 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZining Zhu
What does the Knowledge Neuron Thesis Have to do with Knowledge?
May 03, 2024
We reassess the Knowledge Neuron (KN) Thesis: an interpretation of the mechanism underlying the ability of large language models to recall facts from a training corpus. This nascent thesis proposes that facts are recalled from the training corpus through the MLP weights in a manner resembling key-value memory, implying in effect that "knowledge" is stored in the network. Furthermore, by modifying the MLP modules, one can control the language model's generation of factual information. The plausibility of the KN thesis has been demonstrated by the success of KN-inspired model editing methods (Dai et al., 2022; Meng et al., 2022). We find that this thesis is, at best, an oversimplification. Not only have we found that we can edit the expression of certain linguistic phenomena using the same model editing methods but, through a more comprehensive evaluation, we have found that the KN thesis does not adequately explain the process of factual expression. While it is possible to argue that the MLP weights store complex patterns that are interpretable both syntactically and semantically, these patterns do not constitute "knowledge." To gain a more comprehensive understanding of the knowledge representation process, we must look beyond the MLP weights and explore recent models' complex layer structures and attention mechanisms.
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Apr 08, 2024Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
* 9 pages, 3 figures, Presented at Deployable AI Workshop at AAAI-2024
A State-Vector Framework for Dataset Effects
Oct 17, 2023The impressive success of recent deep neural network (DNN)-based systems is significantly influenced by the high-quality datasets used in training. However, the effects of the datasets, especially how they interact with each other, remain underexplored. We propose a state-vector framework to enable rigorous studies in this direction. This framework uses idealized probing test results as the bases of a vector space. This framework allows us to quantify the effects of both standalone and interacting datasets. We show that the significant effects of some commonly-used language understanding datasets are characteristic and are concentrated on a few linguistic dimensions. Additionally, we observe some ``spill-over'' effects: the datasets could impact the models along dimensions that may seem unrelated to the intended tasks. Our state-vector framework paves the way for a systematic understanding of the dataset effects, a crucial component in responsible and robust model development.
Measuring Information in Text Explanations
Oct 06, 2023Text-based explanation is a particularly promising approach in explainable AI, but the evaluation of text explanations is method-dependent. We argue that placing the explanations on an information-theoretic framework could unify the evaluations of two popular text explanation methods: rationale and natural language explanations (NLE). This framework considers the post-hoc text pipeline as a series of communication channels, which we refer to as ``explanation channels''. We quantify the information flow through these channels, thereby facilitating the assessment of explanation characteristics. We set up tools for quantifying two information scores: relevance and informativeness. We illustrate what our proposed information scores measure by comparing them against some traditional evaluation metrics. Our information-theoretic scores reveal some unique observations about the underlying mechanisms of two representative text explanations. For example, the NLEs trade-off slightly between transmitting the input-related information and the target-related information, whereas the rationales do not exhibit such a trade-off mechanism. Our work contributes to the ongoing efforts in establishing rigorous and standardized evaluation criteria in the rapidly evolving field of explainable AI.
Situated Natural Language Explanations
Aug 27, 2023


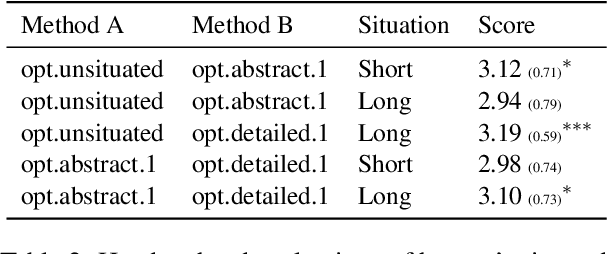
Natural language is among the most accessible tools for explaining decisions to humans, and large pretrained language models (PLMs) have demonstrated impressive abilities to generate coherent natural language explanations (NLE). The existing NLE research perspectives do not take the audience into account. An NLE can have high textual quality, but it might not accommodate audiences' needs and preference. To address this limitation, we propose an alternative perspective, situated NLE, including a situated generation framework and a situated evaluation framework. On the generation side, we propose simple prompt engineering methods that adapt the NLEs to situations. In human studies, the annotators preferred the situated NLEs. On the evaluation side, we set up automated evaluation scores in lexical, semantic, and pragmatic categories. The scores can be used to select the most suitable prompts to generate NLEs. Situated NLE provides a perspective to conduct further research on automatic NLE generations.
CCGen: Explainable Complementary Concept Generation in E-Commerce
May 19, 2023
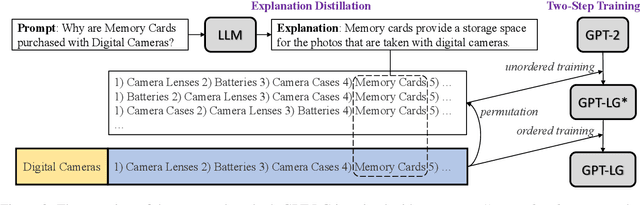
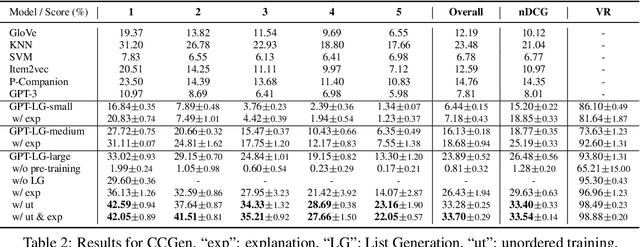
We propose and study Complementary Concept Generation (CCGen): given a concept of interest, e.g., "Digital Cameras", generating a list of complementary concepts, e.g., 1) Camera Lenses 2) Batteries 3) Camera Cases 4) Memory Cards 5) Battery Chargers. CCGen is beneficial for various applications like query suggestion and item recommendation, especially in the e-commerce domain. To solve CCGen, we propose to train language models to generate ranked lists of concepts with a two-step training strategy. We also teach the models to generate explanations by incorporating explanations distilled from large teacher models. Extensive experiments and analysis demonstrate that our model can generate high-quality concepts complementary to the input concept while producing explanations to justify the predictions.
Predicting Fine-Tuning Performance with Probing
Oct 13, 2022



Large NLP models have recently shown impressive performance in language understanding tasks, typically evaluated by their fine-tuned performance. Alternatively, probing has received increasing attention as being a lightweight method for interpreting the intrinsic mechanisms of large NLP models. In probing, post-hoc classifiers are trained on "out-of-domain" datasets that diagnose specific abilities. While probing the language models has led to insightful findings, they appear disjointed from the development of models. This paper explores the utility of probing deep NLP models to extract a proxy signal widely used in model development -- the fine-tuning performance. We find that it is possible to use the accuracies of only three probing tests to predict the fine-tuning performance with errors $40\%$ - $80\%$ smaller than baselines. We further discuss possible avenues where probing can empower the development of deep NLP models.
OOD-Probe: A Neural Interpretation of Out-of-Domain Generalization
Aug 25, 2022



The ability to generalize out-of-domain (OOD) is an important goal for deep neural network development, and researchers have proposed many high-performing OOD generalization methods from various foundations. While many OOD algorithms perform well in various scenarios, these systems are evaluated as ``black-boxes''. Instead, we propose a flexible framework that evaluates OOD systems with finer granularity using a probing module that predicts the originating domain from intermediate representations. We find that representations always encode some information about the domain. While the layerwise encoding patterns remain largely stable across different OOD algorithms, they vary across the datasets. For example, the information about rotation (on RotatedMNIST) is the most visible on the lower layers, while the information about style (on VLCS and PACS) is the most visible on the middle layers. In addition, the high probing results correlate to the domain generalization performances, leading to further directions in developing OOD generalization systems.
On the data requirements of probing
Feb 25, 2022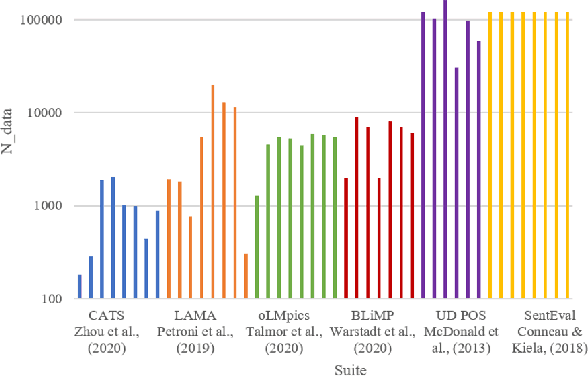

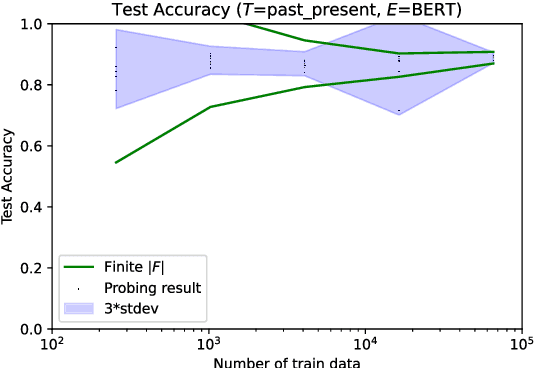
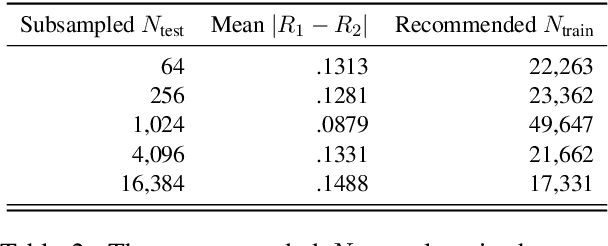
As large and powerful neural language models are developed, researchers have been increasingly interested in developing diagnostic tools to probe them. There are many papers with conclusions of the form "observation X is found in model Y", using their own datasets with varying sizes. Larger probing datasets bring more reliability, but are also expensive to collect. There is yet to be a quantitative method for estimating reasonable probing dataset sizes. We tackle this omission in the context of comparing two probing configurations: after we have collected a small dataset from a pilot study, how many additional data samples are sufficient to distinguish two different configurations? We present a novel method to estimate the required number of data samples in such experiments and, across several case studies, we verify that our estimations have sufficient statistical power. Our framework helps to systematically construct probing datasets to diagnose neural NLP models.
Neural reality of argument structure constructions
Feb 24, 2022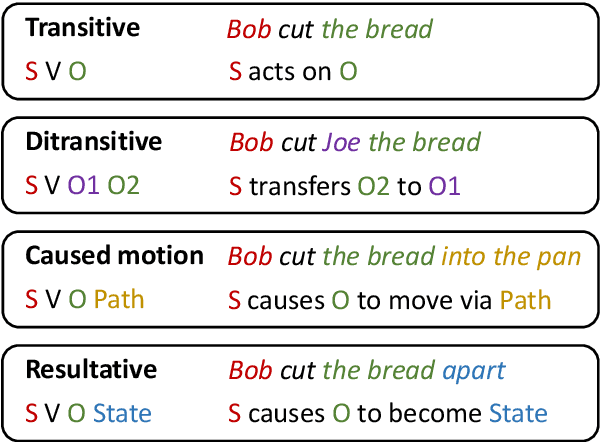


In lexicalist linguistic theories, argument structure is assumed to be predictable from the meaning of verbs. As a result, the verb is the primary determinant of the meaning of a clause. In contrast, construction grammarians propose that argument structure is encoded in constructions (or form-meaning pairs) that are distinct from verbs. Decades of psycholinguistic research have produced substantial empirical evidence in favor of the construction view. Here we adapt several psycholinguistic studies to probe for the existence of argument structure constructions (ASCs) in Transformer-based language models (LMs). First, using a sentence sorting experiment, we find that sentences sharing the same construction are closer in embedding space than sentences sharing the same verb. Furthermore, LMs increasingly prefer grouping by construction with more input data, mirroring the behaviour of non-native language learners. Second, in a "Jabberwocky" priming-based experiment, we find that LMs associate ASCs with meaning, even in semantically nonsensical sentences. Our work offers the first evidence for ASCs in LMs and highlights the potential to devise novel probing methods grounded in psycholinguistic research.