 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihang Dai
Transformer Quality in Linear Time
Feb 21, 2022
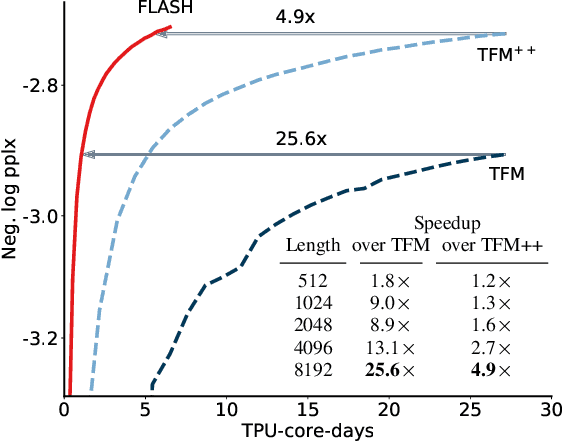
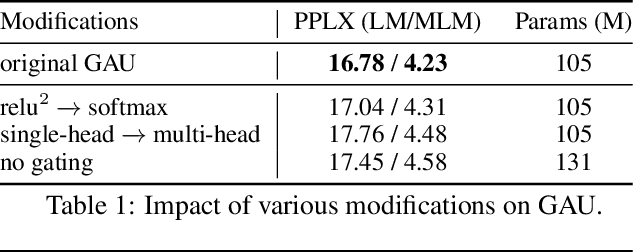
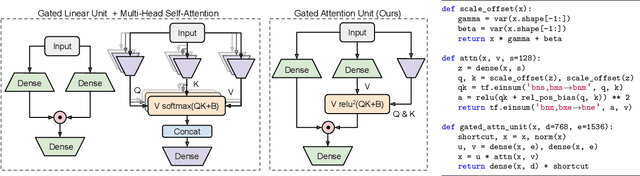

We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
Combined Scaling for Zero-shot Transfer Learning
Nov 19, 2021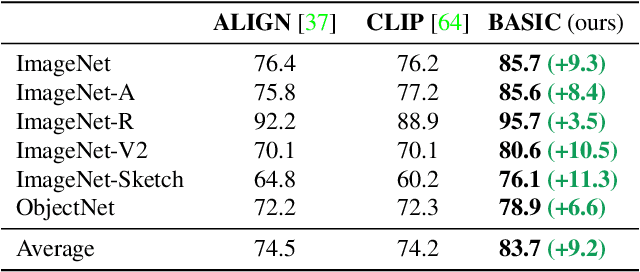
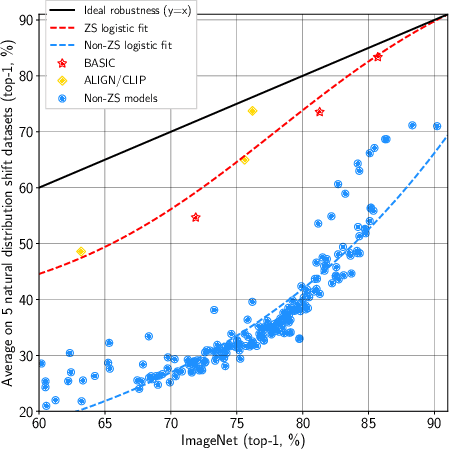
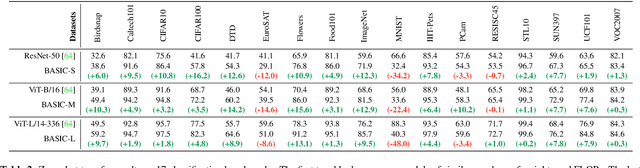

We present a combined scaling method called BASIC that achieves 85.7% top-1 zero-shot accuracy on the ImageNet ILSVRC-2012 validation set, surpassing the best-published zero-shot models - CLIP and ALIGN - by 9.3%. Our BASIC model also shows significant improvements in robustness benchmarks. For instance, on 5 test sets with natural distribution shifts such as ImageNet-{A,R,V2,Sketch} and ObjectNet, our model achieves 83.7% top-1 average accuracy, only a small drop from the its original ImageNet accuracy. To achieve these results, we scale up the contrastive learning framework of CLIP and ALIGN in three dimensions: data size, model size, and batch size. Our dataset has 6.6B noisy image-text pairs, which is 4x larger than ALIGN, and 16x larger than CLIP. Our largest model has 3B weights, which is 3.75x larger in parameters and 8x larger in FLOPs than ALIGN and CLIP. Our batch size is 65536 which is 2x more than CLIP and 4x more than ALIGN. The main challenge with scaling is the limited memory of our accelerators such as GPUs and TPUs. We hence propose a simple method of online gradient caching to overcome this limit.
Primer: Searching for Efficient Transformers for Language Modeling
Sep 17, 2021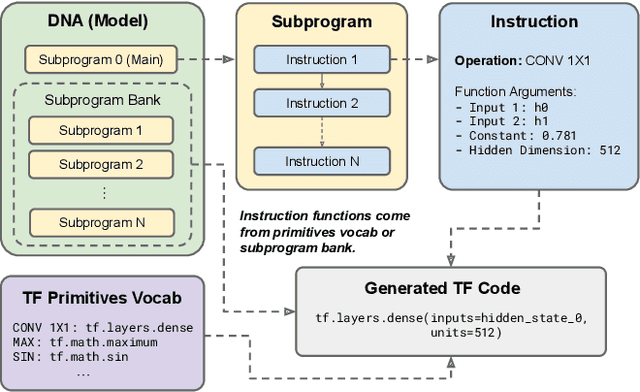
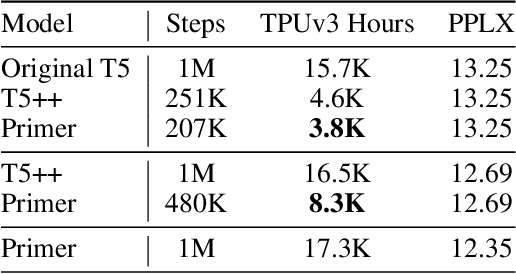
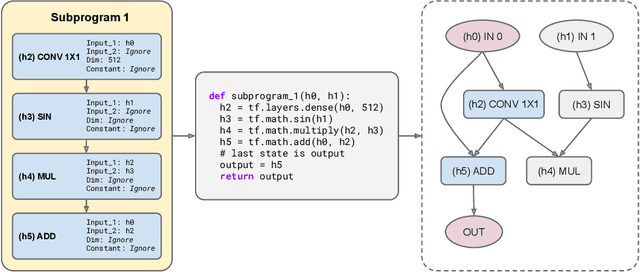
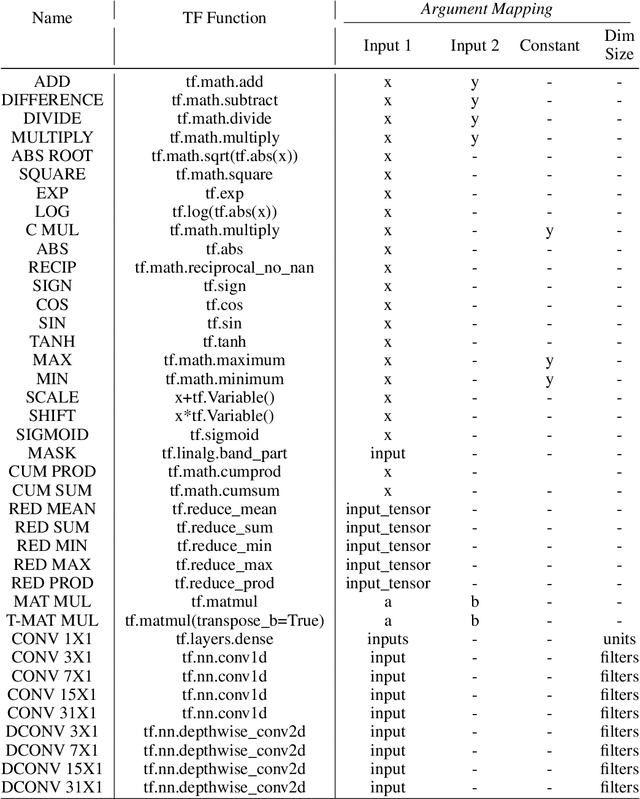
Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively expensive. Here we aim to reduce the costs of Transformers by searching for a more efficient variant. Compared to previous approaches, our search is performed at a lower level, over the primitives that define a Transformer TensorFlow program. We identify an architecture, named Primer, that has a smaller training cost than the original Transformer and other variants for auto-regressive language modeling. Primer's improvements can be mostly attributed to two simple modifications: squaring ReLU activations and adding a depthwise convolution layer after each Q, K, and V projection in self-attention. Experiments show Primer's gains over Transformer increase as compute scale grows and follow a power law with respect to quality at optimal model sizes. We also verify empirically that Primer can be dropped into different codebases to significantly speed up training without additional tuning. For example, at a 500M parameter size, Primer improves the original T5 architecture on C4 auto-regressive language modeling, reducing the training cost by 4X. Furthermore, the reduced training cost means Primer needs much less compute to reach a target one-shot performance. For instance, in a 1.9B parameter configuration similar to GPT-3 XL, Primer uses 1/3 of the training compute to achieve the same one-shot performance as Transformer. We open source our models and several comparisons in T5 to help with reproducibility.
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
Aug 24, 2021
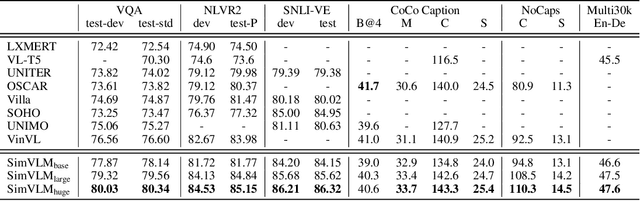
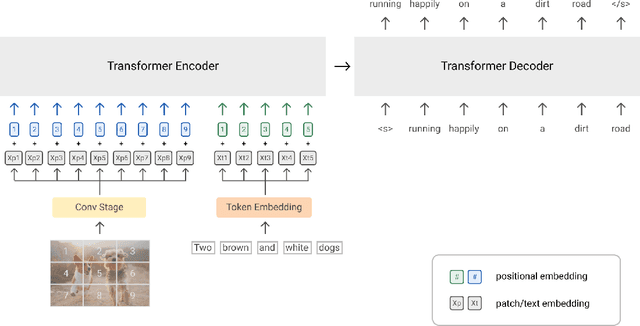
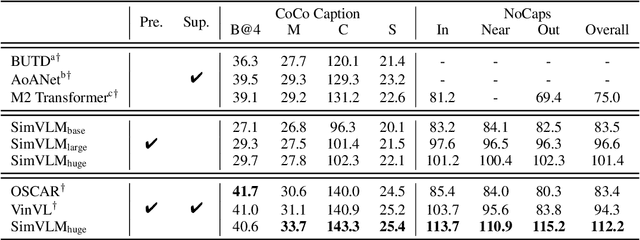
With recent progress in joint modeling of visual and textual representations, Vision-Language Pretraining (VLP) has achieved impressive performance on many multimodal downstream tasks. However, the requirement for expensive annotations including clean image captions and regional labels limits the scalability of existing approaches, and complicates the pretraining procedure with the introduction of multiple dataset-specific objectives. In this work, we relax these constraints and present a minimalist pretraining framework, named Simple Visual Language Model (SimVLM). Unlike prior work, SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective. Without utilizing extra data or task-specific customization, the resulting model significantly outperforms previous pretraining methods and achieves new state-of-the-art results on a wide range of discriminative and generative vision-language benchmarks, including VQA (+3.74% vqa-score), NLVR2 (+1.17% accuracy), SNLI-VE (+1.37% accuracy) and image captioning tasks (+10.1% average CIDEr score). Furthermore, we demonstrate that SimVLM acquires strong generalization and transfer ability, enabling zero-shot behavior including open-ended visual question answering and cross-modality transfer.
Combiner: Full Attention Transformer with Sparse Computation Cost
Jul 12, 2021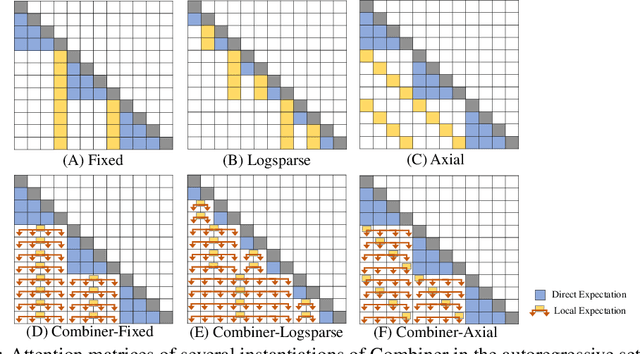
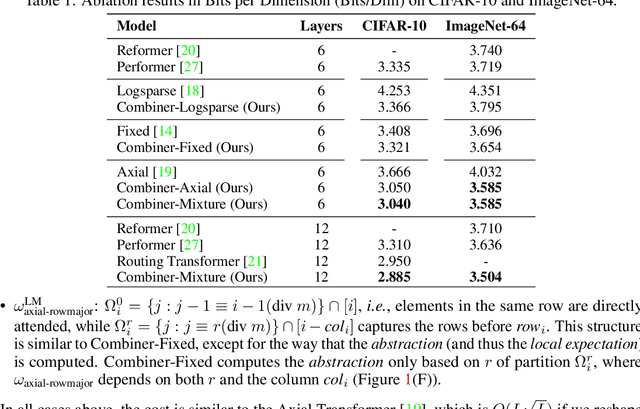
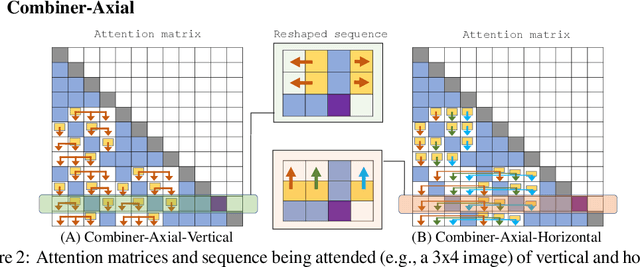

Transformers provide a class of expressive architectures that are extremely effective for sequence modeling. However, the key limitation of transformers is their quadratic memory and time complexity $\mathcal{O}(L^2)$ with respect to the sequence length in attention layers, which restricts application in extremely long sequences. Most existing approaches leverage sparsity or low-rank assumptions in the attention matrix to reduce cost, but sacrifice expressiveness. Instead, we propose Combiner, which provides full attention capability in each attention head while maintaining low computation and memory complexity. The key idea is to treat the self-attention mechanism as a conditional expectation over embeddings at each location, and approximate the conditional distribution with a structured factorization. Each location can attend to all other locations, either via direct attention, or through indirect attention to abstractions, which are again conditional expectations of embeddings from corresponding local regions. We show that most sparse attention patterns used in existing sparse transformers are able to inspire the design of such factorization for full attention, resulting in the same sub-quadratic cost ($\mathcal{O}(L\log(L))$ or $\mathcal{O}(L\sqrt{L})$). Combiner is a drop-in replacement for attention layers in existing transformers and can be easily implemented in common frameworks. An experimental evaluation on both autoregressive and bidirectional sequence tasks demonstrates the effectiveness of this approach, yielding state-of-the-art results on several image and text modeling tasks.
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Jun 09, 2021

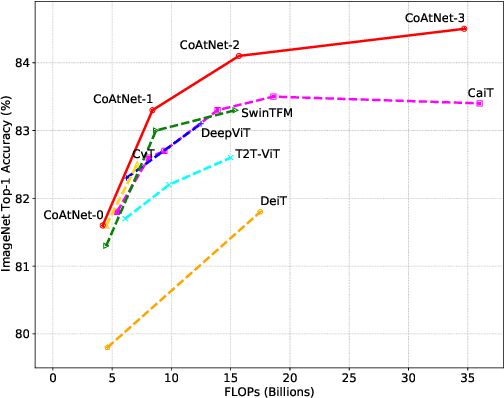
Transformers have attracted increasing interests in computer vision, but they still fall behind state-of-the-art convolutional networks. In this work, we show that while Transformers tend to have larger model capacity, their generalization can be worse than convolutional networks due to the lack of the right inductive bias. To effectively combine the strengths from both architectures, we present CoAtNets(pronounced "coat" nets), a family of hybrid models built from two key insights:(1) depthwise Convolution and self-Attention can be naturally unified via simple relative attention; (2) vertically stacking convolution layers and attention layers in a principled way is surprisingly effective in improving generalization, capacity and efficiency. Experiments show that our CoAtNets achieve state-of-the-art performance under different resource constraints across various datasets. For example, CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data, and 89.77% with extra JFT data, outperforming prior arts of both convolutional networks and Transformers. Notably, when pre-trained with 13M images fromImageNet-21K, our CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Pay Attention to MLPs
Jun 01, 2021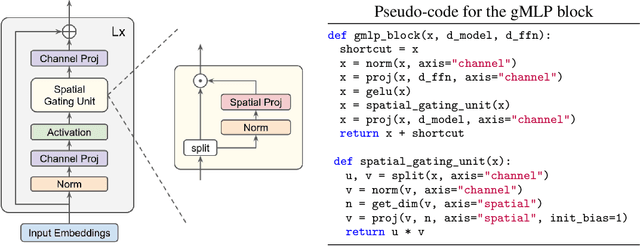
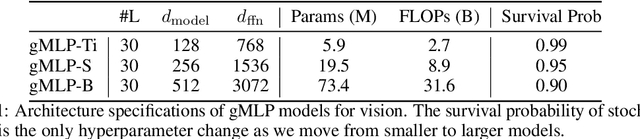
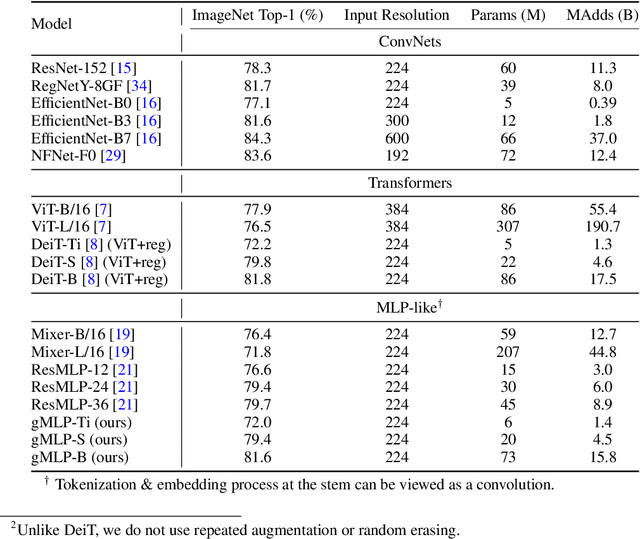
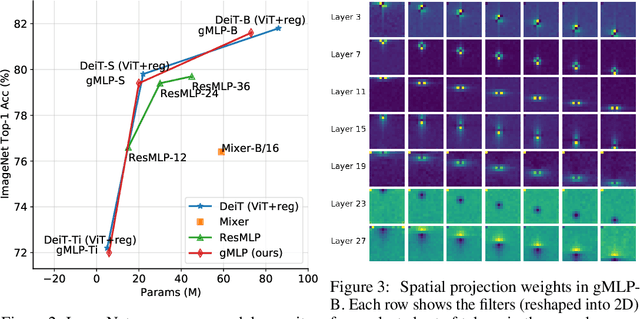
Transformers have become one of the most important architectural innovations in deep learning and have enabled many breakthroughs over the past few years. Here we propose a simple network architecture, gMLP, based on MLPs with gating, and show that it can perform as well as Transformers in key language and vision applications. Our comparisons show that self-attention is not critical for Vision Transformers, as gMLP can achieve the same accuracy. For BERT, our model achieves parity with Transformers on pretraining perplexity and is better on some downstream NLP tasks. On finetuning tasks where gMLP performs worse, making the gMLP model substantially larger can close the gap with Transformers. In general, our experiments show that gMLP can scale as well as Transformers over increased data and compute.
Unsupervised Parallel Corpus Mining on Web Data
Sep 18, 2020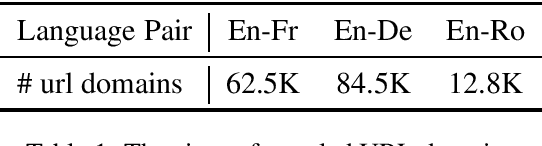
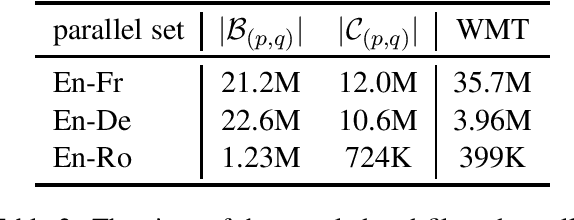
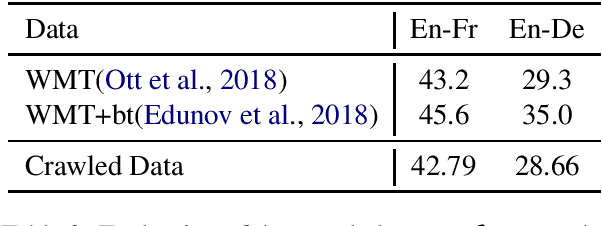
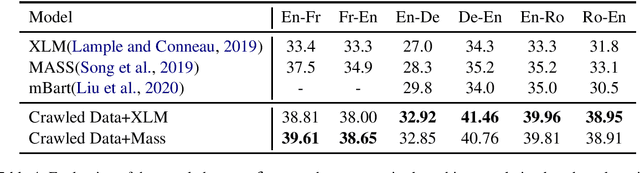
With a large amount of parallel data, neural machine translation systems are able to deliver human-level performance for sentence-level translation. However, it is costly to label a large amount of parallel data by humans. In contrast, there is a large-scale of parallel corpus created by humans on the Internet. The major difficulty to utilize them is how to filter them out from the noise website environments. Current parallel data mining methods all require labeled parallel data as the training source. In this paper, we present a pipeline to mine the parallel corpus from the Internet in an unsupervised manner. On the widely used WMT'14 English-French and WMT'16 English-German benchmarks, the machine translator trained with the data extracted by our pipeline achieves very close performance to the supervised results. On the WMT'16 English-Romanian and Romanian-English benchmarks, our system produces new state-of-the-art results, 39.81 and 38.95 BLEU scores, even compared with supervised approaches.
Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
Jun 05, 2020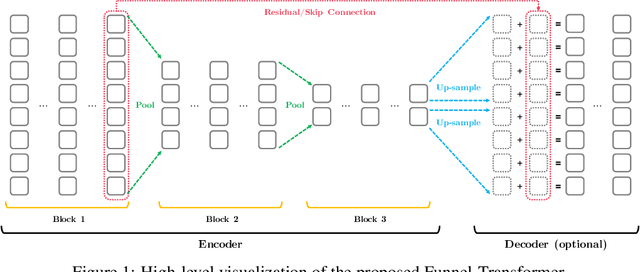
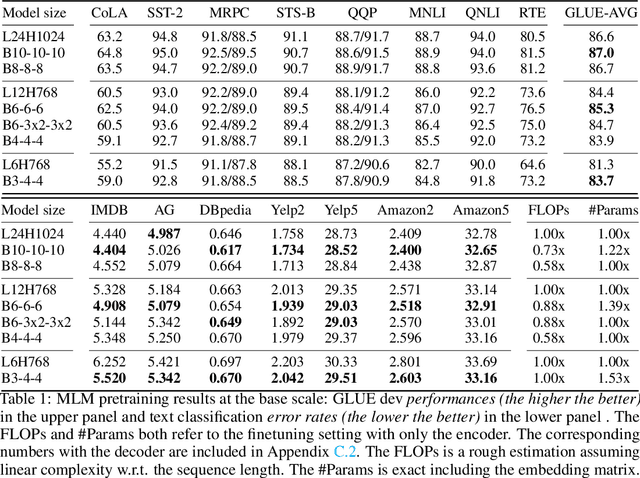
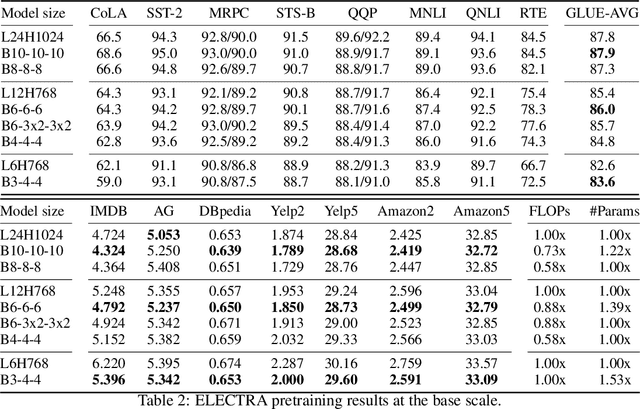
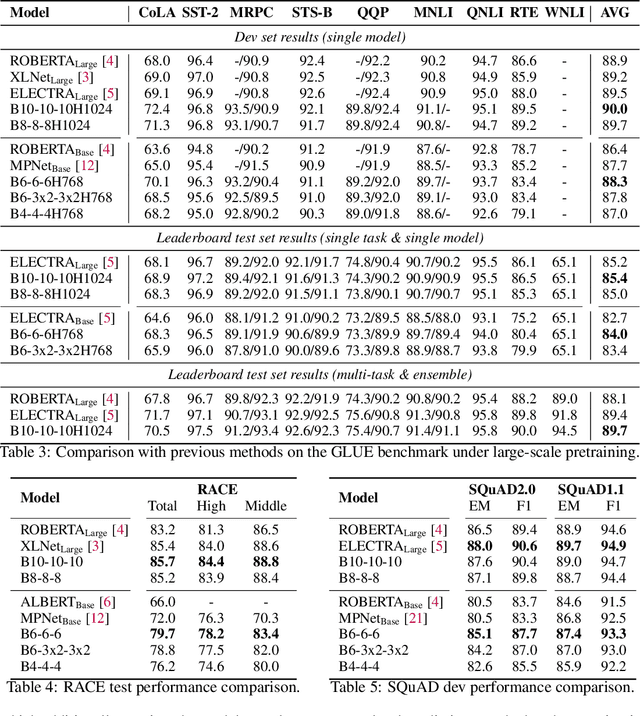
With the success of language pretraining, it is highly desirable to develop more efficient architectures of good scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further improve the model capacity. In addition, to perform token-level predictions as required by common pretraining objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading comprehension. The code and pretrained checkpoints are available at https://github.com/laiguokun/Funnel-Transformer.