 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYonatan Bitton
TALC: Time-Aligned Captions for Multi-Scene Text-to-Video Generation
May 07, 2024
Recent advances in diffusion-based generative modeling have led to the development of text-to-video (T2V) models that can generate high-quality videos conditioned on a text prompt. Most of these T2V models often produce single-scene video clips that depict an entity performing a particular action (e.g., `a red panda climbing a tree'). However, it is pertinent to generate multi-scene videos since they are ubiquitous in the real-world (e.g., `a red panda climbing a tree' followed by `the red panda sleeps on the top of the tree'). To generate multi-scene videos from the pretrained T2V model, we introduce Time-Aligned Captions (TALC) framework. Specifically, we enhance the text-conditioning mechanism in the T2V architecture to recognize the temporal alignment between the video scenes and scene descriptions. For instance, we condition the visual features of the earlier and later scenes of the generated video with the representations of the first scene description (e.g., `a red panda climbing a tree') and second scene description (e.g., `the red panda sleeps on the top of the tree'), respectively. As a result, we show that the T2V model can generate multi-scene videos that adhere to the multi-scene text descriptions and be visually consistent (e.g., entity and background). Further, we finetune the pretrained T2V model with multi-scene video-text data using the TALC framework. We show that the TALC-finetuned model outperforms the baseline methods by 15.5 points in the overall score, which averages visual consistency and text adherence using human evaluation. The project website is https://talc-mst2v.github.io/.
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
May 05, 2024Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
Mar 02, 2024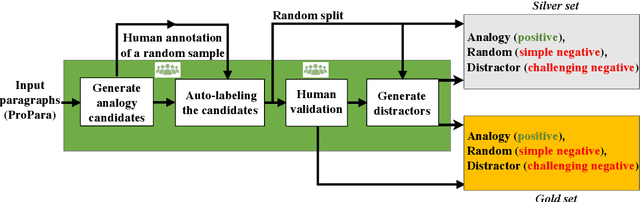



Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.
Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment
Dec 05, 2023While existing image-text alignment models reach high quality binary assessments, they fall short of pinpointing the exact source of misalignment. In this paper, we present a method to provide detailed textual and visual explanation of detected misalignments between text-image pairs. We leverage large language models and visual grounding models to automatically construct a training set that holds plausible misaligned captions for a given image and corresponding textual explanations and visual indicators. We also publish a new human curated test set comprising ground-truth textual and visual misalignment annotations. Empirical results show that fine-tuning vision language models on our training set enables them to articulate misalignments and visually indicate them within images, outperforming strong baselines both on the binary alignment classification and the explanation generation tasks. Our method code and human curated test set are available at: https://mismatch-quest.github.io/
VideoCon: Robust Video-Language Alignment via Contrast Captions
Nov 15, 2023Despite being (pre)trained on a massive amount of data, state-of-the-art video-language alignment models are not robust to semantically-plausible contrastive changes in the video captions. Our work addresses this by identifying a broad spectrum of contrast misalignments, such as replacing entities, actions, and flipping event order, which alignment models should be robust against. To this end, we introduce the VideoCon, a video-language alignment dataset constructed by a large language model that generates plausible contrast video captions and explanations for differences between original and contrast video captions. Then, a generative video-language model is finetuned with VideoCon to assess video-language entailment and generate explanations. Our VideoCon-based alignment model significantly outperforms current models. It exhibits a 12-point increase in AUC for the video-language alignment task on human-generated contrast captions. Finally, our model sets new state of the art zero-shot performance in temporally-extensive video-language tasks such as text-to-video retrieval (SSv2-Temporal) and video question answering (ATP-Hard). Moreover, our model shows superior performance on novel videos and human-crafted captions and explanations. Our code and data are available at https://github.com/Hritikbansal/videocon.
VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use
Aug 12, 2023


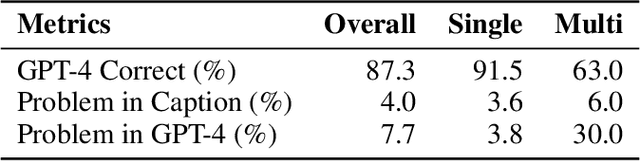
We introduce VisIT-Bench (Visual InsTruction Benchmark), a benchmark for evaluation of instruction-following vision-language models for real-world use. Our starting point is curating 70 'instruction families' that we envision instruction tuned vision-language models should be able to address. Extending beyond evaluations like VQAv2 and COCO, tasks range from basic recognition to game playing and creative generation. Following curation, our dataset comprises 592 test queries, each with a human-authored instruction-conditioned caption. These descriptions surface instruction-specific factors, e.g., for an instruction asking about the accessibility of a storefront for wheelchair users, the instruction-conditioned caption describes ramps/potential obstacles. These descriptions enable 1) collecting human-verified reference outputs for each instance; and 2) automatic evaluation of candidate multimodal generations using a text-only LLM, aligning with human judgment. We quantify quality gaps between models and references using both human and automatic evaluations; e.g., the top-performing instruction-following model wins against the GPT-4 reference in just 27% of the comparison. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at visit-bench.github.io.
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Aug 07, 2023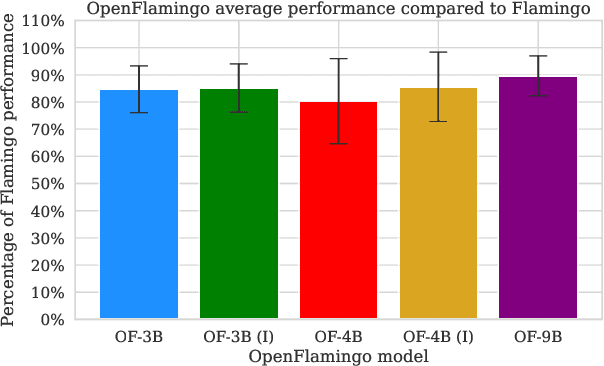

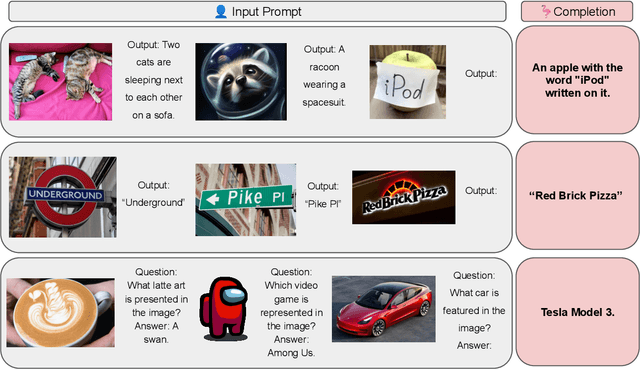

We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
Read, Look or Listen? What's Needed for Solving a Multimodal Dataset
Jul 06, 2023

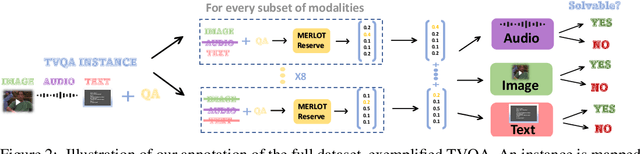
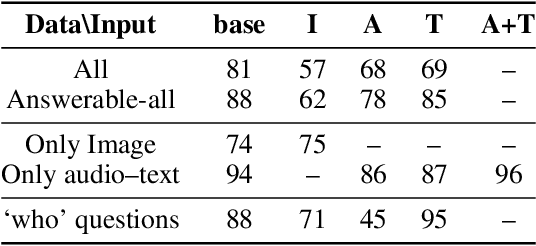
The prevalence of large-scale multimodal datasets presents unique challenges in assessing dataset quality. We propose a two-step method to analyze multimodal datasets, which leverages a small seed of human annotation to map each multimodal instance to the modalities required to process it. Our method sheds light on the importance of different modalities in datasets, as well as the relationship between them. We apply our approach to TVQA, a video question-answering dataset, and discover that most questions can be answered using a single modality, without a substantial bias towards any specific modality. Moreover, we find that more than 70% of the questions are solvable using several different single-modality strategies, e.g., by either looking at the video or listening to the audio, highlighting the limited integration of multiple modalities in TVQA. We leverage our annotation and analyze the MERLOT Reserve, finding that it struggles with image-based questions compared to text and audio, but also with auditory speaker identification. Based on our observations, we introduce a new test set that necessitates multiple modalities, observing a dramatic drop in model performance. Our methodology provides valuable insights into multimodal datasets and highlights the need for the development of more robust models.