 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihan Liu
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Apr 07, 2024
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation
Feb 27, 2024We present SongComposer, an innovative LLM designed for song composition. It could understand and generate melodies and lyrics in symbolic song representations, by leveraging the capability of LLM. Existing music-related LLM treated the music as quantized audio signals, while such implicit encoding leads to inefficient encoding and poor flexibility. In contrast, we resort to symbolic song representation, the mature and efficient way humans designed for music, and enable LLM to explicitly compose songs like humans. In practice, we design a novel tuple design to format lyric and three note attributes (pitch, duration, and rest duration) in the melody, which guarantees the correct LLM understanding of musical symbols and realizes precise alignment between lyrics and melody. To impart basic music understanding to LLM, we carefully collected SongCompose-PT, a large-scale song pretraining dataset that includes lyrics, melodies, and paired lyrics-melodies in either Chinese or English. After adequate pre-training, 10K carefully crafted QA pairs are used to empower the LLM with the instruction-following capability and solve diverse tasks. With extensive experiments, SongComposer demonstrates superior performance in lyric-to-melody generation, melody-to-lyric generation, song continuation, and text-to-song creation, outperforming advanced LLMs like GPT-4.
Understanding Public Perceptions of AI Conversational Agents: A Cross-Cultural Analysis
Feb 25, 2024Conversational Agents (CAs) have increasingly been integrated into everyday life, sparking significant discussions on social media. While previous research has examined public perceptions of AI in general, there is a notable lack in research focused on CAs, with fewer investigations into cultural variations in CA perceptions. To address this gap, this study used computational methods to analyze about one million social media discussions surrounding CAs and compared people's discourses and perceptions of CAs in the US and China. We find Chinese participants tended to view CAs hedonically, perceived voice-based and physically embodied CAs as warmer and more competent, and generally expressed positive emotions. In contrast, US participants saw CAs more functionally, with an ambivalent attitude. Warm perception was a key driver of positive emotions toward CAs in both countries. We discussed practical implications for designing contextually sensitive and user-centric CAs to resonate with various users' preferences and needs.
* 17 pages, 4 figures, 7 tables
FGBERT: Function-Driven Pre-trained Gene Language Model for Metagenomics
Feb 24, 2024Metagenomic data, comprising mixed multi-species genomes, are prevalent in diverse environments like oceans and soils, significantly impacting human health and ecological functions. However, current research relies on K-mer representations, limiting the capture of structurally relevant gene contexts. To address these limitations and further our understanding of complex relationships between metagenomic sequences and their functions, we introduce a protein-based gene representation as a context-aware and structure-relevant tokenizer. Our approach includes Masked Gene Modeling (MGM) for gene group-level pre-training, providing insights into inter-gene contextual information, and Triple Enhanced Metagenomic Contrastive Learning (TEM-CL) for gene-level pre-training to model gene sequence-function relationships. MGM and TEM-CL constitute our novel metagenomic language model {\NAME}, pre-trained on 100 million metagenomic sequences. We demonstrate the superiority of our proposed {\NAME} on eight datasets.
ChatQA: Building GPT-4 Level Conversational QA Models
Jan 23, 2024In this work, we introduce ChatQA, a family of conversational question answering (QA) models that obtain GPT-4 level accuracies. Specifically, we propose a two-stage instruction tuning method that can significantly improve the zero-shot conversational QA results from large language models (LLMs). To handle retrieval-augmented generation in conversational QA, we fine-tune a dense retriever on a multi-turn QA dataset, which provides comparable results to using the state-of-the-art query rewriting model while largely reducing deployment cost. Notably, our ChatQA-70B can outperform GPT-4 in terms of average score on 10 conversational QA datasets (54.14 vs. 53.90), without relying on any synthetic data from OpenAI GPT models.
SUT: Active Defects Probing for Transcompiler Models
Oct 22, 2023Automatic Program translation has enormous application value and hence has been attracting significant interest from AI researchers. However, we observe that current program translation models still make elementary syntax errors, particularly, when the target language does not have syntax elements in the source language. Metrics like BLUE, CodeBLUE and computation accuracy may not expose these issues. In this paper we introduce a new metrics for programming language translation and these metrics address these basic syntax errors. We develop a novel active defects probing suite called Syntactic Unit Tests (SUT) which includes a highly interpretable evaluation harness for accuracy and test scoring. Experiments have shown that even powerful models like ChatGPT still make mistakes on these basic unit tests. Specifically, compared to previous program translation task evaluation dataset, its pass rate on our unit tests has decreased by 26.15%. Further our evaluation harness reveal syntactic element errors in which these models exhibit deficiencies.
Protein 3D Graph Structure Learning for Robust Structure-based Protein Property Prediction
Oct 19, 2023



Protein structure-based property prediction has emerged as a promising approach for various biological tasks, such as protein function prediction and sub-cellular location estimation. The existing methods highly rely on experimental protein structure data and fail in scenarios where these data are unavailable. Predicted protein structures from AI tools (e.g., AlphaFold2) were utilized as alternatives. However, we observed that current practices, which simply employ accurately predicted structures during inference, suffer from notable degradation in prediction accuracy. While similar phenomena have been extensively studied in general fields (e.g., Computer Vision) as model robustness, their impact on protein property prediction remains unexplored. In this paper, we first investigate the reason behind the performance decrease when utilizing predicted structures, attributing it to the structure embedding bias from the perspective of structure representation learning. To study this problem, we identify a Protein 3D Graph Structure Learning Problem for Robust Protein Property Prediction (PGSL-RP3), collect benchmark datasets, and present a protein Structure embedding Alignment Optimization framework (SAO) to mitigate the problem of structure embedding bias between the predicted and experimental protein structures. Extensive experiments have shown that our framework is model-agnostic and effective in improving the property prediction of both predicted structures and experimental structures. The benchmark datasets and codes will be released to benefit the community.
Co-modeling the Sequential and Graphical Routes for Peptide Representation Learning
Oct 05, 2023


Peptides are formed by the dehydration condensation of multiple amino acids. The primary structure of a peptide can be represented either as an amino acid sequence or as a molecular graph consisting of atoms and chemical bonds. Previous studies have indicated that deep learning routes specific to sequential and graphical peptide forms exhibit comparable performance on downstream tasks. Despite the fact that these models learn representations of the same modality of peptides, we find that they explain their predictions differently. Considering sequential and graphical models as two experts making inferences from different perspectives, we work on fusing expert knowledge to enrich the learned representations for improving the discriminative performance. To achieve this, we propose a peptide co-modeling method, RepCon, which employs a contrastive learning-based framework to enhance the mutual information of representations from decoupled sequential and graphical end-to-end models. It considers representations from the sequential encoder and the graphical encoder for the same peptide sample as a positive pair and learns to enhance the consistency of representations between positive sample pairs and to repel representations between negative pairs. Empirical studies of RepCon and other co-modeling methods are conducted on open-source discriminative datasets, including aggregation propensity, retention time, antimicrobial peptide prediction, and family classification from Peptide Database. Our results demonstrate the superiority of the co-modeling approach over independent modeling, as well as the superiority of RepCon over other methods under the co-modeling framework. In addition, the attribution on RepCon further corroborates the validity of the approach at the level of model explanation.
Retrieval meets Long Context Large Language Models
Oct 04, 2023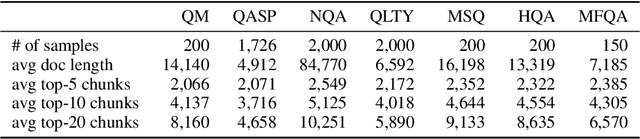
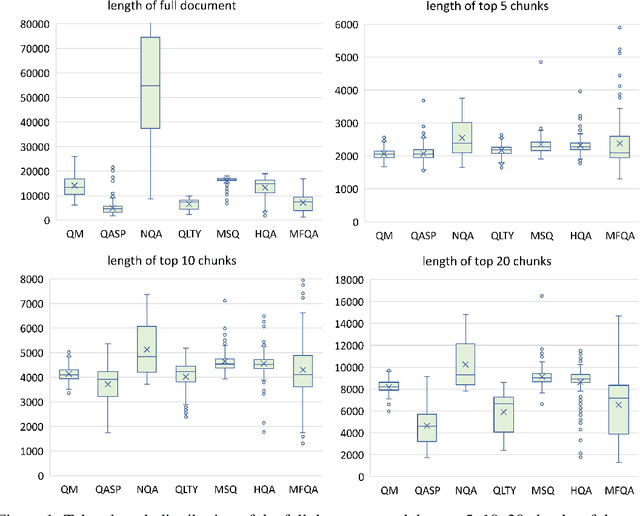
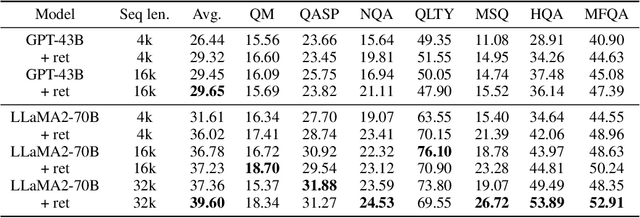
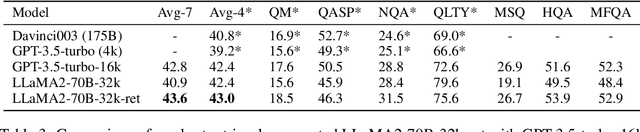
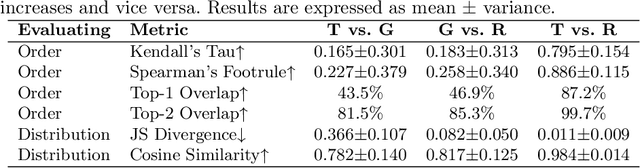
Extending the context window of large language models (LLMs) is getting popular recently, while the solution of augmenting LLMs with retrieval has existed for years. The natural questions are: i) Retrieval-augmentation versus long context window, which one is better for downstream tasks? ii) Can both methods be combined to get the best of both worlds? In this work, we answer these questions by studying both solutions using two state-of-the-art pretrained LLMs, i.e., a proprietary 43B GPT and LLaMA2-70B. Perhaps surprisingly, we find that LLM with 4K context window using simple retrieval-augmentation at generation can achieve comparable performance to finetuned LLM with 16K context window via positional interpolation on long context tasks, while taking much less computation. More importantly, we demonstrate that retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes. Our best model, retrieval-augmented LLaMA2-70B with 32K context window, outperforms GPT-3.5-turbo-16k and Davinci003 in terms of average score on seven long context tasks including question answering and query-based summarization. It also outperforms its non-retrieval LLaMA2-70B-32k baseline by a margin, while being much faster at generation. Our study provides general insights on the choice of retrieval-augmentation versus long context extension of LLM for practitioners.
Only 5\% Attention Is All You Need: Efficient Long-range Document-level Neural Machine Translation
Sep 25, 2023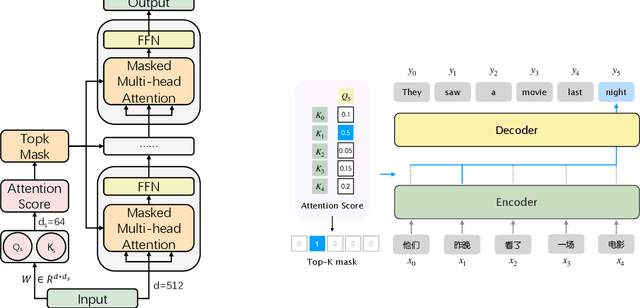
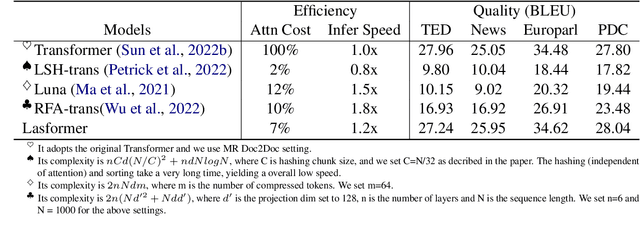
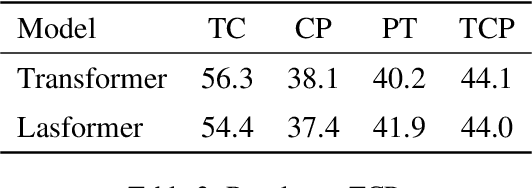
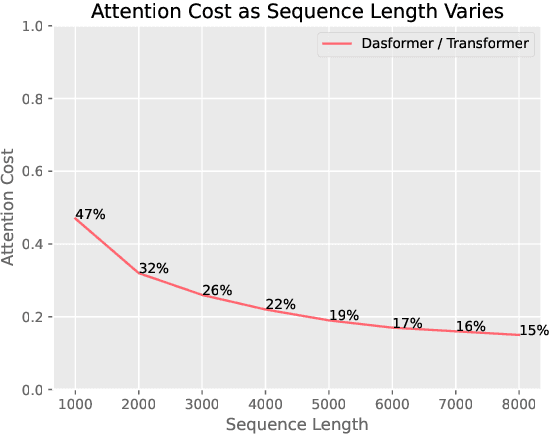
Document-level Neural Machine Translation (DocNMT) has been proven crucial for handling discourse phenomena by introducing document-level context information. One of the most important directions is to input the whole document directly to the standard Transformer model. In this case, efficiency becomes a critical concern due to the quadratic complexity of the attention module. Existing studies either focus on the encoder part, which cannot be deployed on sequence-to-sequence generation tasks, e.g., Machine Translation (MT), or suffer from a significant performance drop. In this work, we keep the translation performance while gaining 20\% speed up by introducing extra selection layer based on lightweight attention that selects a small portion of tokens to be attended. It takes advantage of the original attention to ensure performance and dimension reduction to accelerate inference. Experimental results show that our method could achieve up to 95\% sparsity (only 5\% tokens attended) approximately, and save 93\% computation cost on the attention module compared with the original Transformer, while maintaining the performance.