 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipeng Wang
Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Apr 09, 2024
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
P2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.
Learning Spatial-Temporal Implicit Neural Representations for Event-Guided Video Super-Resolution
Mar 29, 2023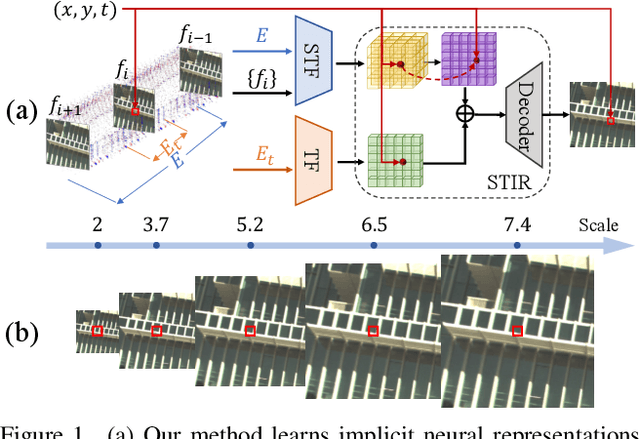
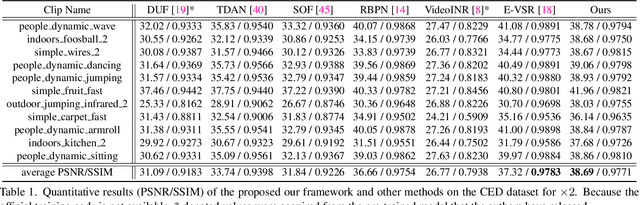
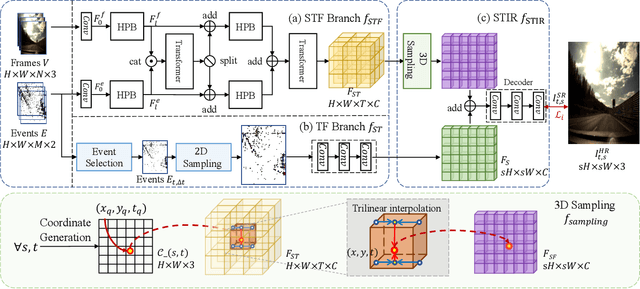
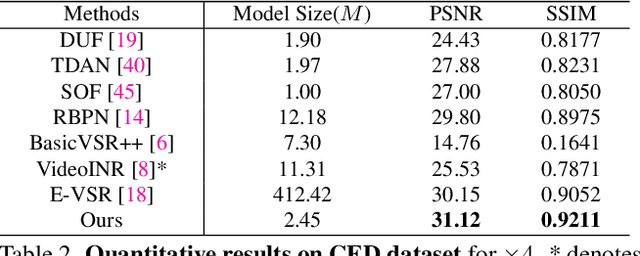
Event cameras sense the intensity changes asynchronously and produce event streams with high dynamic range and low latency. This has inspired research endeavors utilizing events to guide the challenging video superresolution (VSR) task. In this paper, we make the first attempt to address a novel problem of achieving VSR at random scales by taking advantages of the high temporal resolution property of events. This is hampered by the difficulties of representing the spatial-temporal information of events when guiding VSR. To this end, we propose a novel framework that incorporates the spatial-temporal interpolation of events to VSR in a unified framework. Our key idea is to learn implicit neural representations from queried spatial-temporal coordinates and features from both RGB frames and events. Our method contains three parts. Specifically, the Spatial-Temporal Fusion (STF) module first learns the 3D features from events and RGB frames. Then, the Temporal Filter (TF) module unlocks more explicit motion information from the events near the queried timestamp and generates the 2D features. Lastly, the SpatialTemporal Implicit Representation (STIR) module recovers the SR frame in arbitrary resolutions from the outputs of these two modules. In addition, we collect a real-world dataset with spatially aligned events and RGB frames. Extensive experiments show that our method significantly surpasses the prior-arts and achieves VSR with random scales, e.g., 6.5. Code and dataset are available at https: //vlis2022.github.io/cvpr23/egvsr.
A Received Power Model for Reconfigurable Intelligent Surface and Measurement-based Validations
May 13, 2021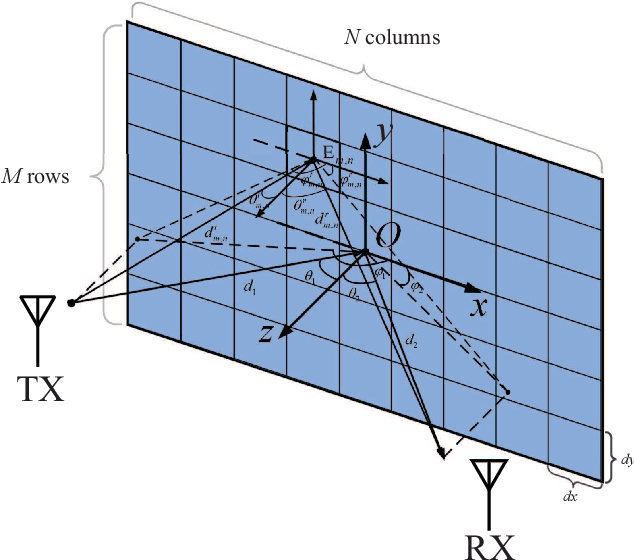
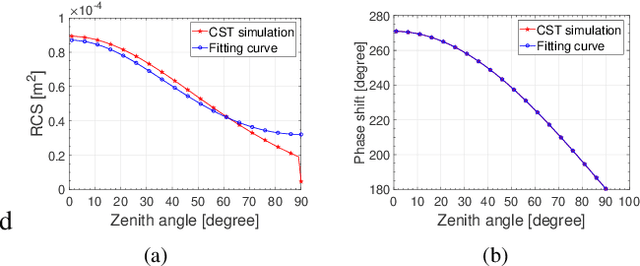
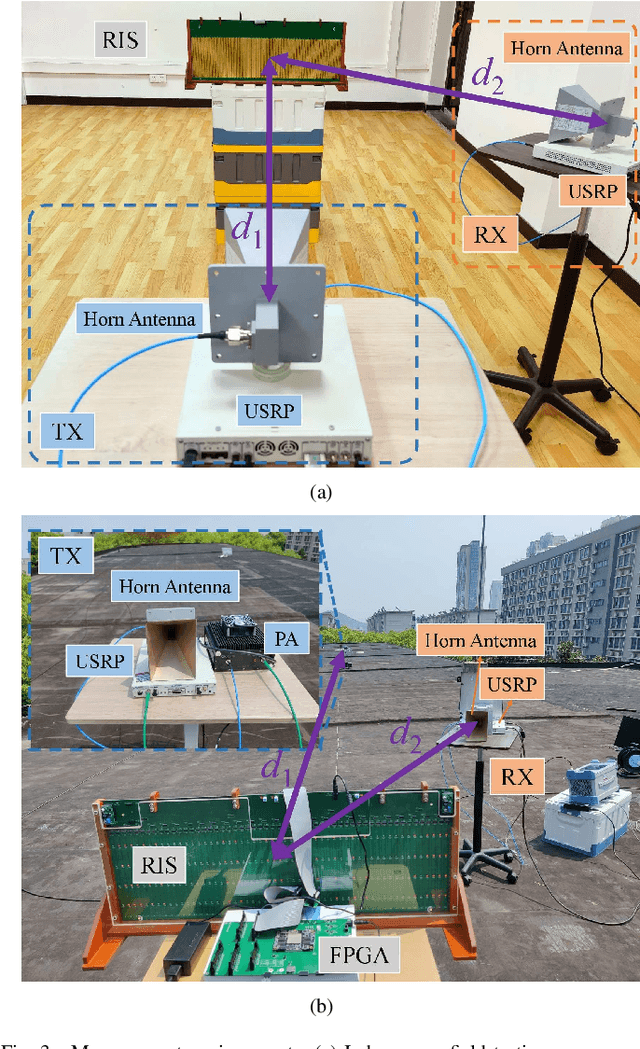
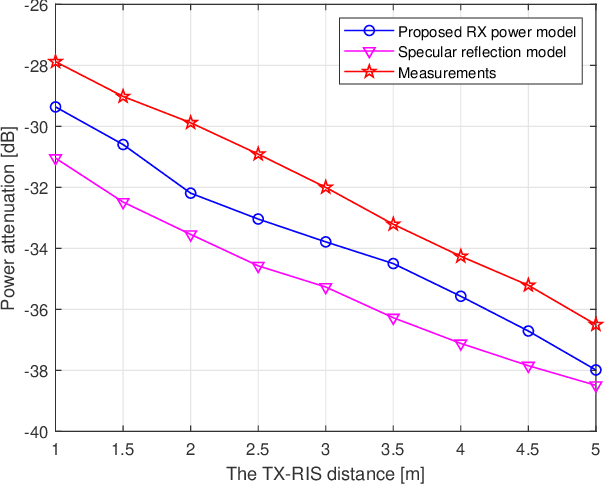
The idea of using a Reconfigurable Intelligent Surface (RIS) consisting of a large array of passive scattering elements to assist wireless communication systems has recently attracted much attention from academia and industry. A central issue with RIS is how much power they can effectively convey to the target radio nodes. Regarding this question, several power level models exist in the literature but few have been validated through experiments. In this paper, we propose a radar cross section-based received power model for an RIS-aided wireless communication system that is rooted in the physical properties of RIS. Our proposed model follows the intuition that the received power is related to the distances from the transmitter/receiver to the RIS, the angles in the TX-RIS-RX triangle, the effective area of each element, and the reflection coefficient of each element. To the best of our knowledge, this paper is the first to model the angle-dependent phase shift of the reflection coefficient, which is typically ignored in existing literature. We further measure the received power with our experimental platform in different scenarios to validate our model. The measurement results show that our model is appropriate both in near field and far field and can characterize the impact of angles well.
Video synthesis of human upper body with realistic face
Sep 12, 2019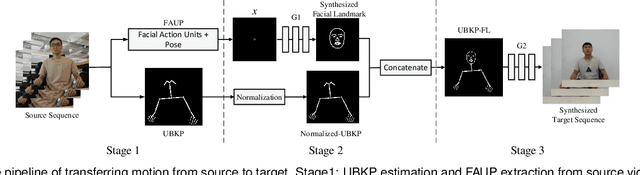
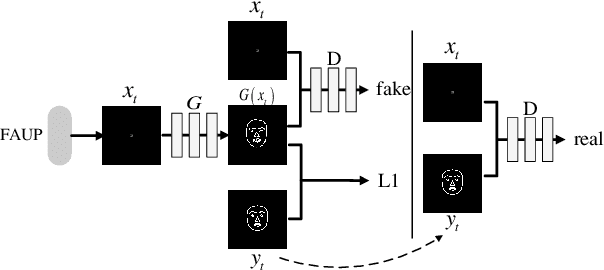
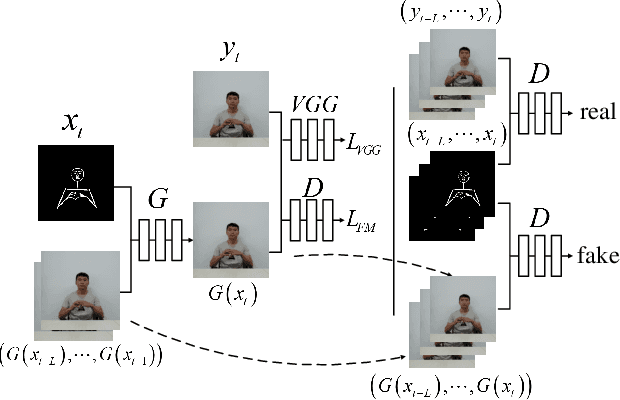

This paper presents a generative adversarial learning-based human upper body video synthesis approach to generate an upper body video of target person that is consistent with the body motion, face expression, and pose of the person in source video. We use upper body keypoints, facial action units and poses as intermediate representations between source video and target video. Instead of directly transferring the source video to the target video, we firstly map the source person's facial action units and poses into the target person's facial landmarks, then combine the normalized upper body keypoints and generated facial landmarks with spatio-temporal smoothing to generate the corresponding target video's image. Experimental results demonstrated the effectiveness of our method.
A Neural Virtual Anchor Synthesizer based on Seq2Seq and GAN Models
Sep 12, 2019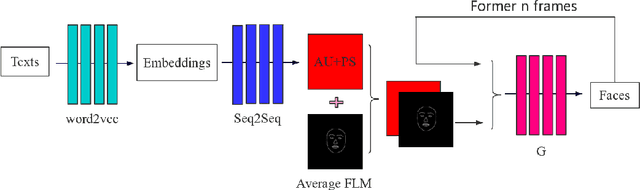
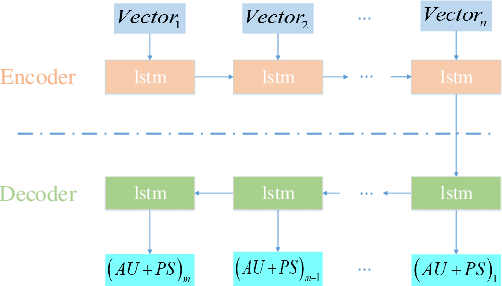
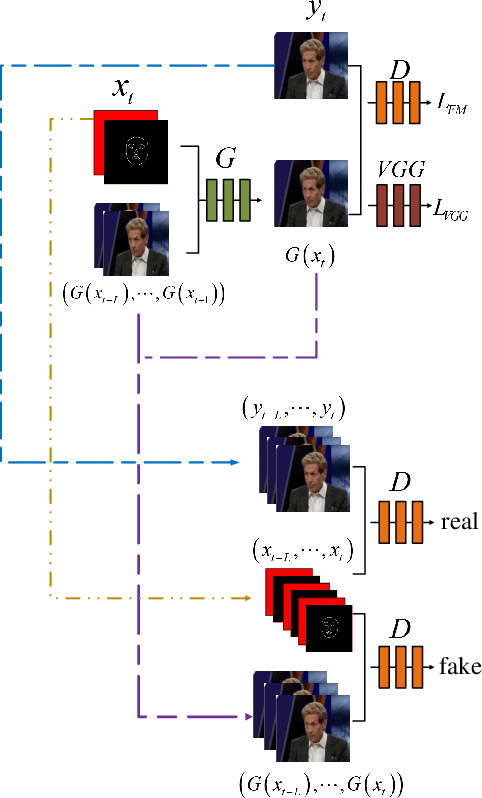
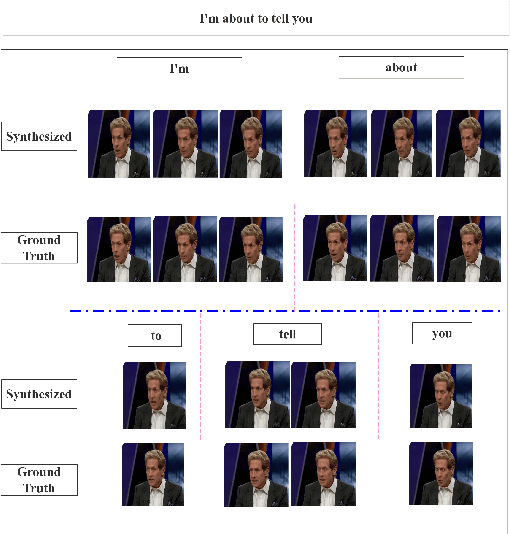
This paper presents a novel framework to generate realistic face video of an anchor, who is reading certain news. This task is also known as Virtual Anchor. Given some paragraphs of words, we first utilize a pretrained Word2Vec model to embed each word into a vector; then we utilize a Seq2Seq-based model to translate these word embeddings into action units and head poses of the target anchor; these action units and head poses will be concatenated with facial landmarks as well as the former $n$ synthesized frames, and the concatenation serves as input of a Pix2PixHD-based model to synthesize realistic facial images for the virtual anchor. The experimental results demonstrate our framework is feasible for the synthesis of virtual anchor.
How Old Are You? Face Age Translation with Identity Preservation Using GANs
Sep 11, 2019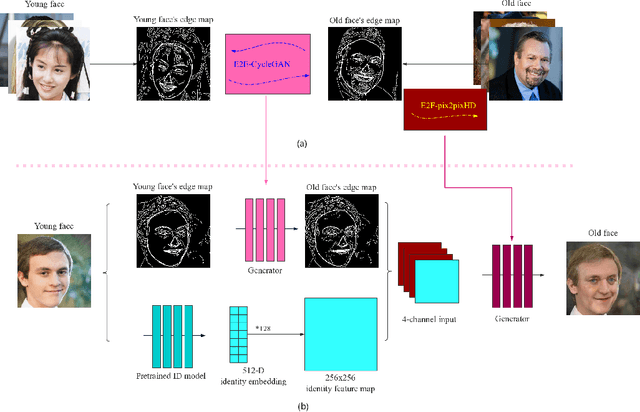

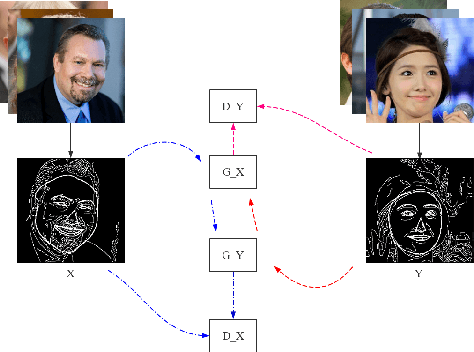
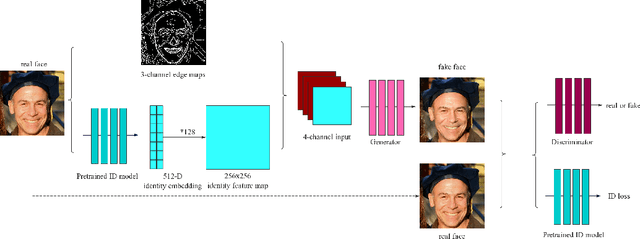
We present a novel framework to generate images of different age while preserving identity information, which is known as face aging. Different from most recent popular face aging networks utilizing Generative Adversarial Networks(GANs) application, our approach do not simply transfer a young face to an old one. Instead, we employ the edge map as intermediate representations, firstly edge maps of young faces are extracted, a CycleGAN-based network is adopted to transfer them into edge maps of old faces, then another pix2pixHD-based network is adopted to transfer the synthesized edge maps, concatenated with identity information, into old faces. In this way, our method can generate more realistic transfered images, simultaneously ensuring that face identity information be preserved well, and the apparent age of the generated image be accurately appropriate. Experimental results demonstrate that our method is feasible for face age translation.