 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiqi Wang
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024
Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
FedADMM-InSa: An Inexact and Self-Adaptive ADMM for Federated Learning
Feb 21, 2024Federated learning (FL) is a promising framework for learning from distributed data while maintaining privacy. The development of efficient FL algorithms encounters various challenges, including heterogeneous data and systems, limited communication capacities, and constrained local computational resources. Recently developed FedADMM methods show great resilience to both data and system heterogeneity. However, they still suffer from performance deterioration if the hyperparameters are not carefully tuned. To address this issue, we propose an inexact and self-adaptive FedADMM algorithm, termed FedADMM-InSa. First, we design an inexactness criterion for the clients' local updates to eliminate the need for empirically setting the local training accuracy. This inexactness criterion can be assessed by each client independently based on its unique condition, thereby reducing the local computational cost and mitigating the undesirable straggle effect. The convergence of the resulting inexact ADMM is proved under the assumption of strongly convex loss functions. Additionally, we present a self-adaptive scheme that dynamically adjusts each client's penalty parameter, enhancing algorithm robustness by mitigating the need for empirical penalty parameter choices for each client. Extensive numerical experiments on both synthetic and real-world datasets are conducted. As validated by some numerical tests, our proposed algorithm can reduce the clients' local computational load significantly and also accelerate the learning process compared to the vanilla FedADMM.
Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis
Feb 14, 2024In the current environment, psychological issues are prevalent and widespread, with social media serving as a key outlet for individuals to share their feelings. This results in the generation of vast quantities of data daily, where negative emotions have the potential to precipitate crisis situations. There is a recognized need for models capable of efficient analysis. While pre-trained language models have demonstrated their effectiveness broadly, there's a noticeable gap in pre-trained models tailored for specialized domains like psychology. To address this, we have collected a huge dataset from Chinese social media platforms and enriched it with publicly available datasets to create a comprehensive database encompassing 3.36 million text entries. To enhance the model's applicability to psychological text analysis, we integrated psychological lexicons into the pre-training masking mechanism. Building on an existing Chinese language model, we performed adaptive training to develop a model specialized for the psychological domain. We assessed our model's effectiveness across four public benchmarks, where it not only surpassed the performance of standard pre-trained models but also showed a inclination for making psychologically relevant predictions. Due to concerns regarding data privacy, the dataset will not be made publicly available. However, we have made the pre-trained models and codes publicly accessible to the community via: https://github.com/zwzzzQAQ/Chinese-MentalBERT.
Dimensionality reduction can be used as a surrogate model for high-dimensional forward uncertainty quantification
Feb 07, 2024We introduce a method to construct a stochastic surrogate model from the results of dimensionality reduction in forward uncertainty quantification. The hypothesis is that the high-dimensional input augmented by the output of a computational model admits a low-dimensional representation. This assumption can be met by numerous uncertainty quantification applications with physics-based computational models. The proposed approach differs from a sequential application of dimensionality reduction followed by surrogate modeling, as we "extract" a surrogate model from the results of dimensionality reduction in the input-output space. This feature becomes desirable when the input space is genuinely high-dimensional. The proposed method also diverges from the Probabilistic Learning on Manifold, as a reconstruction mapping from the feature space to the input-output space is circumvented. The final product of the proposed method is a stochastic simulator that propagates a deterministic input into a stochastic output, preserving the convenience of a sequential "dimensionality reduction + Gaussian process regression" approach while overcoming some of its limitations. The proposed method is demonstrated through two uncertainty quantification problems characterized by high-dimensional input uncertainties.
TADIS: Steering Models for Deep-Thinking about Demonstration Examples
Oct 05, 2023
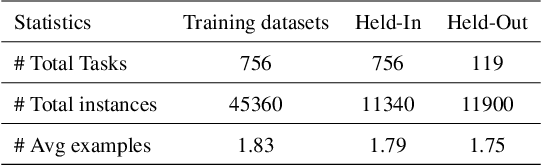
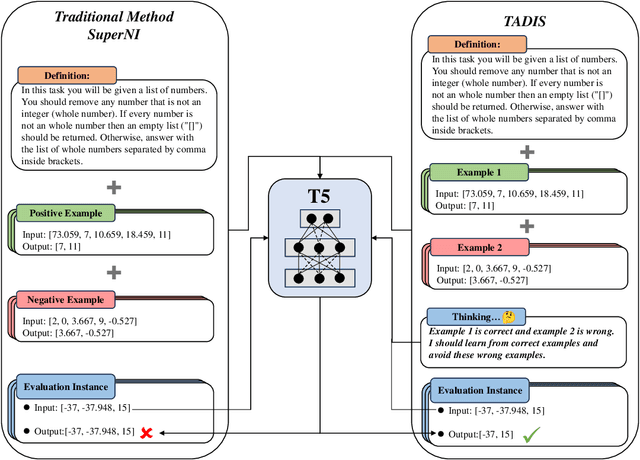
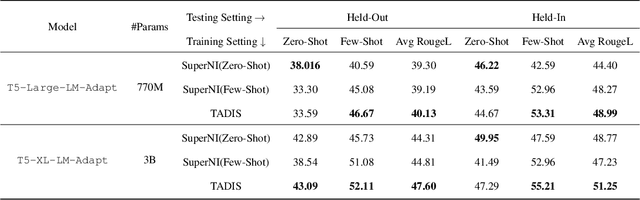
Instruction tuning has been demonstrated that could significantly improve the zero-shot generalization capability to unseen tasks by an apparent margin. By incorporating additional context (e.g., task definition, examples) during the fine-tuning process, Large Language Models (LLMs) achieved much higher performance than before. However, recent work reported that delusive task examples can achieve almost the same performance as correct task examples, indicating the input-label correspondence is less important than previously thought. Intrigued by this counter-intuitive observation, we suspect models have the same illusion of competence as humans. Therefore, we propose a novel method called TADIS that steers LLMs for "Deep-Thinking'' about demonstration examples instead of merely seeing. To alleviate the illusion of competence of models, we first ask the model to verify the correctness of shown examples. Then, using the verification results as conditions to elicit models for a better answer. Our experimental results show that TADIS consistently outperforms competitive baselines on in-domain and out-domain tasks (improving 2.79 and 4.03 average ROUGLE-L on out-domain and in-domain datasets, respectively). Despite the presence of generated examples (not all of the thinking labels are accurate), TADIS can notably enhance performance in zero-shot and few-shot settings. This also suggests that our approach can be adopted on a large scale to improve the instruction following capabilities of models without any manual labor. Moreover, we construct three types of thinking labels with different model sizes and find that small models learn from the format of TADIS but larger models can be steered for "Deep-Thinking''.
Enable Language Models to Implicitly Learn Self-Improvement From Data
Oct 05, 2023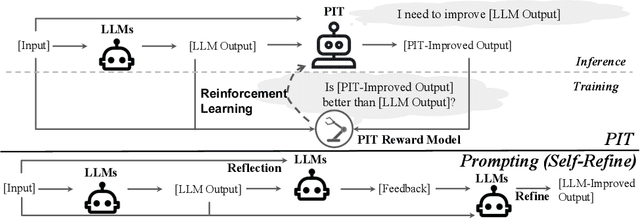
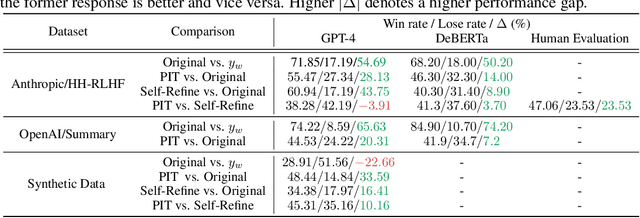
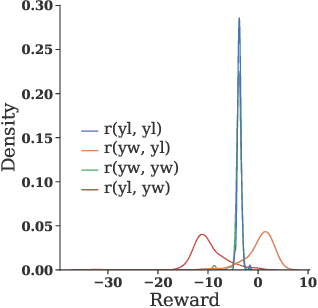

Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses. To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience. However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human efforts. Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) -- instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
Parameter-Efficient Tuning Helps Language Model Alignment
Oct 01, 2023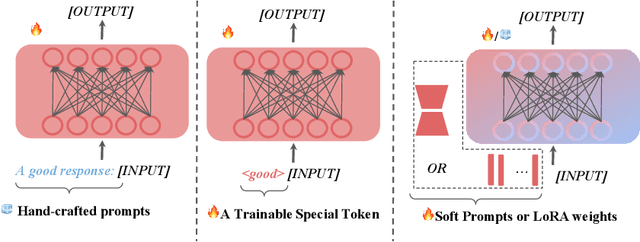
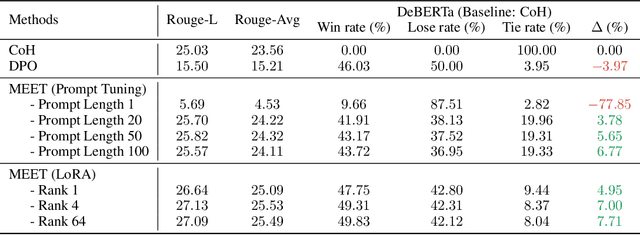
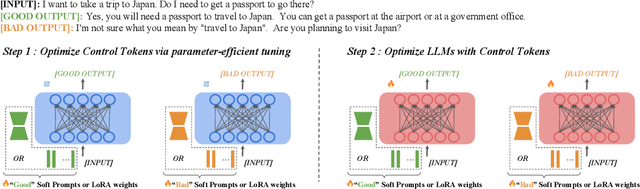
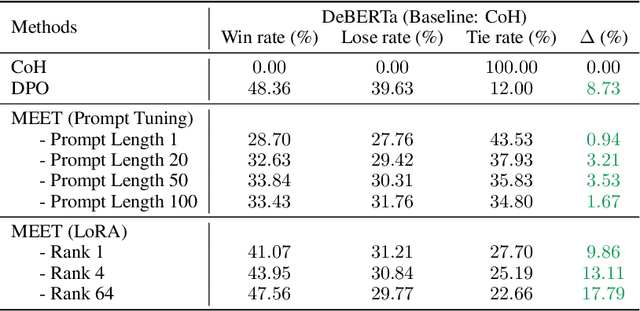
Aligning large language models (LLMs) with human preferences is essential for safe and useful LLMs. Previous works mainly adopt reinforcement learning (RLHF) and direct preference optimization (DPO) with human feedback for alignment. Nevertheless, they have certain drawbacks. One such limitation is that they can only align models with one preference at the training time (e.g., they cannot learn to generate concise responses when the preference data prefers detailed responses), or have certain constraints for the data format (e.g., DPO only supports pairwise preference data). To this end, prior works incorporate controllable generations for alignment to make language models learn multiple preferences and provide outputs with different preferences during inference if asked. Controllable generation also offers more flexibility with regard to data format (e.g., it supports pointwise preference data). Specifically, it uses different control tokens for different preferences during training and inference, making LLMs behave differently when required. Current controllable generation methods either use a special token or hand-crafted prompts as control tokens, and optimize them together with LLMs. As control tokens are typically much lighter than LLMs, this optimization strategy may not effectively optimize control tokens. To this end, we first use parameter-efficient tuning (e.g., prompting tuning and low-rank adaptation) to optimize control tokens and then fine-tune models for controllable generations, similar to prior works. Our approach, alignMEnt with parameter-Efficient Tuning (MEET), improves the quality of control tokens, thus improving controllable generation quality consistently by an apparent margin on two well-recognized datasets compared with prior works.
Enabling Resource-efficient AIoT System with Cross-level Optimization: A survey
Sep 27, 2023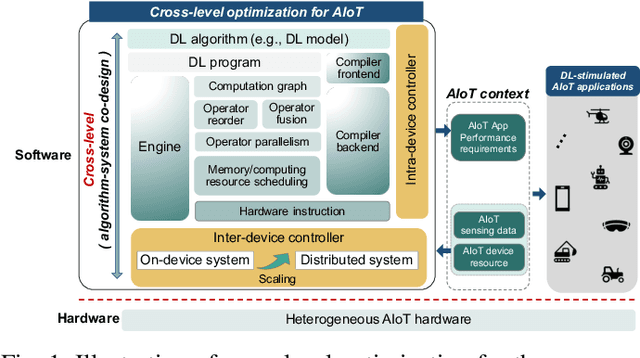
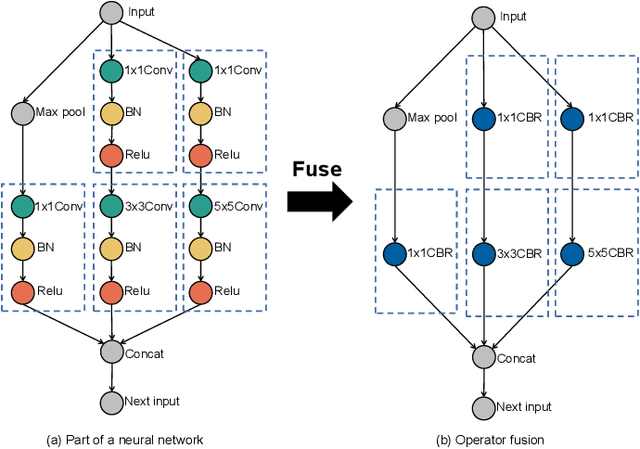
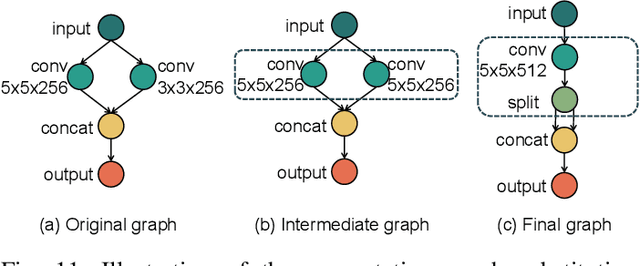
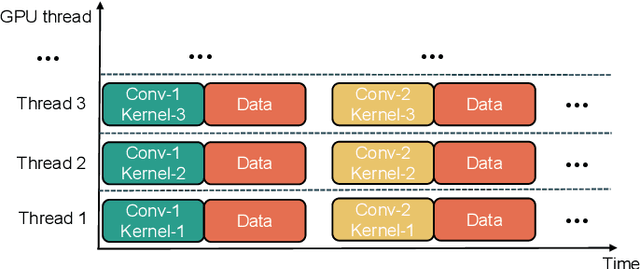
The emerging field of artificial intelligence of things (AIoT, AI+IoT) is driven by the widespread use of intelligent infrastructures and the impressive success of deep learning (DL). With the deployment of DL on various intelligent infrastructures featuring rich sensors and weak DL computing capabilities, a diverse range of AIoT applications has become possible. However, DL models are notoriously resource-intensive. Existing research strives to realize near-/realtime inference of AIoT live data and low-cost training using AIoT datasets on resource-scare infrastructures. Accordingly, the accuracy and responsiveness of DL models are bounded by resource availability. To this end, the algorithm-system co-design that jointly optimizes the resource-friendly DL models and model-adaptive system scheduling improves the runtime resource availability and thus pushes the performance boundary set by the standalone level. Unlike previous surveys on resource-friendly DL models or hand-crafted DL compilers/frameworks with partially fine-tuned components, this survey aims to provide a broader optimization space for more free resource-performance tradeoffs. The cross-level optimization landscape involves various granularity, including the DL model, computation graph, operator, memory schedule, and hardware instructor in both on-device and distributed paradigms. Furthermore, due to the dynamic nature of AIoT context, which includes heterogeneous hardware, agnostic sensing data, varying user-specified performance demands, and resource constraints, this survey explores the context-aware inter-/intra-device controllers for automatic cross-level adaptation. Additionally, we identify some potential directions for resource-efficient AIoT systems. By consolidating problems and techniques scattered over diverse levels, we aim to help readers understand their connections and stimulate further discussions.
Approximate and Weighted Data Reconstruction Attack in Federated Learning
Aug 13, 2023Federated Learning (FL) is a distributed learning paradigm that enables multiple clients to collaborate on building a machine learning model without sharing their private data. Although FL is considered privacy-preserved by design, recent data reconstruction attacks demonstrate that an attacker can recover clients' training data based on the parameters shared in FL. However, most existing methods fail to attack the most widely used horizontal Federated Averaging (FedAvg) scenario, where clients share model parameters after multiple local training steps. To tackle this issue, we propose an interpolation-based approximation method, which makes attacking FedAvg scenarios feasible by generating the intermediate model updates of the clients' local training processes. Then, we design a layer-wise weighted loss function to improve the data quality of reconstruction. We assign different weights to model updates in different layers concerning the neural network structure, with the weights tuned by Bayesian optimization. Finally, experimental results validate the superiority of our proposed approximate and weighted attack (AWA) method over the other state-of-the-art methods, as demonstrated by the substantial improvement in different evaluation metrics for image data reconstructions.
Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models
Jul 22, 2023


The demand for psychological counseling has grown significantly in recent years, particularly with the global outbreak of COVID-19, which has heightened the need for timely and professional mental health support. Online psychological counseling has emerged as the predominant mode of providing services in response to this demand. In this study, we propose the Psy-LLM framework, an AI-based system leveraging Large Language Models (LLMs) for question-answering in online psychological consultation. Our framework combines pre-trained LLMs with real-world professional Q&A from psychologists and extensively crawled psychological articles. The Psy-LLM framework serves as a front-end tool for healthcare professionals, allowing them to provide immediate responses and mindfulness activities to alleviate patient stress. Additionally, it functions as a screening tool to identify urgent cases requiring further assistance. We evaluated the framework using intrinsic metrics, such as perplexity, and extrinsic evaluation metrics, with human participant assessments of response helpfulness, fluency, relevance, and logic. The results demonstrate the effectiveness of the Psy-LLM framework in generating coherent and relevant answers to psychological questions. This article concludes by discussing the potential of large language models to enhance mental health support through AI technologies in online psychological consultation.