 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoy Schwartz
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
Mar 31, 2024
It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require significantly more time and compute during inference. This begs the question: what happens when both models operate under the same budget? (e.g., compute, run-time). To address this question, we analyze code generation LLMs of various sizes and make comparisons such as running a 70B model once vs. generating five outputs from a 13B model and selecting one. Our findings reveal that, in a standard unit-test setup, the repeated use of smaller models can yield consistent improvements, with gains of up to 15% across five tasks. On the other hand, in scenarios where unit-tests are unavailable, a ranking-based selection of candidates from the smaller model falls short of the performance of a single output from larger ones. Our results highlight the potential of using smaller models instead of larger ones, and the importance of studying approaches for ranking LLM outputs.
Transformers are Multi-State RNNs
Jan 11, 2024Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only transformers can in fact be conceptualized as infinite multi-state RNNs - an RNN variant with unlimited hidden state size. We further show that pretrained transformers can be converted into $\textit{finite}$ multi-state RNNs by fixing the size of their hidden state. We observe that several existing transformers cache compression techniques can be framed as such conversion policies, and introduce a novel policy, TOVA, which is simpler compared to these policies. Our experiments with several long range tasks indicate that TOVA outperforms all other baseline policies, while being nearly on par with the full (infinite) model, and using in some cases only $\frac{1}{8}$ of the original cache size. Our results indicate that transformer decoder LLMs often behave in practice as RNNs. They also lay out the option of mitigating one of their most painful computational bottlenecks - the size of their cache memory. We publicly release our code at https://github.com/schwartz-lab-NLP/TOVA.
Read, Look or Listen? What's Needed for Solving a Multimodal Dataset
Jul 06, 2023

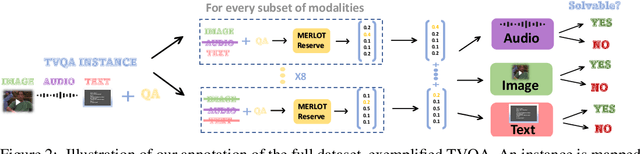
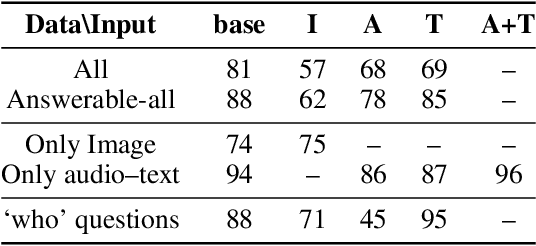
The prevalence of large-scale multimodal datasets presents unique challenges in assessing dataset quality. We propose a two-step method to analyze multimodal datasets, which leverages a small seed of human annotation to map each multimodal instance to the modalities required to process it. Our method sheds light on the importance of different modalities in datasets, as well as the relationship between them. We apply our approach to TVQA, a video question-answering dataset, and discover that most questions can be answered using a single modality, without a substantial bias towards any specific modality. Moreover, we find that more than 70% of the questions are solvable using several different single-modality strategies, e.g., by either looking at the video or listening to the audio, highlighting the limited integration of multiple modalities in TVQA. We leverage our annotation and analyze the MERLOT Reserve, finding that it struggles with image-based questions compared to text and audio, but also with auditory speaker identification. Based on our observations, we introduce a new test set that necessitates multiple modalities, observing a dramatic drop in model performance. Our methodology provides valuable insights into multimodal datasets and highlights the need for the development of more robust models.
Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023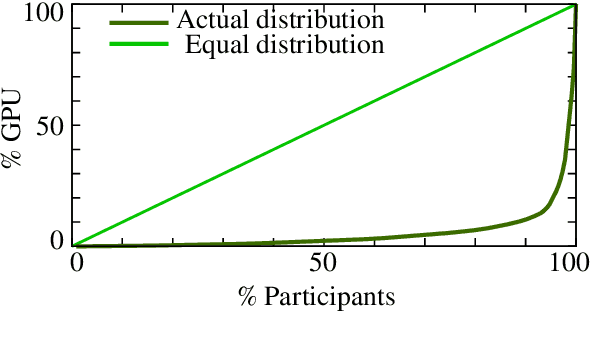

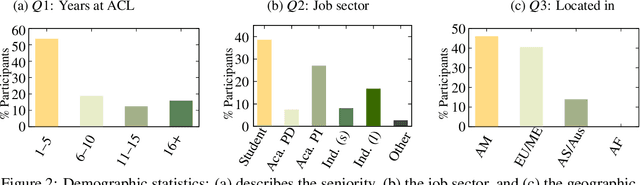
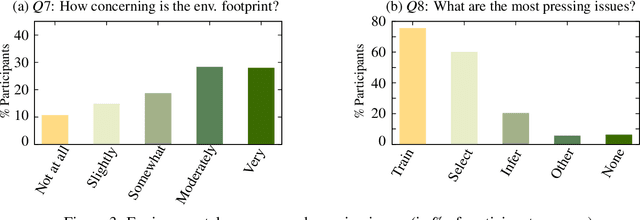
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
Morphosyntactic probing of multilingual BERT models
Jun 09, 2023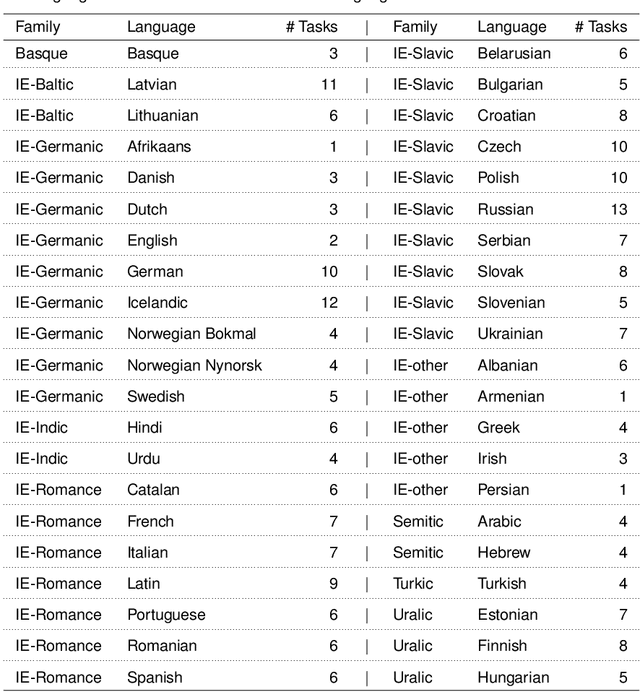
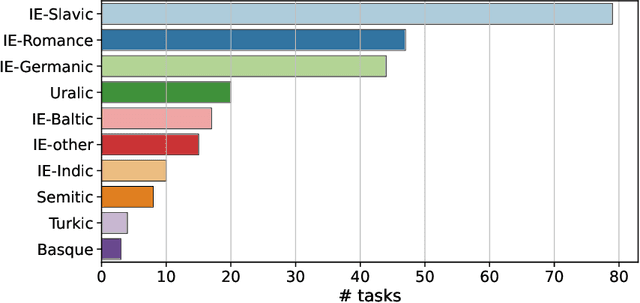
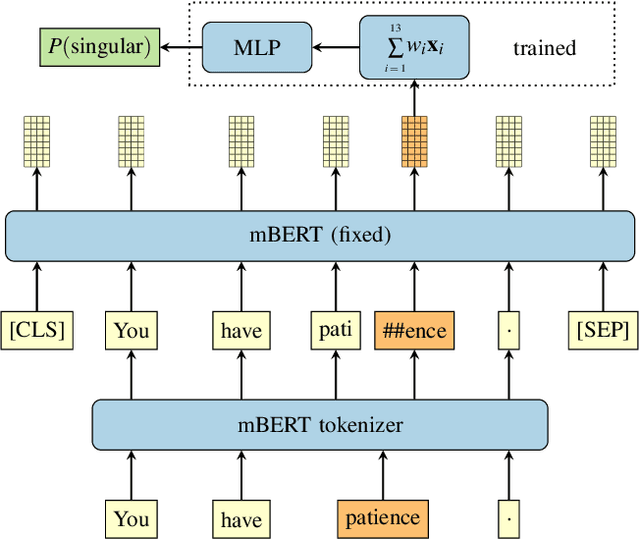
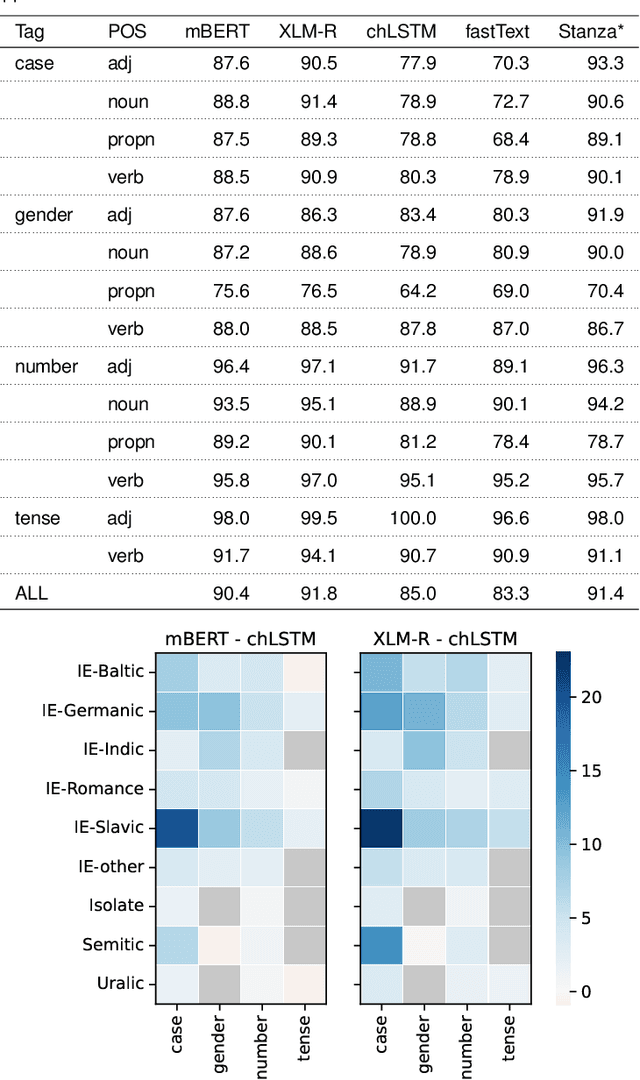
We introduce an extensive dataset for multilingual probing of morphological information in language models (247 tasks across 42 languages from 10 families), each consisting of a sentence with a target word and a morphological tag as the desired label, derived from the Universal Dependencies treebanks. We find that pre-trained Transformer models (mBERT and XLM-RoBERTa) learn features that attain strong performance across these tasks. We then apply two methods to locate, for each probing task, where the disambiguating information resides in the input. The first is a new perturbation method that masks various parts of context; the second is the classical method of Shapley values. The most intriguing finding that emerges is a strong tendency for the preceding context to hold more information relevant to the prediction than the following context.
Finding the SWEET Spot: Analysis and Improvement of Adaptive Inference in Low Resource Settings
Jun 04, 2023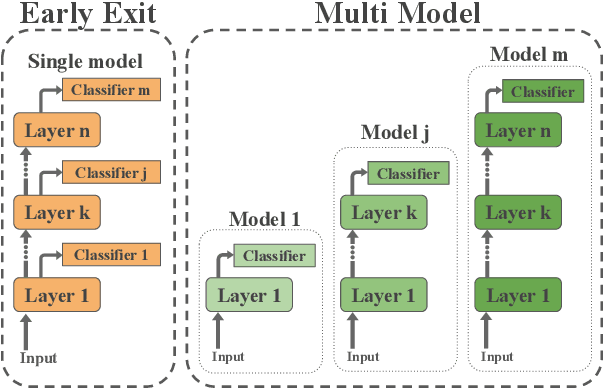
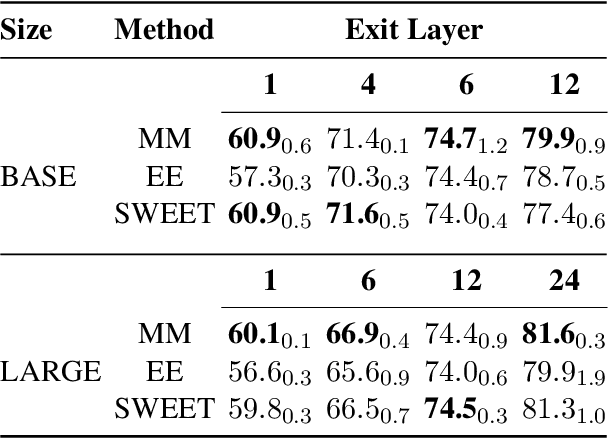
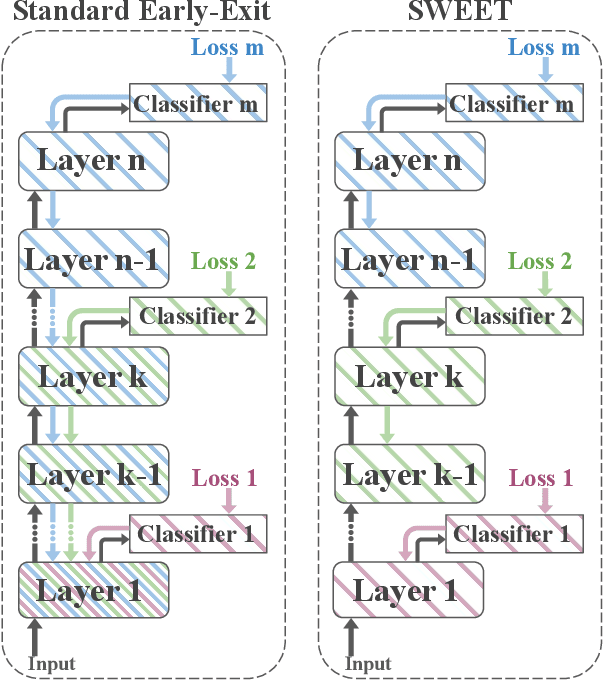
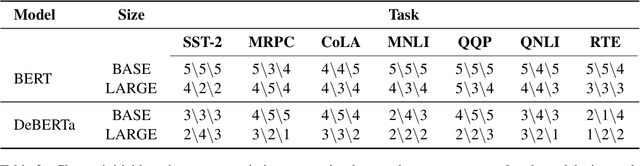
Adaptive inference is a simple method for reducing inference costs. The method works by maintaining multiple classifiers of different capacities, and allocating resources to each test instance according to its difficulty. In this work, we compare the two main approaches for adaptive inference, Early-Exit and Multi-Model, when training data is limited. First, we observe that for models with the same architecture and size, individual Multi-Model classifiers outperform their Early-Exit counterparts by an average of 2.3%. We show that this gap is caused by Early-Exit classifiers sharing model parameters during training, resulting in conflicting gradient updates of model weights. We find that despite this gap, Early-Exit still provides a better speed-accuracy trade-off due to the overhead of the Multi-Model approach. To address these issues, we propose SWEET (Separating Weights in Early Exit Transformers), an Early-Exit fine-tuning method that assigns each classifier its own set of unique model weights, not updated by other classifiers. We compare SWEET's speed-accuracy curve to standard Early-Exit and Multi-Model baselines and find that it outperforms both methods at fast speeds while maintaining comparable scores to Early-Exit at slow speeds. Moreover, SWEET individual classifiers outperform Early-Exit ones by 1.1% on average. SWEET enjoys the benefits of both methods, paving the way for further reduction of inference costs in NLP.
Fighting Bias with Bias: Promoting Model Robustness by Amplifying Dataset Biases
May 30, 2023NLP models often rely on superficial cues known as dataset biases to achieve impressive performance, and can fail on examples where these biases do not hold. Recent work sought to develop robust, unbiased models by filtering biased examples from training sets. In this work, we argue that such filtering can obscure the true capabilities of models to overcome biases, which might never be removed in full from the dataset. We suggest that in order to drive the development of models robust to subtle biases, dataset biases should be amplified in the training set. We introduce an evaluation framework defined by a bias-amplified training set and an anti-biased test set, both automatically extracted from existing datasets. Experiments across three notions of bias, four datasets and two models show that our framework is substantially more challenging for models than the original data splits, and even more challenging than hand-crafted challenge sets. Our evaluation framework can use any existing dataset, even those considered obsolete, to test model robustness. We hope our work will guide the development of robust models that do not rely on superficial biases and correlations. To this end, we publicly release our code and data.
Textually Pretrained Speech Language Models
May 22, 2023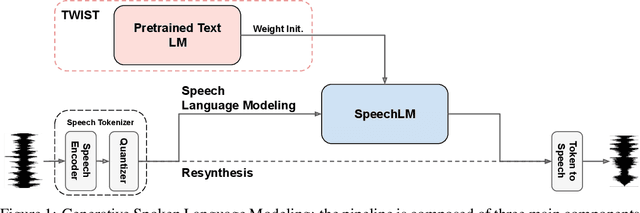

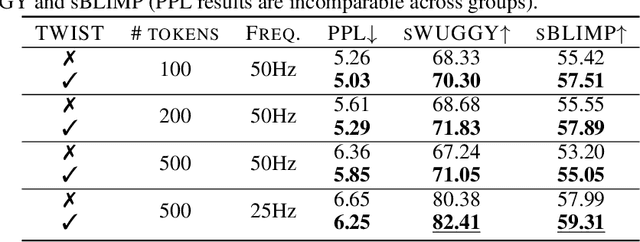
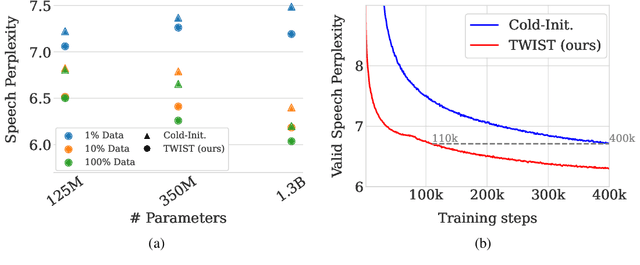
Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
Breaking Common Sense: WHOOPS! A Vision-and-Language Benchmark of Synthetic and Compositional Images
Mar 14, 2023


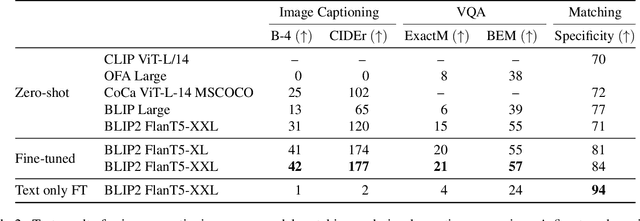
Weird, unusual, and uncanny images pique the curiosity of observers because they challenge commonsense. For example, an image released during the 2022 world cup depicts the famous soccer stars Lionel Messi and Cristiano Ronaldo playing chess, which playfully violates our expectation that their competition should occur on the football field. Humans can easily recognize and interpret these unconventional images, but can AI models do the same? We introduce WHOOPS!, a new dataset and benchmark for visual commonsense. The dataset is comprised of purposefully commonsense-defying images created by designers using publicly-available image generation tools like Midjourney. We consider several tasks posed over the dataset. In addition to image captioning, cross-modal matching, and visual question answering, we introduce a difficult explanation generation task, where models must identify and explain why a given image is unusual. Our results show that state-of-the-art models such as GPT3 and BLIP2 still lag behind human performance on WHOOPS!. We hope our dataset will inspire the development of AI models with stronger visual commonsense reasoning abilities. Data, models and code are available at the project website: whoops-benchmark.github.io
VASR: Visual Analogies of Situation Recognition
Dec 08, 2022


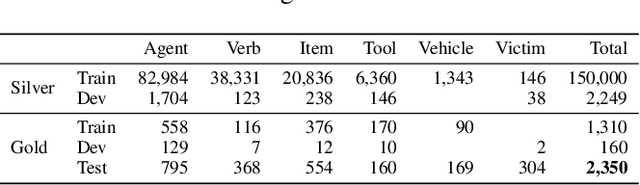
A core process in human cognition is analogical mapping: the ability to identify a similar relational structure between different situations. We introduce a novel task, Visual Analogies of Situation Recognition, adapting the classical word-analogy task into the visual domain. Given a triplet of images, the task is to select an image candidate B' that completes the analogy (A to A' is like B to what?). Unlike previous work on visual analogy that focused on simple image transformations, we tackle complex analogies requiring understanding of scenes. We leverage situation recognition annotations and the CLIP model to generate a large set of 500k candidate analogies. Crowdsourced annotations for a sample of the data indicate that humans agree with the dataset label ~80% of the time (chance level 25%). Furthermore, we use human annotations to create a gold-standard dataset of 3,820 validated analogies. Our experiments demonstrate that state-of-the-art models do well when distractors are chosen randomly (~86%), but struggle with carefully chosen distractors (~53%, compared to 90% human accuracy). We hope our dataset will encourage the development of new analogy-making models. Website: https://vasr-dataset.github.io/