 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZixin Wang
In Search of Lost Online Test-time Adaptation: A Survey
Oct 31, 2023

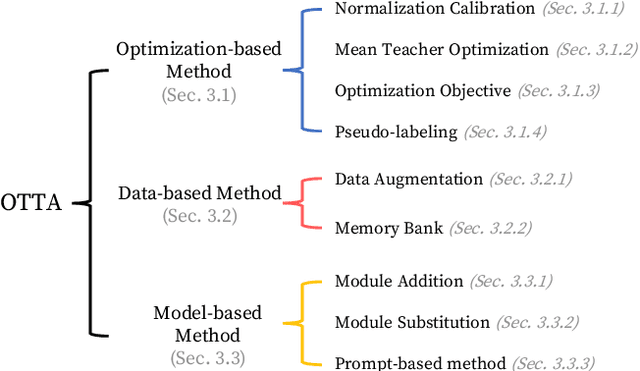

In this paper, we present a comprehensive survey on online test-time adaptation (OTTA), a paradigm focused on adapting machine learning models to novel data distributions upon batch arrival. Despite the proliferation of OTTA methods recently, the field is mired in issues like ambiguous settings, antiquated backbones, and inconsistent hyperparameter tuning, obfuscating the real challenges and making reproducibility elusive. For clarity and a rigorous comparison, we classify OTTA techniques into three primary categories and subject them to benchmarks using the potent Vision Transformer (ViT) backbone to discover genuinely effective strategies. Our benchmarks span not only conventional corrupted datasets such as CIFAR-10/100-C and ImageNet-C but also real-world shifts embodied in CIFAR-10.1 and CIFAR-10-Warehouse, encapsulating variations across search engines and synthesized data by diffusion models. To gauge efficiency in online scenarios, we introduce novel evaluation metrics, inclusive of FLOPs, shedding light on the trade-offs between adaptation accuracy and computational overhead. Our findings diverge from existing literature, indicating: (1) transformers exhibit heightened resilience to diverse domain shifts, (2) the efficacy of many OTTA methods hinges on ample batch sizes, and (3) stability in optimization and resistance to perturbations are critical during adaptation, especially when the batch size is 1. Motivated by these insights, we pointed out promising directions for future research. The source code will be made available.
Towards Open World Active Learning for 3D Object Detection
Oct 16, 2023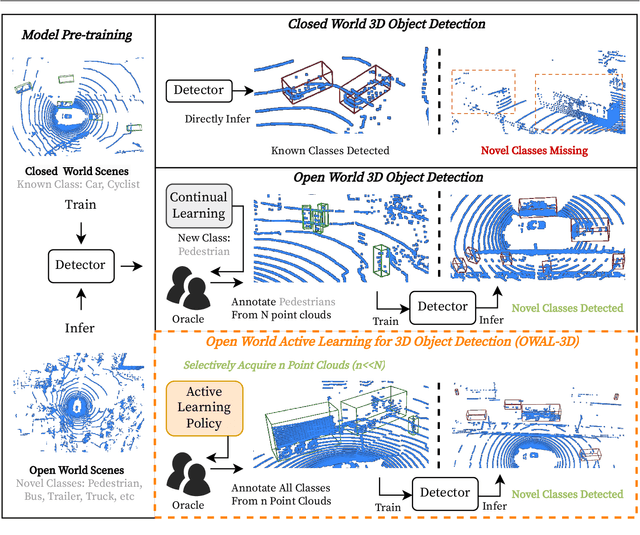
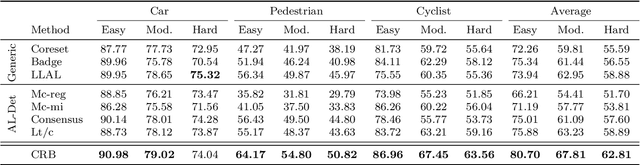
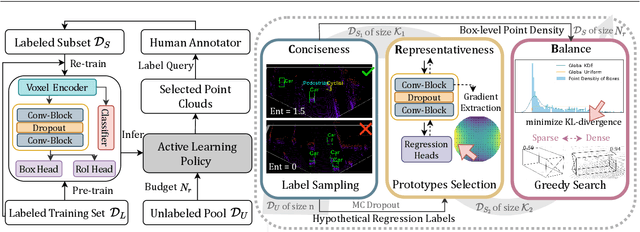
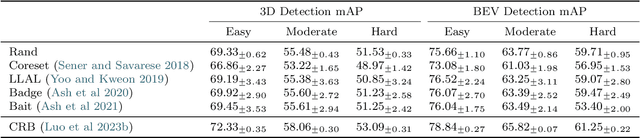
Significant strides have been made in closed world 3D object detection, testing systems in environments with known classes. However, the challenge arises in open world scenarios where new object classes appear. Existing efforts sequentially learn novel classes from streams of labeled data at a significant annotation cost, impeding efficient deployment to the wild. To seek effective solutions, we investigate a more practical yet challenging research task: Open World Active Learning for 3D Object Detection (OWAL-3D), aiming at selecting a small number of 3D boxes to annotate while maximizing detection performance on both known and unknown classes. The core difficulty centers on striking a balance between mining more unknown instances and minimizing the labeling expenses of point clouds. Empirically, our study finds the harmonious and inverse relationship between box quantities and their confidences can help alleviate the dilemma, avoiding the repeated selection of common known instances and focusing on uncertain objects that are potentially unknown. We unify both relational constraints into a simple and effective AL strategy namely OpenCRB, which guides to acquisition of informative point clouds with the least amount of boxes to label. Furthermore, we develop a comprehensive codebase for easy reproducing and future research, supporting 15 baseline methods (i.e., active learning, out-of-distribution detection and open world detection), 2 types of modern 3D detectors (i.e., one-stage SECOND and two-stage PV-RCNN) and 3 benchmark 3D datasets (i.e., KITTI, nuScenes and Waymo). Extensive experiments evidence that the proposed Open-CRB demonstrates superiority and flexibility in recognizing both novel and shared categories with very limited labeling costs, compared to state-of-the-art baselines.
Cal-SFDA: Source-Free Domain-adaptive Semantic Segmentation with Differentiable Expected Calibration Error
Aug 06, 2023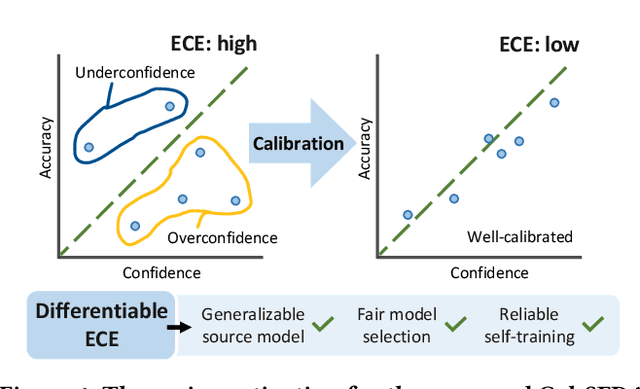
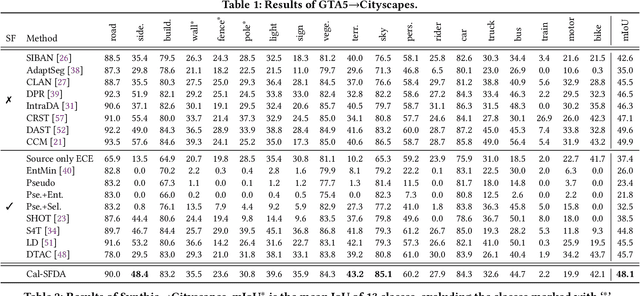
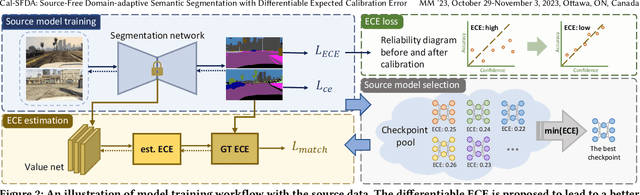
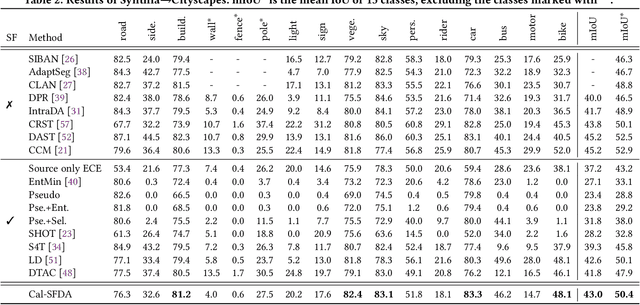
The prevalence of domain adaptive semantic segmentation has prompted concerns regarding source domain data leakage, where private information from the source domain could inadvertently be exposed in the target domain. To circumvent the requirement for source data, source-free domain adaptation has emerged as a viable solution that leverages self-training methods to pseudo-label high-confidence regions and adapt the model to the target data. However, the confidence scores obtained are often highly biased due to over-confidence and class-imbalance issues, which render both model selection and optimization problematic. In this paper, we propose a novel calibration-guided source-free domain adaptive semantic segmentation (Cal-SFDA) framework. The core idea is to estimate the expected calibration error (ECE) from the segmentation predictions, serving as a strong indicator of the model's generalization capability to the unlabeled target domain. The estimated ECE scores, in turn, assist the model training and fair selection in both source training and target adaptation stages. During model pre-training on the source domain, we ensure the differentiability of the ECE objective by leveraging the LogSumExp trick and using ECE scores to select the best source checkpoints for adaptation. To enable ECE estimation on the target domain without requiring labels, we train a value net for ECE estimation and apply statistic warm-up on its BatchNorm layers for stability. The estimated ECE scores assist in determining the reliability of prediction and enable class-balanced pseudo-labeling by positively guiding the adaptation progress and inhibiting potential error accumulation. Extensive experiments on two widely-used synthetic-to-real transfer tasks show that the proposed approach surpasses previous state-of-the-art by up to 5.25% of mIoU with fair model selection criteria.
Machine Learning for Large-Scale Optimization in 6G Wireless Networks
Jan 03, 2023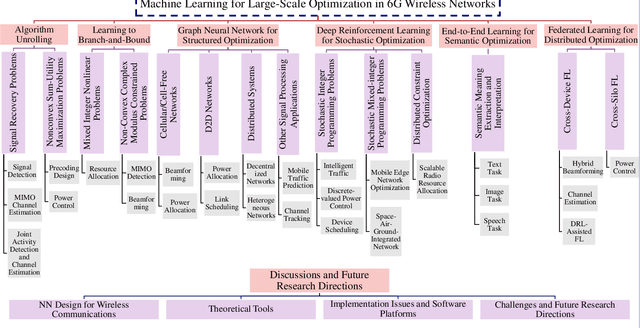

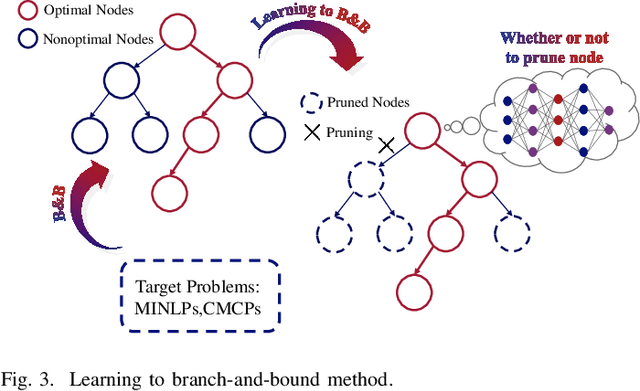
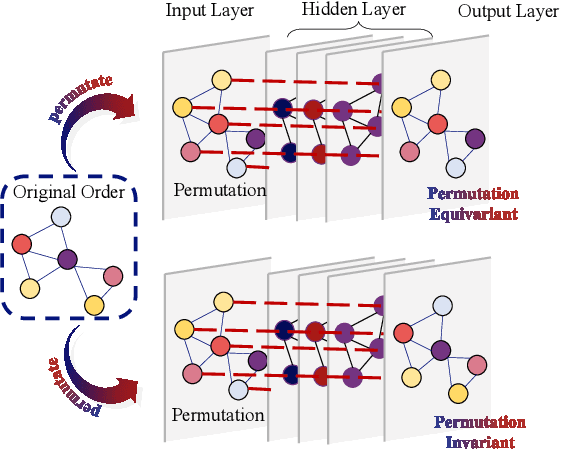
The sixth generation (6G) wireless systems are envisioned to enable the paradigm shift from "connected things" to "connected intelligence", featured by ultra high density, large-scale, dynamic heterogeneity, diversified functional requirements and machine learning capabilities, which leads to a growing need for highly efficient intelligent algorithms. The classic optimization-based algorithms usually require highly precise mathematical model of data links and suffer from poor performance with high computational cost in realistic 6G applications. Based on domain knowledge (e.g., optimization models and theoretical tools), machine learning (ML) stands out as a promising and viable methodology for many complex large-scale optimization problems in 6G, due to its superior performance, generalizability, computational efficiency and robustness. In this paper, we systematically review the most representative "learning to optimize" techniques in diverse domains of 6G wireless networks by identifying the inherent feature of the underlying optimization problem and investigating the specifically designed ML frameworks from the perspective of optimization. In particular, we will cover algorithm unrolling, learning to branch-and-bound, graph neural network for structured optimization, deep reinforcement learning for stochastic optimization, end-to-end learning for semantic optimization, as well as federated learning for distributed optimization, for solving challenging large-scale optimization problems arising from various important wireless applications. Through the in-depth discussion, we shed light on the excellent performance of ML-based optimization algorithms with respect to the classical methods, and provide insightful guidance to develop advanced ML techniques in 6G networks.
Discovering Domain Disentanglement for Generalized Multi-source Domain Adaptation
Jul 11, 2022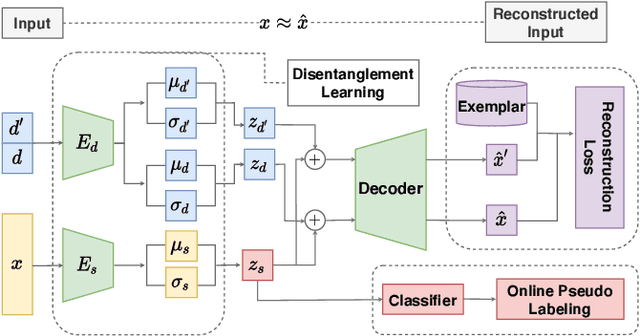



A typical multi-source domain adaptation (MSDA) approach aims to transfer knowledge learned from a set of labeled source domains, to an unlabeled target domain. Nevertheless, prior works strictly assume that each source domain shares the identical group of classes with the target domain, which could hardly be guaranteed as the target label space is not observable. In this paper, we consider a more versatile setting of MSDA, namely Generalized Multi-source Domain Adaptation, wherein the source domains are partially overlapped, and the target domain is allowed to contain novel categories that are not presented in any source domains. This new setting is more elusive than any existing domain adaptation protocols due to the coexistence of the domain and category shifts across the source and target domains. To address this issue, we propose a variational domain disentanglement (VDD) framework, which decomposes the domain representations and semantic features for each instance by encouraging dimension-wise independence. To identify the target samples of unknown classes, we leverage online pseudo labeling, which assigns the pseudo-labels to unlabeled target data based on the confidence scores. Quantitative and qualitative experiments conducted on two benchmark datasets demonstrate the validity of the proposed framework.
Knowledge-Guided Learning for Transceiver Design in Over-the-Air Federated Learning
Mar 28, 2022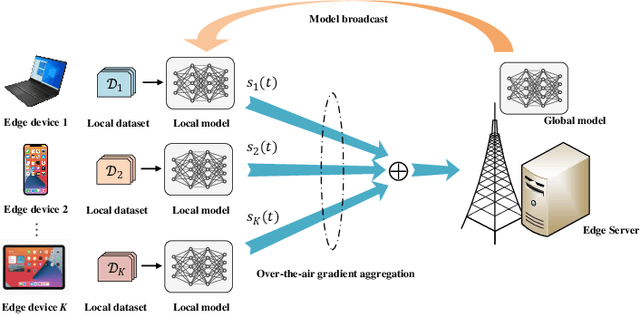

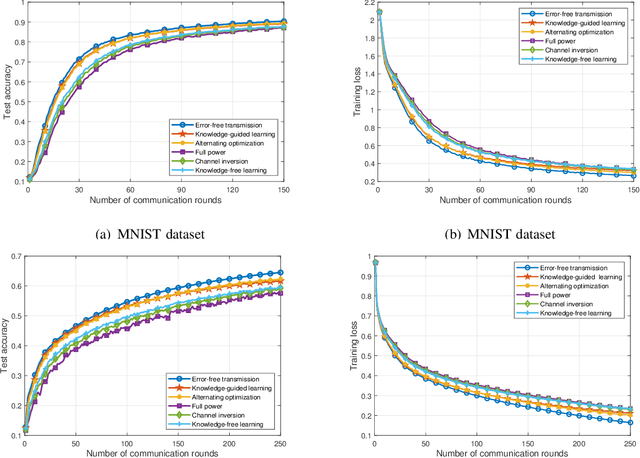

In this paper, we consider communication-efficient over-the-air federated learning (FL), where multiple edge devices with non-independent and identically distributed datasets perform multiple local iterations in each communication round and then concurrently transmit their updated gradients to an edge server over the same radio channel for global model aggregation using over-the-air computation (AirComp). We derive the upper bound of the time-average norm of the gradients to characterize the convergence of AirComp-assisted FL, which reveals the impact of the model aggregation errors accumulated over all communication rounds on convergence. Based on the convergence analysis, we formulate an optimization problem to minimize the upper bound to enhance the learning performance, followed by proposing an alternating optimization algorithm to facilitate the optimal transceiver design for AirComp-assisted FL. As the alternating optimization algorithm suffers from high computation complexity, we further develop a knowledge-guided learning algorithm that exploits the structure of the analytic expression of the optimal transmit power to achieve computation-efficient transceiver design. Simulation results demonstrate that the proposed knowledge-guided learning algorithm achieves a comparable performance as the alternating optimization algorithm, but with a much lower computation complexity. Moreover, both proposed algorithms outperform the baseline methods in terms of convergence speed and test accuracy.