 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZuchao Li
Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models
Apr 19, 2024
Adapter-based parameter-efficient transfer learning has achieved exciting results in vision-language models. Traditional adapter methods often require training or fine-tuning, facing challenges such as insufficient samples or resource limitations. While some methods overcome the need for training by leveraging image modality cache and retrieval, they overlook the text modality's importance and cross-modal cues for the efficient adaptation of parameters in visual-language models. This work introduces a cross-modal parameter-efficient approach named XMAdapter. XMAdapter establishes cache models for both text and image modalities. It then leverages retrieval through visual-language bimodal information to gather clues for inference. By dynamically adjusting the affinity ratio, it achieves cross-modal fusion, decoupling different modal similarities to assess their respective contributions. Additionally, it explores hard samples based on differences in cross-modal affinity and enhances model performance through adaptive adjustment of sample learning intensity. Extensive experimental results on benchmark datasets demonstrate that XMAdapter outperforms previous adapter-based methods significantly regarding accuracy, generalization, and efficiency.
Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
Apr 06, 2024The chain-of-thought technique has been received well in multi-modal tasks. It is a step-by-step linear reasoning process that adjusts the length of the chain to improve the performance of generated prompts. However, human thought processes are predominantly non-linear, as they encompass multiple aspects simultaneously and employ dynamic adjustment and updating mechanisms. Therefore, we propose a novel Aggregation-Graph-of-Thought (AGoT) mechanism for soft-prompt tuning in multi-modal representation learning. The proposed AGoT models the human thought process not only as a chain but also models each step as a reasoning aggregation graph to cope with the overlooked multiple aspects of thinking in single-step reasoning. This turns the entire reasoning process into prompt aggregation and prompt flow operations. Experiments show that our multi-modal model enhanced with AGoT soft-prompting achieves good results in several tasks such as text-image retrieval, visual question answering, and image recognition. In addition, we demonstrate that it has good domain generalization performance due to better reasoning.
Multi-modal Auto-regressive Modeling via Visual Words
Mar 12, 2024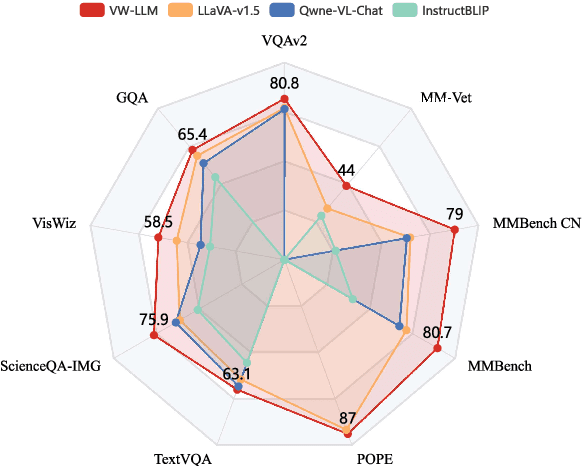
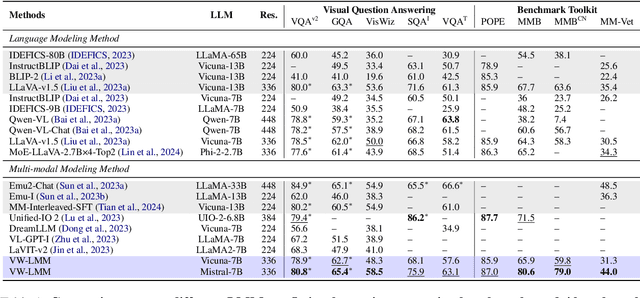


Large Language Models (LLMs), benefiting from the auto-regressive modelling approach performed on massive unannotated texts corpora, demonstrates powerful perceptual and reasoning capabilities. However, as for extending auto-regressive modelling to multi-modal scenarios to build Large Multi-modal Models (LMMs), there lies a great difficulty that the image information is processed in the LMM as continuous visual embeddings, which cannot obtain discrete supervised labels for classification. In this paper, we successfully perform multi-modal auto-regressive modeling with a unified objective for the first time. Specifically, we propose the concept of visual words, which maps the visual features to probability distributions over LLM's vocabulary, providing supervision information for visual modelling. We further explore the distribution of visual features in the semantic space within LMM and the possibility of using text embeddings to represent visual information. Experimental results and ablation studies on 5 VQA tasks and 4 benchmark toolkits validate the powerful performance of our proposed approach.
Sparse is Enough in Fine-tuning Pre-trained Large Language Model
Dec 19, 2023With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation, including Adapters, Bia-only, and the recently widely used Low-Rank Adaptation. Although these methods have demonstrated their effectiveness to some extent and have been widely applied, the underlying principles are still unclear. In this paper, we reveal the transition of loss landscape in the downstream domain from random initialization to pre-trained initialization, that is, from low-amplitude oscillation to high-amplitude oscillation. The parameter gradients exhibit a property akin to sparsity, where a small fraction of components dominate the total gradient norm, for instance, 1% of the components account for 99% of the gradient. This property ensures that the pre-trained model can easily find a flat minimizer which guarantees the model's ability to generalize even with a low number of trainable parameters. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
A Novel Energy based Model Mechanism for Multi-modal Aspect-Based Sentiment Analysis
Dec 15, 2023
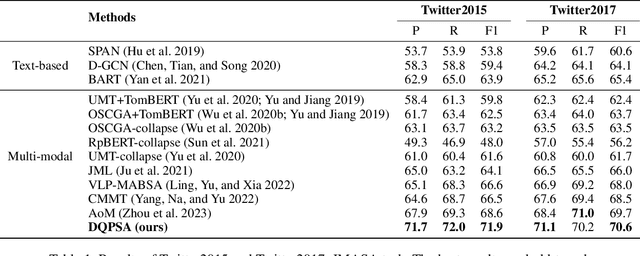
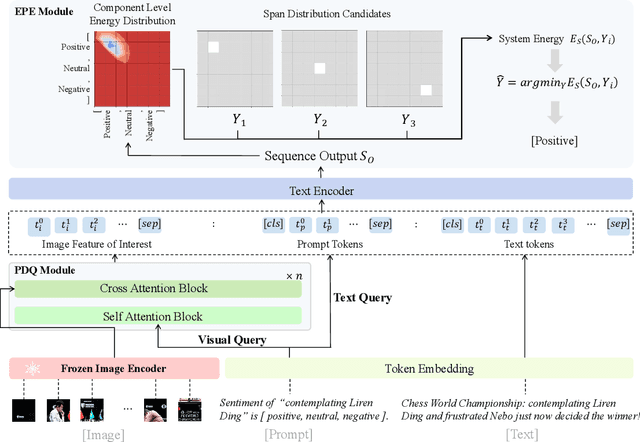
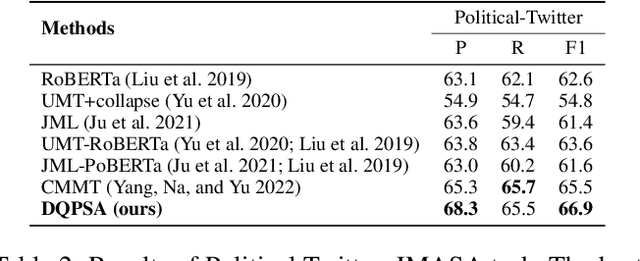
Multi-modal aspect-based sentiment analysis (MABSA) has recently attracted increasing attention. The span-based extraction methods, such as FSUIE, demonstrate strong performance in sentiment analysis due to their joint modeling of input sequences and target labels. However, previous methods still have certain limitations: (i) They ignore the difference in the focus of visual information between different analysis targets (aspect or sentiment). (ii) Combining features from uni-modal encoders directly may not be sufficient to eliminate the modal gap and can cause difficulties in capturing the image-text pairwise relevance. (iii) Existing span-based methods for MABSA ignore the pairwise relevance of target span boundaries. To tackle these limitations, we propose a novel framework called DQPSA for multi-modal sentiment analysis. Specifically, our model contains a Prompt as Dual Query (PDQ) module that uses the prompt as both a visual query and a language query to extract prompt-aware visual information and strengthen the pairwise relevance between visual information and the analysis target. Additionally, we introduce an Energy-based Pairwise Expert (EPE) module that models the boundaries pairing of the analysis target from the perspective of an Energy-based Model. This expert predicts aspect or sentiment span based on pairwise stability. Experiments on three widely used benchmarks demonstrate that DQPSA outperforms previous approaches and achieves a new state-of-the-art performance.
N-Gram Unsupervised Compoundation and Feature Injection for Better Symbolic Music Understanding
Dec 15, 2023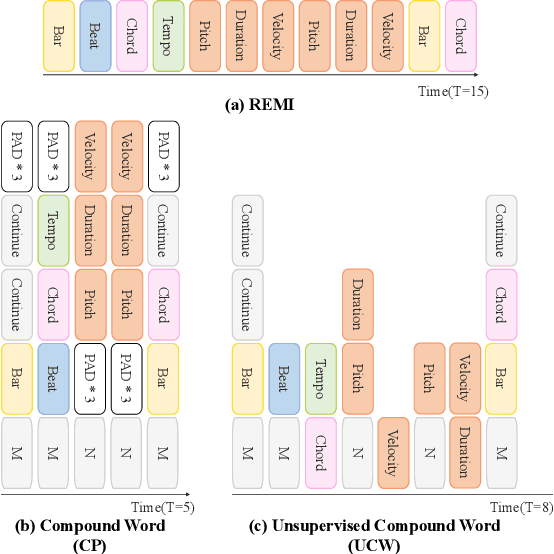
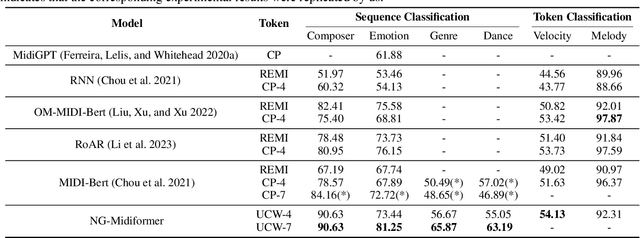
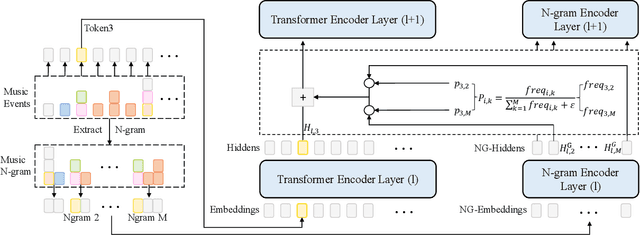
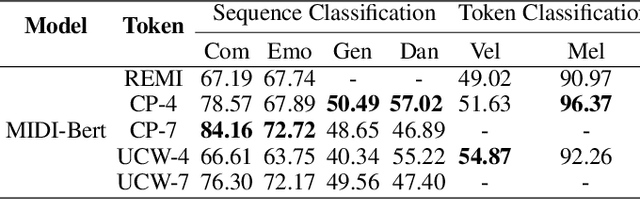
The first step to apply deep learning techniques for symbolic music understanding is to transform musical pieces (mainly in MIDI format) into sequences of predefined tokens like note pitch, note velocity, and chords. Subsequently, the sequences are fed into a neural sequence model to accomplish specific tasks. Music sequences exhibit strong correlations between adjacent elements, making them prime candidates for N-gram techniques from Natural Language Processing (NLP). Consider classical piano music: specific melodies might recur throughout a piece, with subtle variations each time. In this paper, we propose a novel method, NG-Midiformer, for understanding symbolic music sequences that leverages the N-gram approach. Our method involves first processing music pieces into word-like sequences with our proposed unsupervised compoundation, followed by using our N-gram Transformer encoder, which can effectively incorporate N-gram information to enhance the primary encoder part for better understanding of music sequences. The pre-training process on large-scale music datasets enables the model to thoroughly learn the N-gram information contained within music sequences, and subsequently apply this information for making inferences during the fine-tuning stage. Experiment on various datasets demonstrate the effectiveness of our method and achieved state-of-the-art performance on a series of music understanding downstream tasks. The code and model weights will be released at https://github.com/CinqueOrigin/NG-Midiformer.
Multi-modal Latent Space Learning for Chain-of-Thought Reasoning in Language Models
Dec 14, 2023
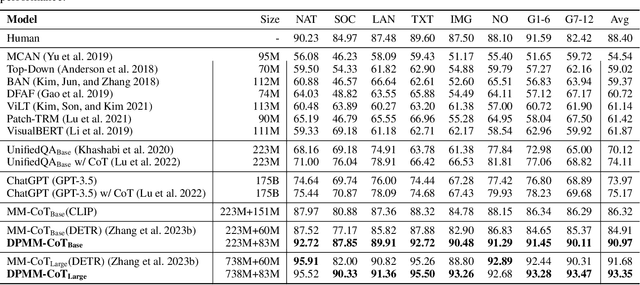
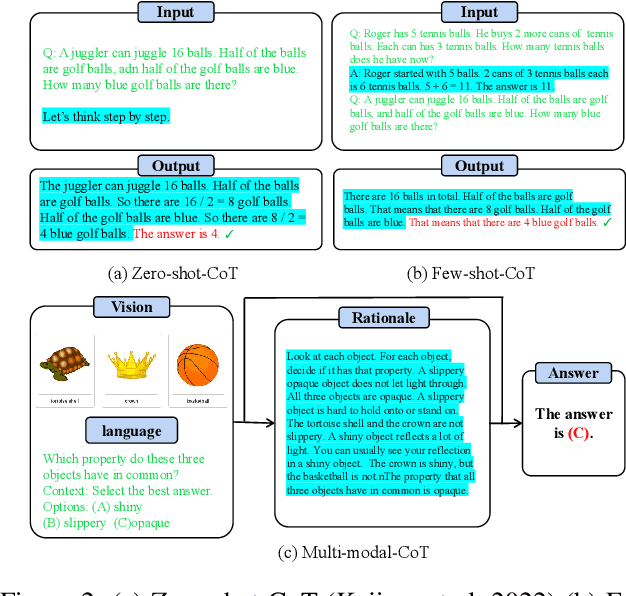
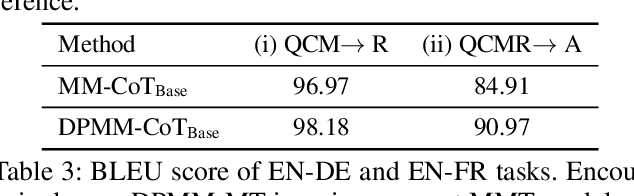
Chain-of-thought (CoT) reasoning has exhibited impressive performance in language models for solving complex tasks and answering questions. However, many real-world questions require multi-modal information, such as text and images. Previous research on multi-modal CoT has primarily focused on extracting fixed image features from off-the-shelf vision models and then fusing them with text using attention mechanisms. This approach has limitations because these vision models were not designed for complex reasoning tasks and do not align well with language thoughts. To overcome this limitation, we introduce a novel approach for multi-modal CoT reasoning that utilizes latent space learning via diffusion processes to generate effective image features that align with language thoughts. Our method fuses image features and text representations at a deep level and improves the complex reasoning ability of multi-modal CoT. We demonstrate the efficacy of our proposed method on multi-modal ScienceQA and machine translation benchmarks, achieving state-of-the-art performance on ScienceQA. Overall, our approach offers a more robust and effective solution for multi-modal reasoning in language models, enhancing their ability to tackle complex real-world problems.
Bootstrapping Interactive Image-Text Alignment for Remote Sensing Image Captioning
Dec 02, 2023Recently, remote sensing image captioning has gained significant attention in the remote sensing community. Due to the significant differences in spatial resolution of remote sensing images, existing methods in this field have predominantly concentrated on the fine-grained extraction of remote sensing image features, but they cannot effectively handle the semantic consistency between visual features and textual features. To efficiently align the image-text, we propose a novel two-stage vision-language pre-training-based approach to bootstrap interactive image-text alignment for remote sensing image captioning, called BITA, which relies on the design of a lightweight interactive Fourier Transformer to better align remote sensing image-text features. The Fourier layer in the interactive Fourier Transformer is capable of extracting multi-scale features of remote sensing images in the frequency domain, thereby reducing the redundancy of remote sensing visual features. Specifically, the first stage involves preliminary alignment through image-text contrastive learning, which aligns the learned multi-scale remote sensing features from the interactive Fourier Transformer with textual features. In the second stage, the interactive Fourier Transformer connects the frozen image encoder with a large language model. Then, prefix causal language modeling is utilized to guide the text generation process using visual features. Ultimately, across the UCM-caption, RSICD, and NWPU-caption datasets, the experimental results clearly demonstrate that BITA outperforms other advanced comparative approaches. The code is available at https://github.com/yangcong356/BITA.
ArcMMLU: A Library and Information Science Benchmark for Large Language Models
Nov 30, 2023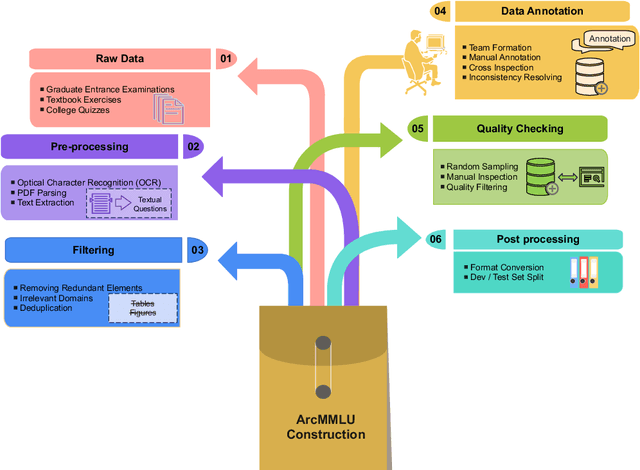
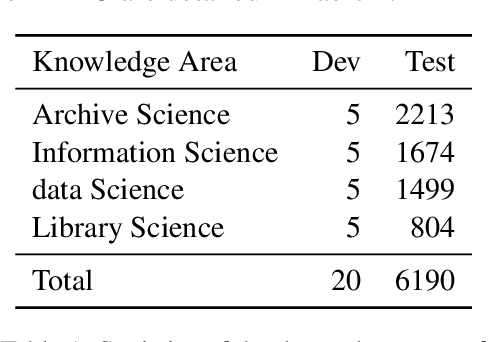

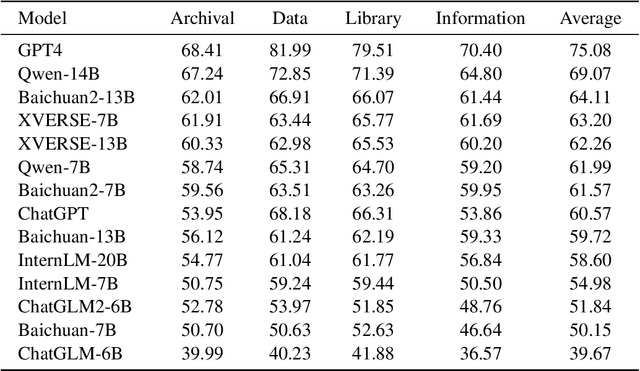
In light of the rapidly evolving capabilities of large language models (LLMs), it becomes imperative to develop rigorous domain-specific evaluation benchmarks to accurately assess their capabilities. In response to this need, this paper introduces ArcMMLU, a specialized benchmark tailored for the Library & Information Science (LIS) domain in Chinese. This benchmark aims to measure the knowledge and reasoning capability of LLMs within four key sub-domains: Archival Science, Data Science, Library Science, and Information Science. Following the format of MMLU/CMMLU, we collected over 6,000 high-quality questions for the compilation of ArcMMLU. This extensive compilation can reflect the diverse nature of the LIS domain and offer a robust foundation for LLM evaluation. Our comprehensive evaluation reveals that while most mainstream LLMs achieve an average accuracy rate above 50% on ArcMMLU, there remains a notable performance gap, suggesting substantial headroom for refinement in LLM capabilities within the LIS domain. Further analysis explores the effectiveness of few-shot examples on model performance and highlights challenging questions where models consistently underperform, providing valuable insights for targeted improvements. ArcMMLU fills a critical gap in LLM evaluations within the Chinese LIS domain and paves the way for future development of LLMs tailored to this specialized area.
Enhancing Visually-Rich Document Understanding via Layout Structure Modeling
Aug 15, 2023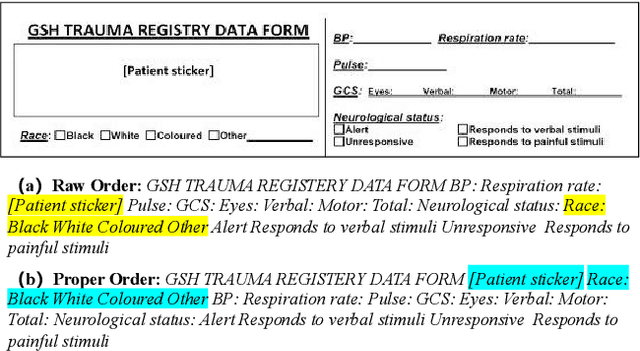
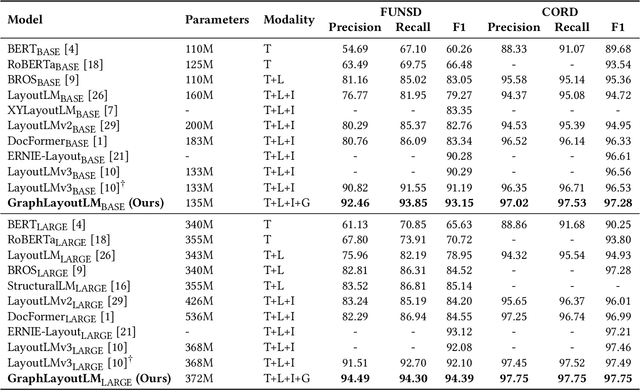
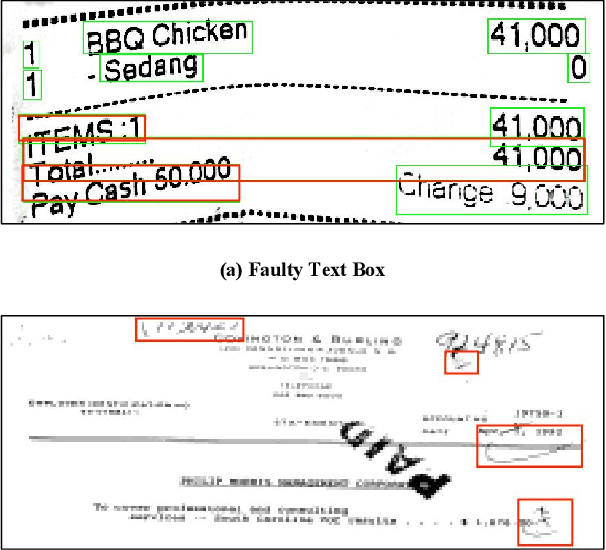
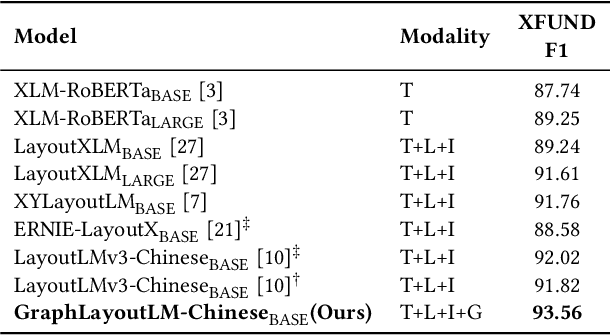
In recent years, the use of multi-modal pre-trained Transformers has led to significant advancements in visually-rich document understanding. However, existing models have mainly focused on features such as text and vision while neglecting the importance of layout relationship between text nodes. In this paper, we propose GraphLayoutLM, a novel document understanding model that leverages the modeling of layout structure graph to inject document layout knowledge into the model. GraphLayoutLM utilizes a graph reordering algorithm to adjust the text sequence based on the graph structure. Additionally, our model uses a layout-aware multi-head self-attention layer to learn document layout knowledge. The proposed model enables the understanding of the spatial arrangement of text elements, improving document comprehension. We evaluate our model on various benchmarks, including FUNSD, XFUND and CORD, and achieve state-of-the-art results among these datasets. Our experimental results demonstrate that our proposed method provides a significant improvement over existing approaches and showcases the importance of incorporating layout information into document understanding models. We also conduct an ablation study to investigate the contribution of each component of our model. The results show that both the graph reordering algorithm and the layout-aware multi-head self-attention layer play a crucial role in achieving the best performance.