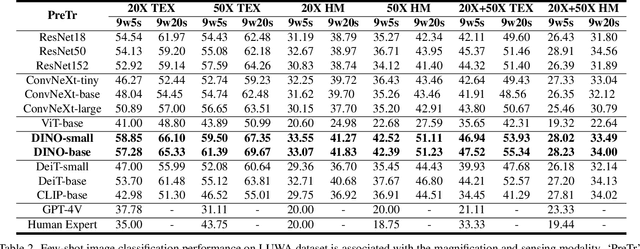
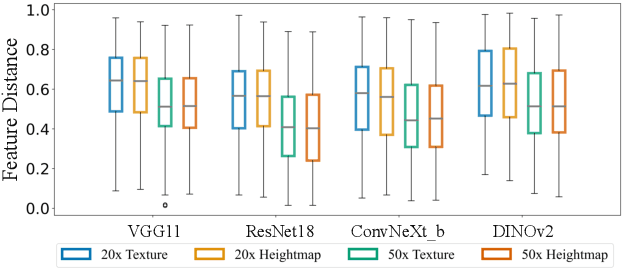
Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
Segment Any Change
Feb 02, 2024Visual foundation models have achieved remarkable results in zero-shot image classification and segmentation, but zero-shot change detection remains an open problem. In this paper, we propose the segment any change models (AnyChange), a new type of change detection model that supports zero-shot prediction and generalization on unseen change types and data distributions. AnyChange is built on the segment anything model (SAM) via our training-free adaptation method, bitemporal latent matching. By revealing and exploiting intra-image and inter-image semantic similarities in SAM's latent space, bitemporal latent matching endows SAM with zero-shot change detection capabilities in a training-free way. We also propose a point query mechanism to enable AnyChange's zero-shot object-centric change detection capability. We perform extensive experiments to confirm the effectiveness of AnyChange for zero-shot change detection. AnyChange sets a new record on the SECOND benchmark for unsupervised change detection, exceeding the previous SOTA by up to 4.4% F$_1$ score, and achieving comparable accuracy with negligible manual annotations (1 pixel per image) for supervised change detection.
MapChange: Enhancing Semantic Change Detection with Temporal-Invariant Historical Maps Based on Deep Triplet Network
Jan 21, 2024Semantic Change Detection (SCD) is recognized as both a crucial and challenging task in the field of image analysis. Traditional methods for SCD have predominantly relied on the comparison of image pairs. However, this approach is significantly hindered by substantial imaging differences, which arise due to variations in shooting times, atmospheric conditions, and angles. Such discrepancies lead to two primary issues: the under-detection of minor yet significant changes, and the generation of false alarms due to temporal variances. These factors often result in unchanged objects appearing markedly different in multi-temporal images. In response to these challenges, the MapChange framework has been developed. This framework introduces a novel paradigm that synergizes temporal-invariant historical map data with contemporary high-resolution images. By employing this combination, the temporal variance inherent in conventional image pair comparisons is effectively mitigated. The efficacy of the MapChange framework has been empirically validated through comprehensive testing on two public datasets. These tests have demonstrated the framework's marked superiority over existing state-of-the-art SCD methods.
EarthVQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering
Dec 19, 2023Earth vision research typically focuses on extracting geospatial object locations and categories but neglects the exploration of relations between objects and comprehensive reasoning. Based on city planning needs, we develop a multi-modal multi-task VQA dataset (EarthVQA) to advance relational reasoning-based judging, counting, and comprehensive analysis. The EarthVQA dataset contains 6000 images, corresponding semantic masks, and 208,593 QA pairs with urban and rural governance requirements embedded. As objects are the basis for complex relational reasoning, we propose a Semantic OBject Awareness framework (SOBA) to advance VQA in an object-centric way. To preserve refined spatial locations and semantics, SOBA leverages a segmentation network for object semantics generation. The object-guided attention aggregates object interior features via pseudo masks, and bidirectional cross-attention further models object external relations hierarchically. To optimize object counting, we propose a numerical difference loss that dynamically adds difference penalties, unifying the classification and regression tasks. Experimental results show that SOBA outperforms both advanced general and remote sensing methods. We believe this dataset and framework provide a strong benchmark for Earth vision's complex analysis. The project page is at https://Junjue-Wang.github.io/homepage/EarthVQA.
Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process
Sep 29, 2023Understanding the temporal dynamics of Earth's surface is a mission of multi-temporal remote sensing image analysis, significantly promoted by deep vision models with its fuel -- labeled multi-temporal images. However, collecting, preprocessing, and annotating multi-temporal remote sensing images at scale is non-trivial since it is expensive and knowledge-intensive. In this paper, we present a scalable multi-temporal remote sensing change data generator via generative modeling, which is cheap and automatic, alleviating these problems. Our main idea is to simulate a stochastic change process over time. We consider the stochastic change process as a probabilistic semantic state transition, namely generative probabilistic change model (GPCM), which decouples the complex simulation problem into two more trackable sub-problems, \ie, change event simulation and semantic change synthesis. To solve these two problems, we present the change generator (Changen), a GAN-based GPCM, enabling controllable object change data generation, including customizable object property, and change event. The extensive experiments suggest that our Changen has superior generation capability, and the change detectors with Changen pre-training exhibit excellent transferability to real-world change datasets.
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation
Oct 24, 2021



Deep learning approaches have shown promising results in remote sensing high spatial resolution (HSR) land-cover mapping. However, urban and rural scenes can show completely different geographical landscapes, and the inadequate generalizability of these algorithms hinders city-level or national-level mapping. Most of the existing HSR land-cover datasets mainly promote the research of learning semantic representation, thereby ignoring the model transferability. In this paper, we introduce the Land-cOVEr Domain Adaptive semantic segmentation (LoveDA) dataset to advance semantic and transferable learning. The LoveDA dataset contains 5987 HSR images with 166768 annotated objects from three different cities. Compared to the existing datasets, the LoveDA dataset encompasses two domains (urban and rural), which brings considerable challenges due to the: 1) multi-scale objects; 2) complex background samples; and 3) inconsistent class distributions. The LoveDA dataset is suitable for both land-cover semantic segmentation and unsupervised domain adaptation (UDA) tasks. Accordingly, we benchmarked the LoveDA dataset on eleven semantic segmentation methods and eight UDA methods. Some exploratory studies including multi-scale architectures and strategies, additional background supervision, and pseudo-label analysis were also carried out to address these challenges. The code and data are available at https://github.com/Junjue-Wang/LoveDA.
Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery
Aug 16, 2021



For high spatial resolution (HSR) remote sensing images, bitemporal supervised learning always dominates change detection using many pairwise labeled bitemporal images. However, it is very expensive and time-consuming to pairwise label large-scale bitemporal HSR remote sensing images. In this paper, we propose single-temporal supervised learning (STAR) for change detection from a new perspective of exploiting object changes in unpaired images as supervisory signals. STAR enables us to train a high-accuracy change detector only using \textbf{unpaired} labeled images and generalize to real-world bitemporal images. To evaluate the effectiveness of STAR, we design a simple yet effective change detector called ChangeStar, which can reuse any deep semantic segmentation architecture by the ChangeMixin module. The comprehensive experimental results show that ChangeStar outperforms the baseline with a large margin under single-temporal supervision and achieves superior performance under bitemporal supervision. Code is available at https://github.com/Z-Zheng/ChangeStar
A Spectral-Spatial-Dependent Global Learning Framework for Insufficient and Imbalanced Hyperspectral Image Classification
May 29, 2021



Deep learning techniques have been widely applied to hyperspectral image (HSI) classification and have achieved great success. However, the deep neural network model has a large parameter space and requires a large number of labeled data. Deep learning methods for HSI classification usually follow a patchwise learning framework. Recently, a fast patch-free global learning (FPGA) architecture was proposed for HSI classification according to global spatial context information. However, FPGA has difficulty extracting the most discriminative features when the sample data is imbalanced. In this paper, a spectral-spatial dependent global learning (SSDGL) framework based on global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) is proposed for insufficient and imbalanced HSI classification. In SSDGL, the hierarchically balanced (H-B) sampling strategy and the weighted softmax loss are proposed to address the imbalanced sample problem. To effectively distinguish similar spectral characteristics of land cover types, the GCL module is introduced to extract the long short-term dependency of spectral features. To learn the most discriminative feature representations, the GJAM module is proposed to extract attention areas. The experimental results obtained with three public HSI datasets show that the SSDGL has powerful performance in insufficient and imbalanced sample problems and is superior to other state-of-the-art methods. Code can be obtained at: https://github.com/dengweihuan/SSDGL.
Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery
Nov 19, 2020



Geospatial object segmentation, as a particular semantic segmentation task, always faces with larger-scale variation, larger intra-class variance of background, and foreground-background imbalance in the high spatial resolution (HSR) remote sensing imagery. However, general semantic segmentation methods mainly focus on scale variation in the natural scene, with inadequate consideration of the other two problems that usually happen in the large area earth observation scene. In this paper, we argue that the problems lie on the lack of foreground modeling and propose a foreground-aware relation network (FarSeg) from the perspectives of relation-based and optimization-based foreground modeling, to alleviate the above two problems. From perspective of relation, FarSeg enhances the discrimination of foreground features via foreground-correlated contexts associated by learning foreground-scene relation. Meanwhile, from perspective of optimization, a foreground-aware optimization is proposed to focus on foreground examples and hard examples of background during training for a balanced optimization. The experimental results obtained using a large scale dataset suggest that the proposed method is superior to the state-of-the-art general semantic segmentation methods and achieves a better trade-off between speed and accuracy. Code has been made available at: \url{https://github.com/Z-Zheng/FarSeg}.
FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
Nov 11, 2020



Deep learning techniques have provided significant improvements in hyperspectral image (HSI) classification. The current deep learning based HSI classifiers follow a patch-based learning framework by dividing the image into overlapping patches. As such, these methods are local learning methods, which have a high computational cost. In this paper, a fast patch-free global learning (FPGA) framework is proposed for HSI classification. In FPGA, an encoder-decoder based FCN is utilized to consider the global spatial information by processing the whole image, which results in fast inference. However, it is difficult to directly utilize the encoder-decoder based FCN for HSI classification as it always fails to converge due to the insufficiently diverse gradients caused by the limited training samples. To solve the divergence problem and maintain the abilities of FCN of fast inference and global spatial information mining, a global stochastic stratified sampling strategy is first proposed by transforming all the training samples into a stochastic sequence of stratified samples. This strategy can obtain diverse gradients to guarantee the convergence of the FCN in the FPGA framework. For a better design of FCN architecture, FreeNet, which is a fully end-to-end network for HSI classification, is proposed to maximize the exploitation of the global spatial information and boost the performance via a spectral attention based encoder and a lightweight decoder. A lateral connection module is also designed to connect the encoder and decoder, fusing the spatial details in the encoder and the semantic features in the decoder. The experimental results obtained using three public benchmark datasets suggest that the FPGA framework is superior to the patch-based framework in both speed and accuracy for HSI classification. Code has been made available at: https://github.com/Z-Zheng/FreeNet.