 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Gardner": models, code, and papers
Future Language Modeling from Temporal Document History
Apr 16, 2024
Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
The Gardner problem and cycle slipping bifurcation for type 2 phase-locked loops
Dec 02, 2021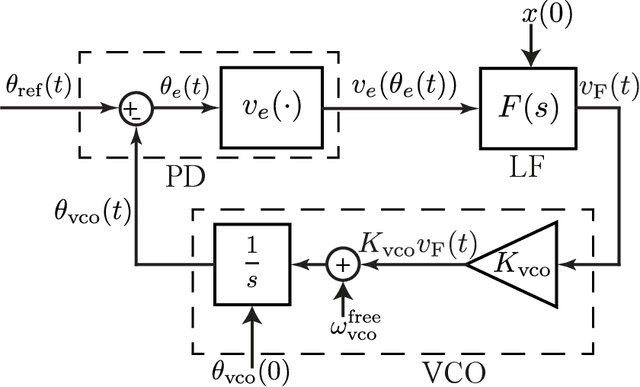
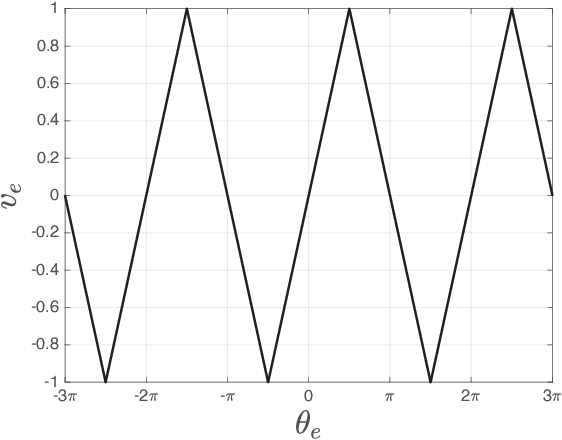
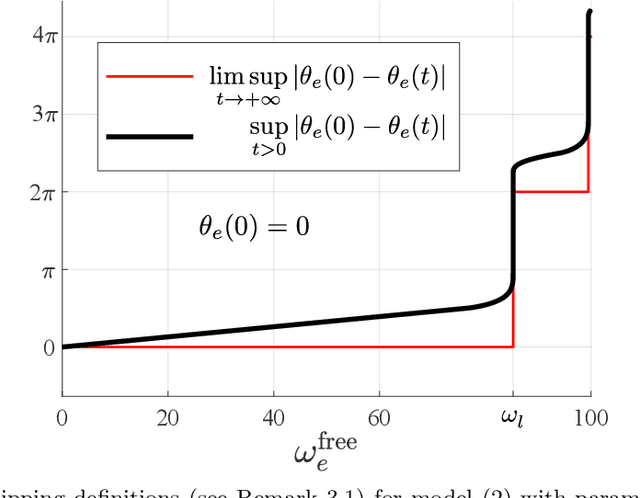
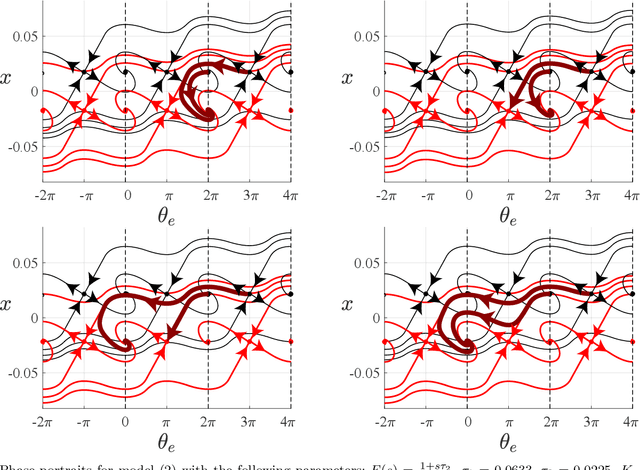
In the present work, a second-order type 2 PLL with a piecewise-linear phase detector characteristic is analysed. An exact solution to the Gardner problem on the lock-in range is obtained for the considered model. The solution is based on a study of cycle slipping bifurcation and improves well-known engineering estimates.
Training neural networks with structured noise improves classification and generalization
Mar 02, 2023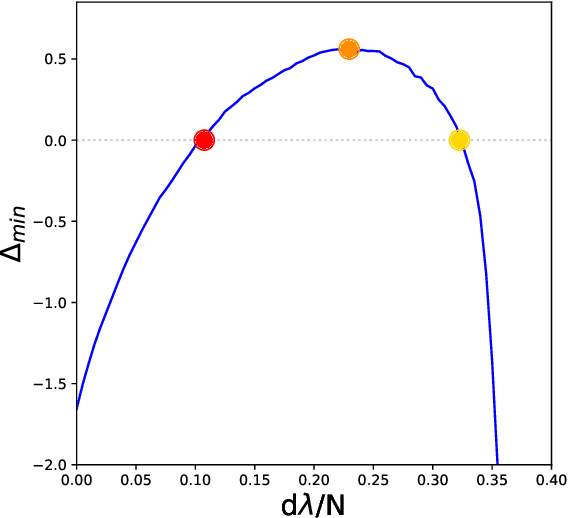
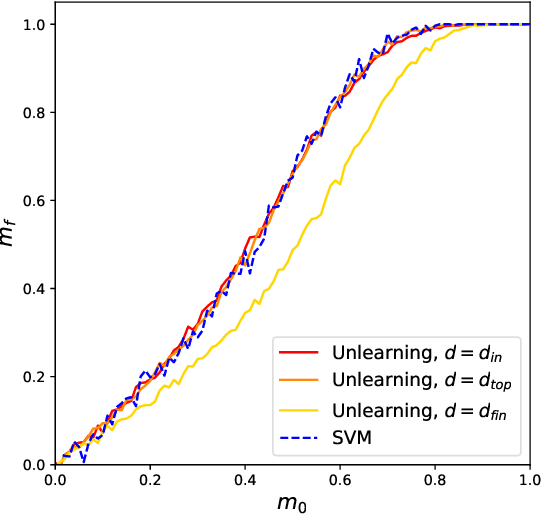
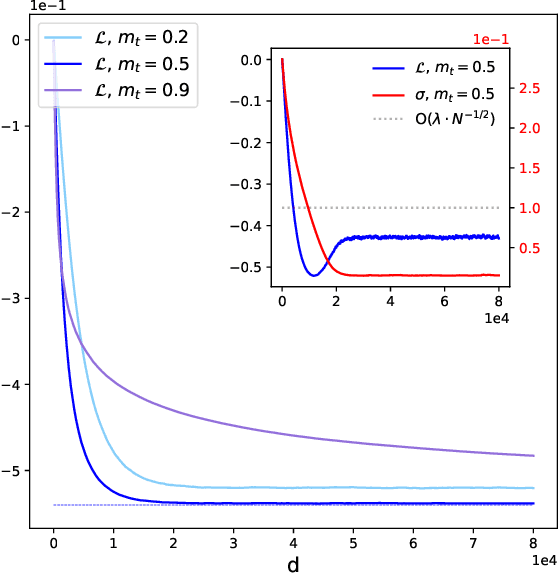
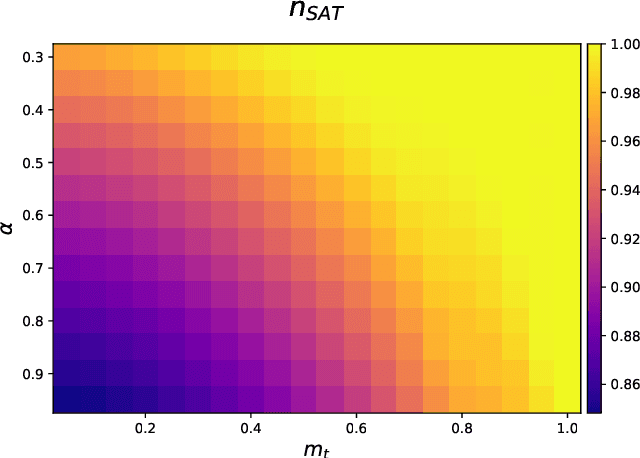
The beneficial role of noise in learning is nowadays a consolidated concept in the field of artificial neural networks. The training-with-noise algorithm proposed by Gardner and collaborators is an emblematic example of a noise injection procedure in recurrent networks. We show how adding structure into noisy training data can substantially improve memory performance, allowing to approach perfect classification and maximal basins of attraction. We also prove that the so-called unlearning rule coincides with the training-with-noise algorithm when noise is maximal and data are fixed points of the network dynamics. Moreover, a sampling scheme for optimal noisy data is proposed and implemented to outperform both the training-with-noise and the unlearning procedures.
Uninformative Input Features and Counterfactual Invariance: Two Perspectives on Spurious Correlations in Natural Language
Apr 09, 2022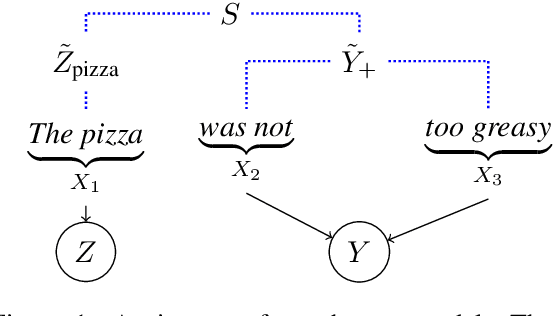
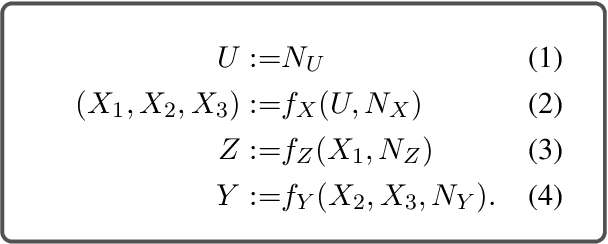
Spurious correlations are a threat to the trustworthiness of natural language processing systems, motivating research into methods for identifying and eliminating them. Gardner et al (2021) argue that the compositional nature of language implies that \emph{all} correlations between labels and individual input features are spurious. This paper analyzes this proposal in the context of a toy example, demonstrating three distinct conditions that can give rise to feature-label correlations in a simple PCFG. Linking the toy example to a structured causal model shows that (1) feature-label correlations can arise even when the label is invariant to interventions on the feature, and (2) feature-label correlations may be absent even when the label is sensitive to interventions on the feature. Because input features will be individually correlated with labels in all but very rare circumstances, domain knowledge must be applied to identify spurious correlations that pose genuine robustness threats.
Alpha-Mini: Minichess Agent with Deep Reinforcement Learning
Dec 22, 2021
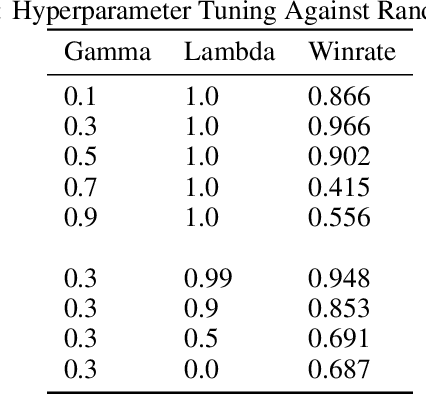
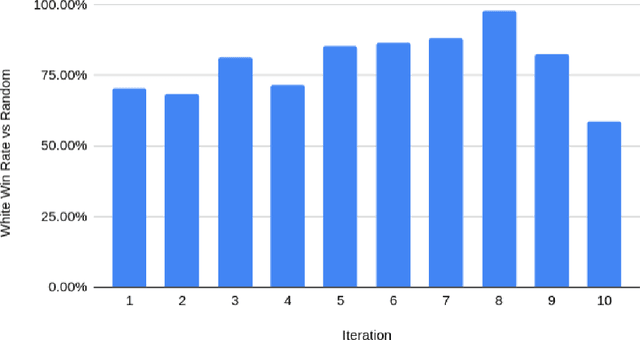
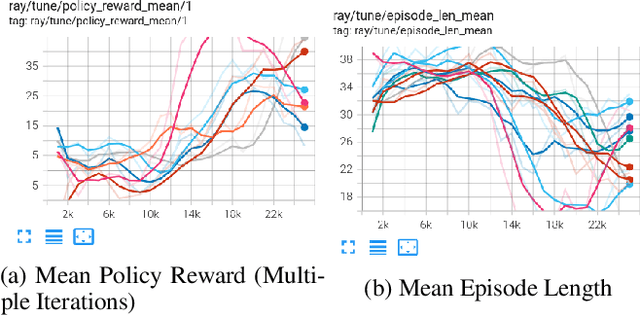
We train an agent to compete in the game of Gardner minichess, a downsized variation of chess played on a 5x5 board. We motivated and applied a SOTA actor-critic method Proximal Policy Optimization with Generalized Advantage Estimation. Our initial task centered around training the agent against a random agent. Once we obtained reasonable performance, we then adopted a version of iterative policy improvement adopted by AlphaGo to pit the agent against increasingly stronger versions of itself, and evaluate the resulting performance gain. The final agent achieves a near (.97) perfect win rate against a random agent. We also explore the effects of pretraining the network using a collection of positions obtained via self-play.
On the Limitations of Dataset Balancing: The Lost Battle Against Spurious Correlations
Apr 27, 2022


Recent work has shown that deep learning models in NLP are highly sensitive to low-level correlations between simple features and specific output labels, leading to overfitting and lack of generalization. To mitigate this problem, a common practice is to balance datasets by adding new instances or by filtering out "easy" instances (Sakaguchi et al., 2020), culminating in a recent proposal to eliminate single-word correlations altogether (Gardner et al., 2021). In this opinion paper, we identify that despite these efforts, increasingly-powerful models keep exploiting ever-smaller spurious correlations, and as a result even balancing all single-word features is insufficient for mitigating all of these correlations. In parallel, a truly balanced dataset may be bound to "throw the baby out with the bathwater" and miss important signal encoding common sense and world knowledge. We highlight several alternatives to dataset balancing, focusing on enhancing datasets with richer contexts, allowing models to abstain and interact with users, and turning from large-scale fine-tuning to zero- or few-shot setups.
Performance of Bayesian linear regression in a model with mismatch
Jul 14, 2021For a model of high-dimensional linear regression with random design, we analyze the performance of an estimator given by the mean of a log-concave Bayesian posterior distribution with gaussian prior. The model is mismatched in the following sense: like the model assumed by the statistician, the labels-generating process is linear in the input data, but both the classifier ground-truth prior and gaussian noise variance are unknown to her. This inference model can be rephrased as a version of the Gardner model in spin glasses and, using the cavity method, we provide fixed point equations for various overlap order parameters, yielding in particular an expression for the mean-square reconstruction error on the classifier (under an assumption of uniqueness of solutions). As a direct corollary we obtain an expression for the free energy. Similar models have already been studied by Shcherbina and Tirozzi and by Talagrand, but our arguments are more straightforward and some assumptions are relaxed. An interesting consequence of our analysis is that in the random design setting of ridge regression, the performance of the posterior mean is independent of the noise variance (or "temperature") assumed by the statistician, and matches the one of the usual (zero temperature) ridge estimator.
Statistical Mechanics of Neural Processing of Object Manifolds
Jun 01, 2021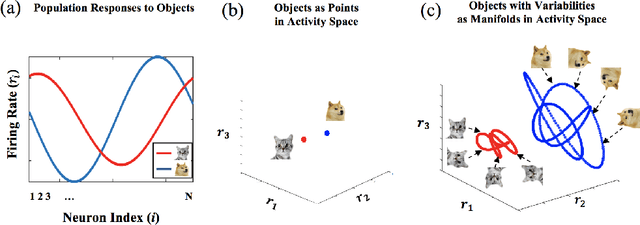
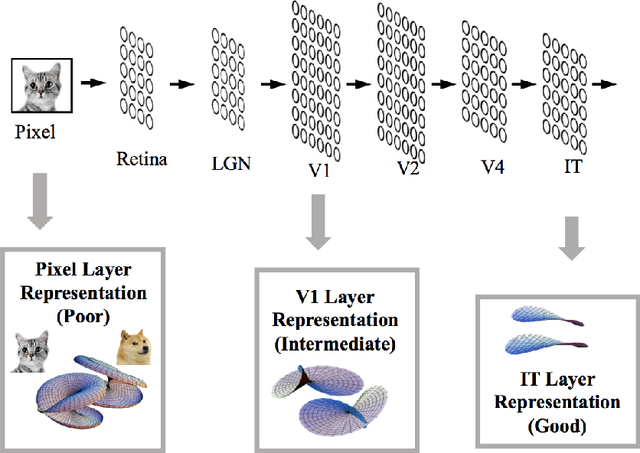
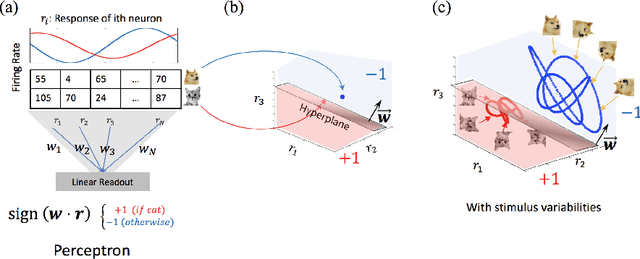
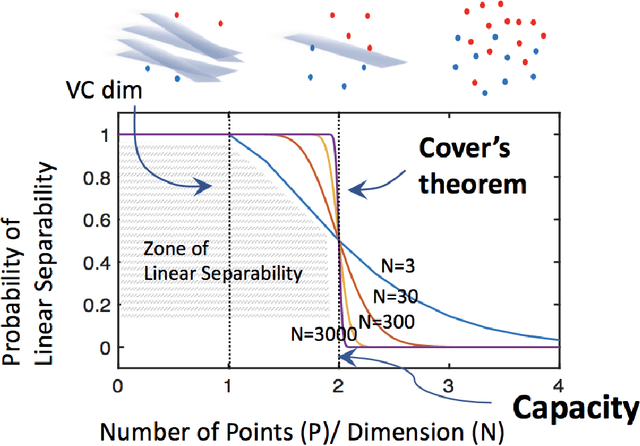
Invariant object recognition is one of the most fundamental cognitive tasks performed by the brain. In the neural state space, different objects with stimulus variabilities are represented as different manifolds. In this geometrical perspective, object recognition becomes the problem of linearly separating different object manifolds. In feedforward visual hierarchy, it has been suggested that the object manifold representations are reformatted across the layers, to become more linearly separable. Thus, a complete theory of perception requires characterizing the ability of linear readout networks to classify object manifolds from variable neural responses. A theory of the perceptron of isolated points was pioneered by E. Gardner who formulated it as a statistical mechanics problem and analyzed it using replica theory. In this thesis, we generalize Gardner's analysis and establish a theory of linear classification of manifolds synthesizing statistical and geometric properties of high dimensional signals. [..] Next, we generalize our theory further to linear classification of general perceptual manifolds, such as point clouds. We identify that the capacity of a manifold is determined that effective radius, R_M, and effective dimension, D_M. Finally, we show extensions relevant for applications to real data, incorporating correlated manifolds, heterogenous manifold geometries, sparse labels and nonlinear classifications. Then, we demonstrate how object-based manifolds transform in standard deep networks. This thesis lays the groundwork for a computational theory of neuronal processing of objects, providing quantitative measures for linear separability of object manifolds. We hope this theory will provide new insights into the computational principles underlying processing of sensory representations in biological and artificial neural networks.
Rethinking the objectives of extractive question answering
Aug 28, 2020
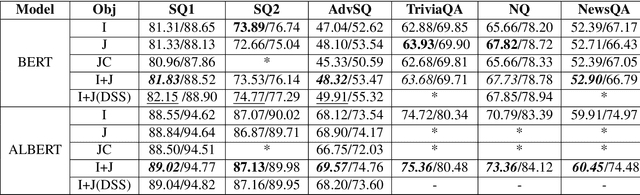
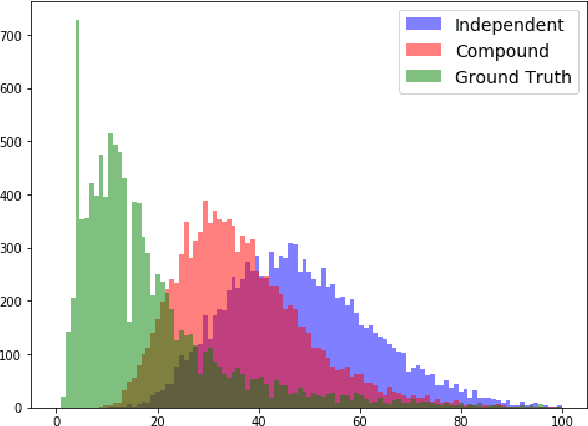
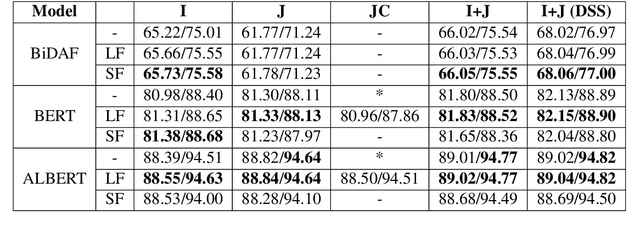
This paper describes two generally applicable approaches towards the significant improvement of the performance of state-of-the-art extractive question answering (EQA) systems. Firstly, contrary to a common belief, it demonstrates that using the objective with independence assumption for span probability $P(a_s,a_e) = P(a_s)P(a_e)$ of span starting at position $a_s$ and ending at position $a_e$ may have adverse effects. Therefore we propose a new compound objective that models joint probability $P(a_s,a_e)$ directly, while still keeping the objective with independency assumption as an auxiliary objective. Our second approach shows the beneficial effect of distantly semi-supervised shared-normalization objective known from (Clark and Gardner, 2017). We show that normalizing over a set of documents similar to the golden passage, and marginalizing over all ground-truth answer string positions leads to the improvement of results from smaller statistical models. Our results are supported via experiments with three QA models (BidAF, BERT, ALBERT) over six datasets. The proposed approaches do not use any additional data. Our code, analysis, pretrained models, and individual results will be available online.