 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiming Li
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Apr 06, 2024
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
PartManip: Learning Cross-Category Generalizable Part Manipulation Policy from Point Cloud Observations
Mar 29, 2023


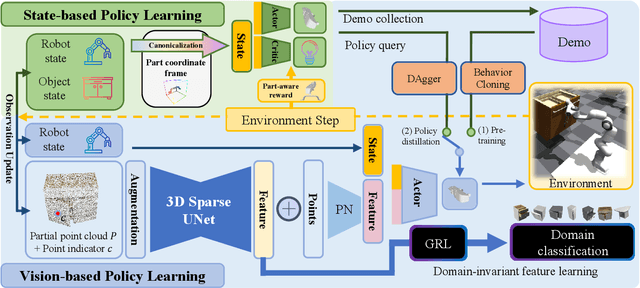
Learning a generalizable object manipulation policy is vital for an embodied agent to work in complex real-world scenes. Parts, as the shared components in different object categories, have the potential to increase the generalization ability of the manipulation policy and achieve cross-category object manipulation. In this work, we build the first large-scale, part-based cross-category object manipulation benchmark, PartManip, which is composed of 11 object categories, 494 objects, and 1432 tasks in 6 task classes. Compared to previous work, our benchmark is also more diverse and realistic, i.e., having more objects and using sparse-view point cloud as input without oracle information like part segmentation. To tackle the difficulties of vision-based policy learning, we first train a state-based expert with our proposed part-based canonicalization and part-aware rewards, and then distill the knowledge to a vision-based student. We also find an expressive backbone is essential to overcome the large diversity of different objects. For cross-category generalization, we introduce domain adversarial learning for domain-invariant feature extraction. Extensive experiments in simulation show that our learned policy can outperform other methods by a large margin, especially on unseen object categories. We also demonstrate our method can successfully manipulate novel objects in the real world.
Collaborative Remote Control of Unmanned Ground Vehicles in Virtual Reality
Aug 24, 2022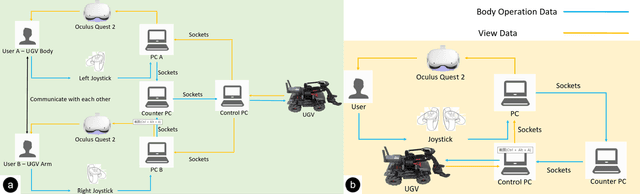

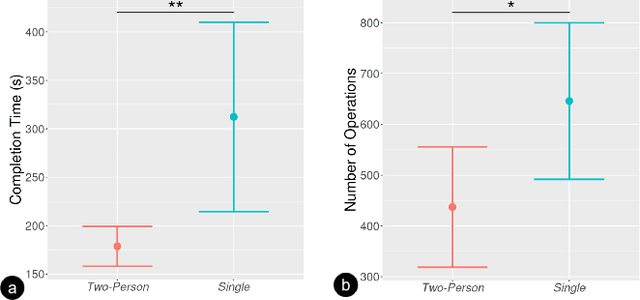
Virtual reality (VR) technology is commonly used in entertainment applications; however, it has also been deployed in practical applications in more serious aspects of our lives, such as safety. To support people working in dangerous industries, VR can ensure operators manipulate standardized tasks and work collaboratively to deal with potential risks. Surprisingly, little research has focused on how people can collaboratively work in VR environments. Few studies have paid attention to the cognitive load of operators in their collaborative tasks. Once task demands become complex, many researchers focus on optimizing the design of the interaction interfaces to reduce the cognitive load on the operator. That approach could be of merit; however, it can actually subject operators to a more significant cognitive load and potentially more errors and a failure of collaboration. In this paper, we propose a new collaborative VR system to support two teleoperators working in the VR environment to remote control an uncrewed ground vehicle. We use a compared experiment to evaluate the collaborative VR systems, focusing on the time spent on tasks and the total number of operations. Our results show that the total number of processes and the cognitive load during operations were significantly lower in the two-person group than in the single-person group. Our study sheds light on designing VR systems to support collaborative work with respect to the flow of work of teleoperators instead of simply optimizing the design outcomes.
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022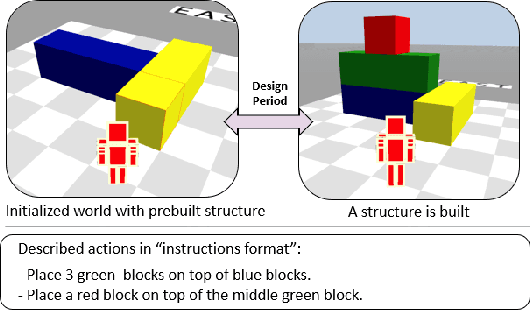

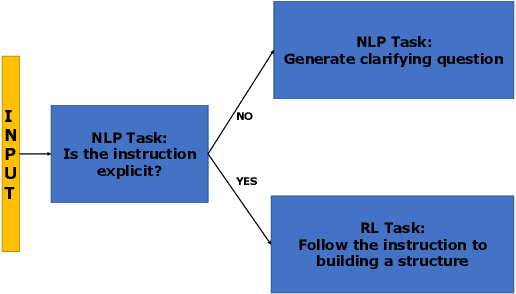
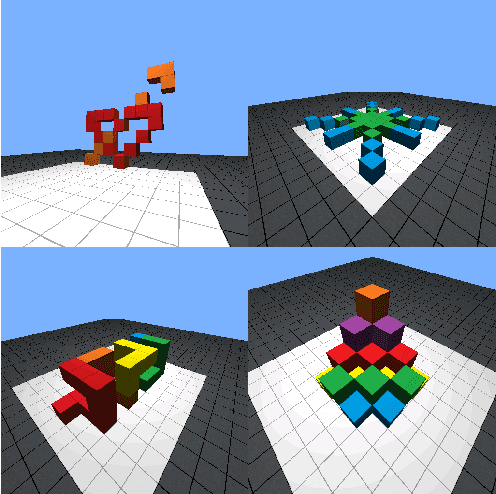
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
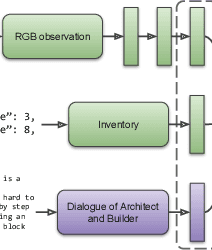
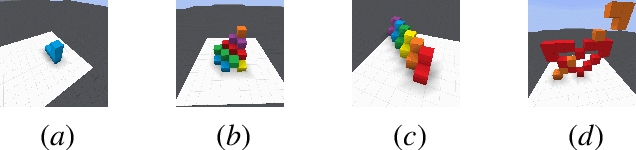
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021

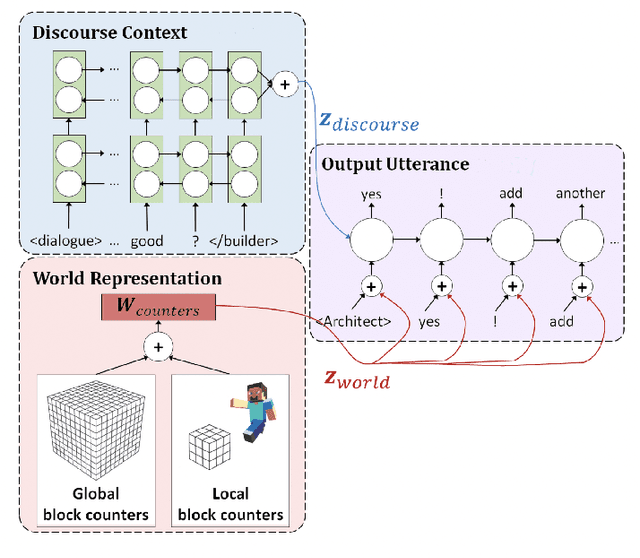
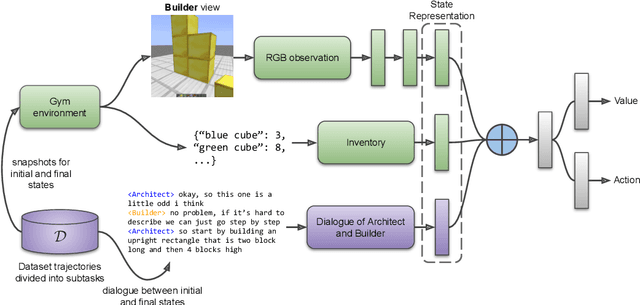
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Improving Response Quality with Backward Reasoning in Open-domain Dialogue Systems
Apr 30, 2021

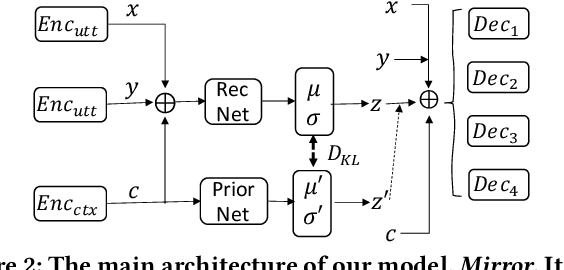
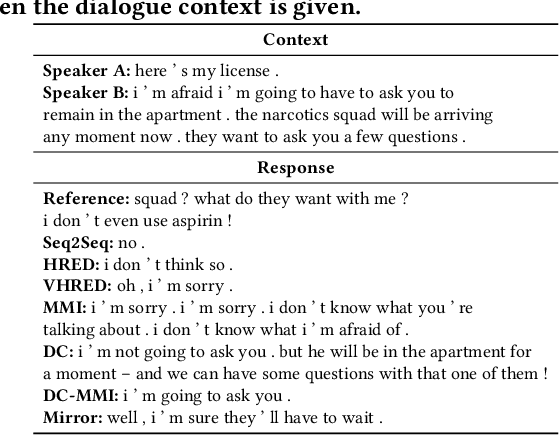
Being able to generate informative and coherent dialogue responses is crucial when designing human-like open-domain dialogue systems. Encoder-decoder-based dialogue models tend to produce generic and dull responses during the decoding step because the most predictable response is likely to be a non-informative response instead of the most suitable one. To alleviate this problem, we propose to train the generation model in a bidirectional manner by adding a backward reasoning step to the vanilla encoder-decoder training. The proposed backward reasoning step pushes the model to produce more informative and coherent content because the forward generation step's output is used to infer the dialogue context in the backward direction. The advantage of our method is that the forward generation and backward reasoning steps are trained simultaneously through the use of a latent variable to facilitate bidirectional optimization. Our method can improve response quality without introducing side information (e.g., a pre-trained topic model). The proposed bidirectional response generation method achieves state-of-the-art performance for response quality.
A Data-driven Approach to Estimate User Satisfaction in Multi-turn Dialogues
Mar 01, 2021
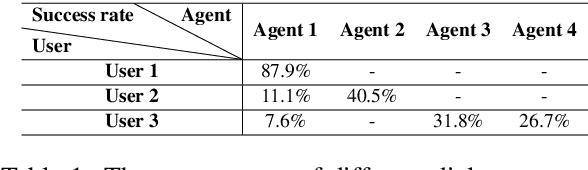

The evaluation of multi-turn dialogues remains challenging. The common approach of labeling the user satisfaction with the experience on the dialogue level does not reflect the task's difficulty. Therefore assigning the same experience score to two tasks with different complexity levels is misleading. Another approach, which suggests evaluating each dialogue turn independently, ignores each turn's long-term influence over the final user experience with dialogue. We instead develop a new method to estimate the turn-level satisfaction for dialogue, which is context-sensitive and has a long-term view. Our approach is data-driven which makes it easily personalized. The interactions between users and dialogue systems are formulated using a budget consumption setup. We assume the user has an initial interaction budget for a conversation based on the task complexity, and each dialogue turn has a cost. When the task is completed or the budget has been run out, the user will quit the interaction. We demonstrate the effectiveness of our method by extensive experimentation with a simulated dialogue platform and a realistic dialogue dataset.
Rethinking Supervised Learning and Reinforcement Learning in Task-Oriented Dialogue Systems
Sep 21, 2020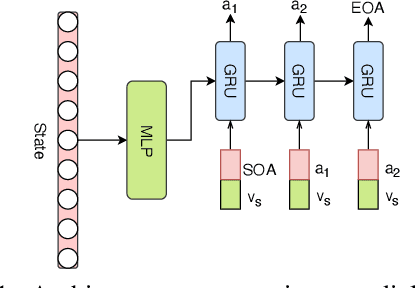

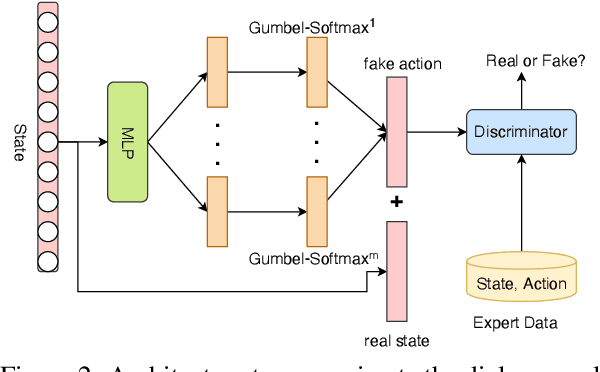

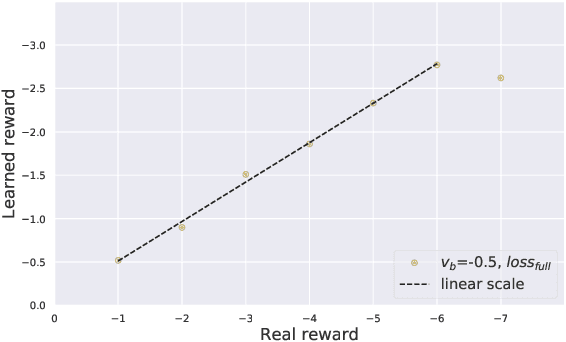
Dialogue policy learning for task-oriented dialogue systems has enjoyed great progress recently mostly through employing reinforcement learning methods. However, these approaches have become very sophisticated. It is time to re-evaluate it. Are we really making progress developing dialogue agents only based on reinforcement learning? We demonstrate how (1)~traditional supervised learning together with (2)~a simulator-free adversarial learning method can be used to achieve performance comparable to state-of-the-art RL-based methods. First, we introduce a simple dialogue action decoder to predict the appropriate actions. Then, the traditional multi-label classification solution for dialogue policy learning is extended by adding dense layers to improve the dialogue agent performance. Finally, we employ the Gumbel-Softmax estimator to alternatively train the dialogue agent and the dialogue reward model without using reinforcement learning. Based on our extensive experimentation, we can conclude the proposed methods can achieve more stable and higher performance with fewer efforts, such as the domain knowledge required to design a user simulator and the intractable parameter tuning in reinforcement learning. Our main goal is not to beat reinforcement learning with supervised learning, but to demonstrate the value of rethinking the role of reinforcement learning and supervised learning in optimizing task-oriented dialogue systems.
* 10 pages
Optimizing Interactive Systems via Data-Driven Objectives
Jun 19, 2020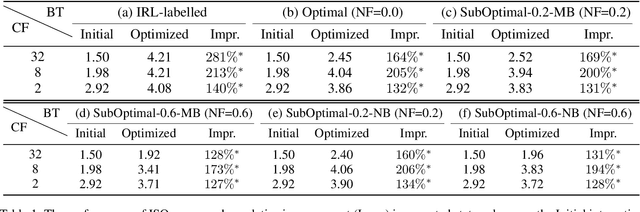
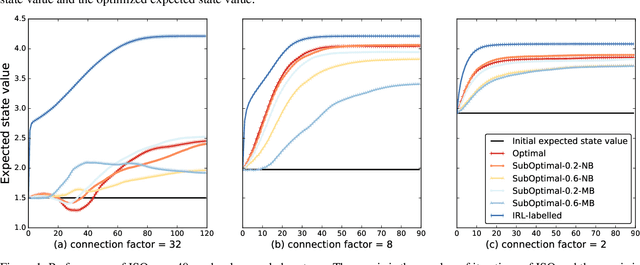
Effective optimization is essential for real-world interactive systems to provide a satisfactory user experience in response to changing user behavior. However, it is often challenging to find an objective to optimize for interactive systems (e.g., policy learning in task-oriented dialog systems). Generally, such objectives are manually crafted and rarely capture complex user needs in an accurate manner. We propose an approach that infers the objective directly from observed user interactions. These inferences can be made regardless of prior knowledge and across different types of user behavior. We introduce Interactive System Optimizer (ISO), a novel algorithm that uses these inferred objectives for optimization. Our main contribution is a new general principled approach to optimizing interactive systems using data-driven objectives. We demonstrate the high effectiveness of ISO over several simulations.