 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitchell Wortsman
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024
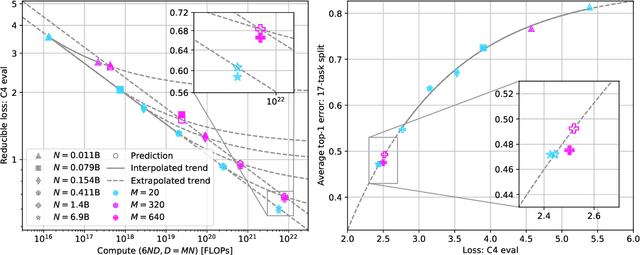
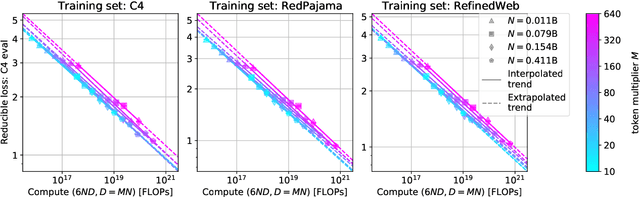

Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Small-scale proxies for large-scale Transformer training instabilities
Sep 25, 2023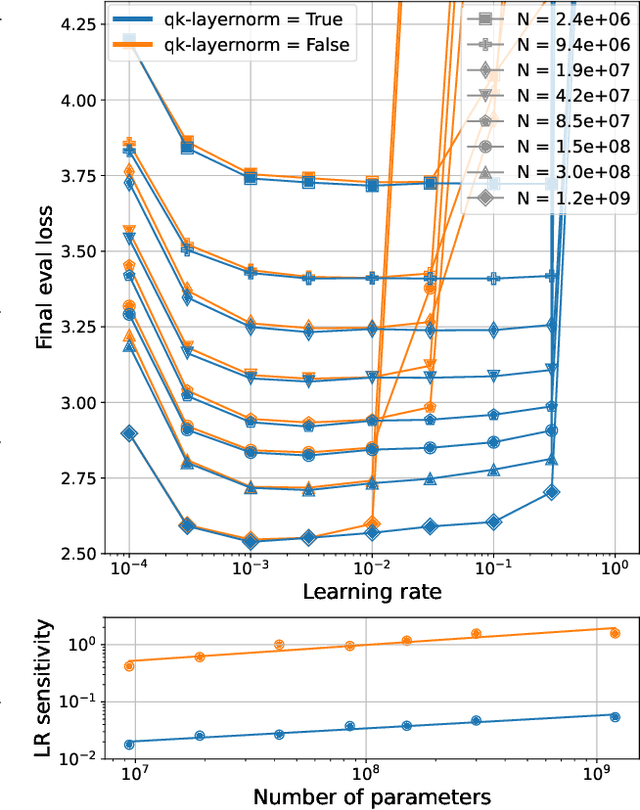
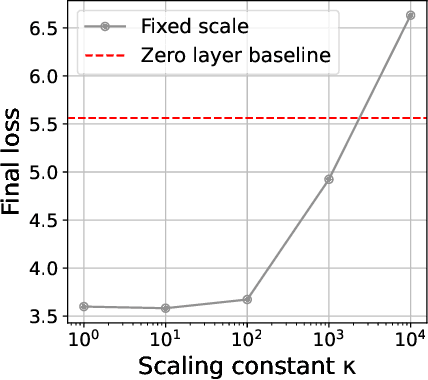
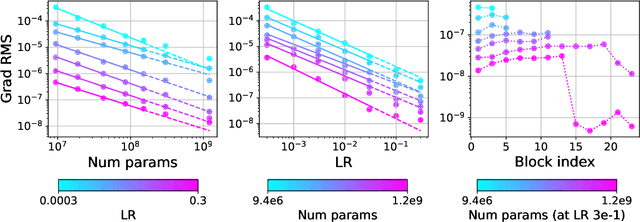
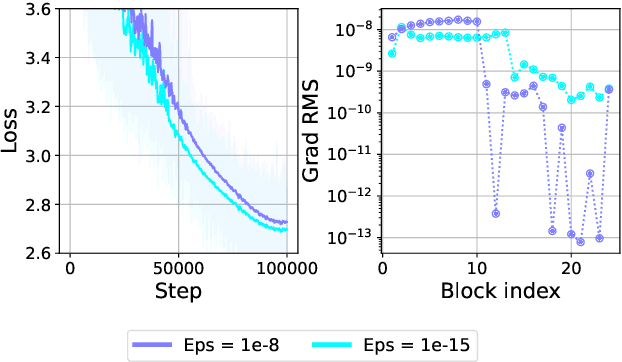
Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although the causes of such instabilities are of scientific interest, the amount of resources required to reproduce them has made investigation difficult. In this work, we seek ways to reproduce and study training stability and instability at smaller scales. First, we focus on two sources of training instability described in previous work: the growth of logits in attention layers (Dehghani et al., 2023) and divergence of the output logits from the log probabilities (Chowdhery et al., 2022). By measuring the relationship between learning rate and loss across scales, we show that these instabilities also appear in small models when training at high learning rates, and that mitigations previously employed at large scales are equally effective in this regime. This prompts us to investigate the extent to which other known optimizer and model interventions influence the sensitivity of the final loss to changes in the learning rate. To this end, we study methods such as warm-up, weight decay, and the $\mu$Param (Yang et al., 2022), and combine techniques to train small models that achieve similar losses across orders of magnitude of learning rate variation. Finally, to conclude our exploration we study two cases where instabilities can be predicted before they emerge by examining the scaling behavior of model activation and gradient norms.
Replacing softmax with ReLU in Vision Transformers
Sep 15, 2023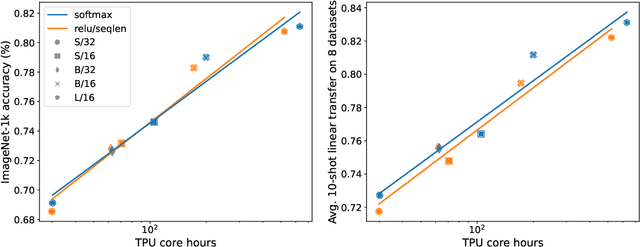
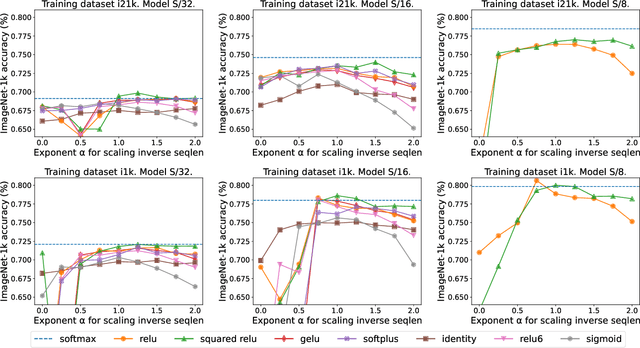
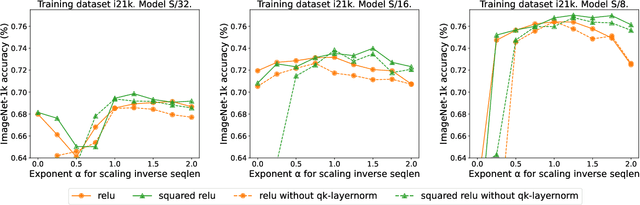
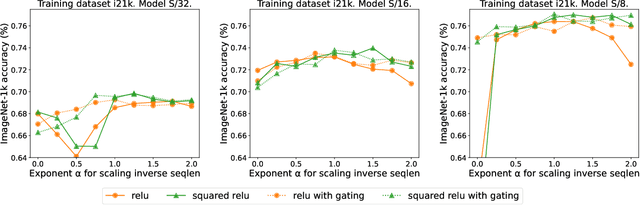
Previous research observed accuracy degradation when replacing the attention softmax with a point-wise activation such as ReLU. In the context of vision transformers, we find that this degradation is mitigated when dividing by sequence length. Our experiments training small to large vision transformers on ImageNet-21k indicate that ReLU-attention can approach or match the performance of softmax-attention in terms of scaling behavior as a function of compute.
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Aug 07, 2023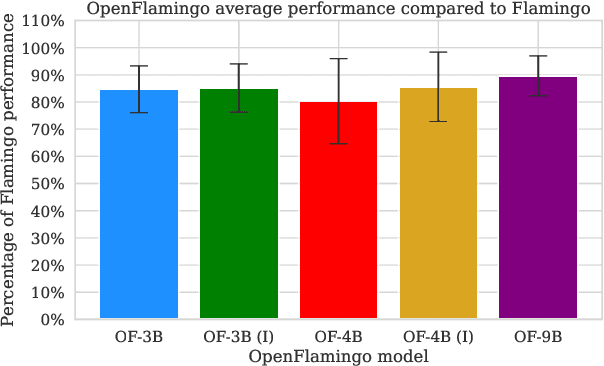

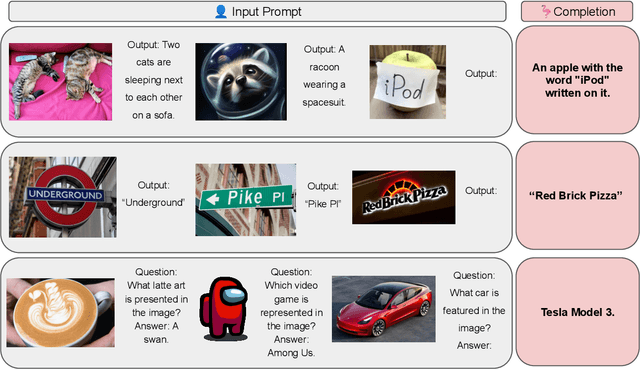

We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023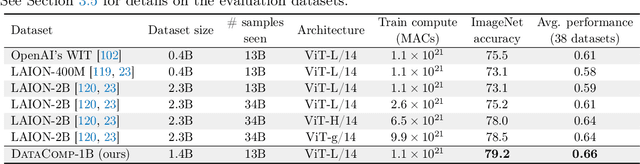
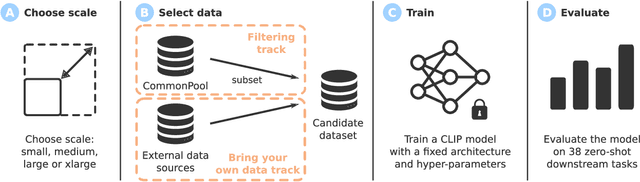


Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
Stable and low-precision training for large-scale vision-language models
Apr 25, 2023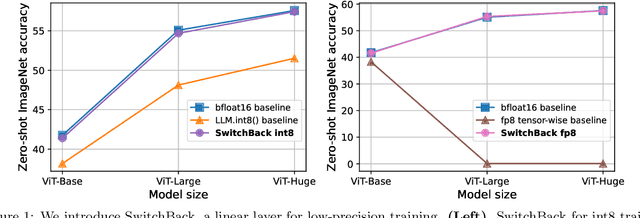
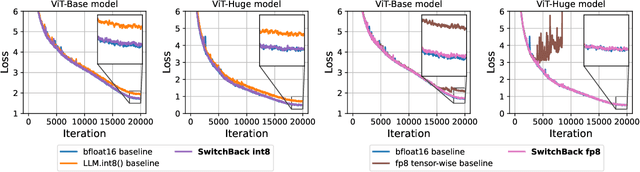
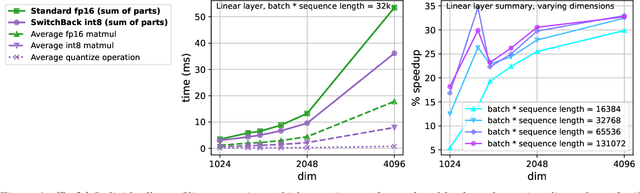
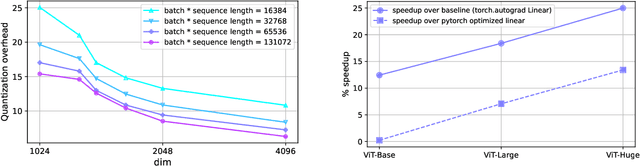
We introduce new methods for 1) accelerating and 2) stabilizing training for large language-vision models. 1) Towards accelerating training, we introduce SwitchBack, a linear layer for int8 quantized training which provides a speed-up of 13-25% while matching the performance of bfloat16 training within 0.1 percentage points for the 1B parameter CLIP ViT-Huge -- the largest int8 training to date. Our main focus is int8 as GPU support for float8 is rare, though we also analyze float8 training through simulation. While SwitchBack proves effective for float8, we show that standard techniques are also successful if the network is trained and initialized so that large feature magnitudes are discouraged, which we accomplish via layer-scale initialized with zeros. 2) Towards stable training, we analyze loss spikes and find they consistently occur 1-8 iterations after the squared gradients become under-estimated by their AdamW second moment estimator. As a result, we recommend an AdamW-Adafactor hybrid, which we refer to as StableAdamW because it avoids loss spikes when training a CLIP ViT-Huge model and outperforms gradient clipping.
The Role of Pre-training Data in Transfer Learning
Mar 01, 2023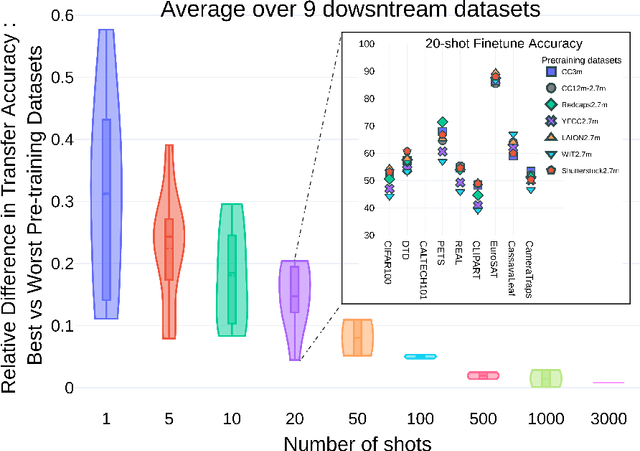

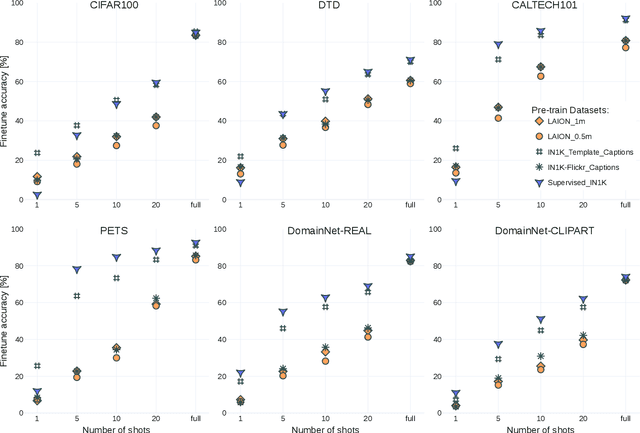

The transfer learning paradigm of model pre-training and subsequent fine-tuning produces high-accuracy models. While most studies recommend scaling the pre-training size to benefit most from transfer learning, a question remains: what data and method should be used for pre-training? We investigate the impact of pre-training data distribution on the few-shot and full fine-tuning performance using 3 pre-training methods (supervised, contrastive language-image and image-image), 7 pre-training datasets, and 9 downstream datasets. Through extensive controlled experiments, we find that the choice of the pre-training data source is essential for the few-shot transfer, but its role decreases as more data is made available for fine-tuning. Additionally, we explore the role of data curation and examine the trade-offs between label noise and the size of the pre-training dataset. We find that using 2000X more pre-training data from LAION can match the performance of supervised ImageNet pre-training. Furthermore, we investigate the effect of pre-training methods, comparing language-image contrastive vs. image-image contrastive, and find that the latter leads to better downstream accuracy
Reproducible scaling laws for contrastive language-image learning
Dec 14, 2022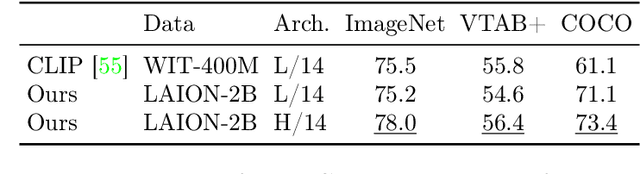
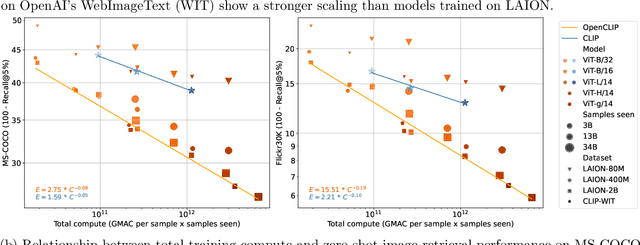


Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data \& models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
Editing Models with Task Arithmetic
Dec 08, 2022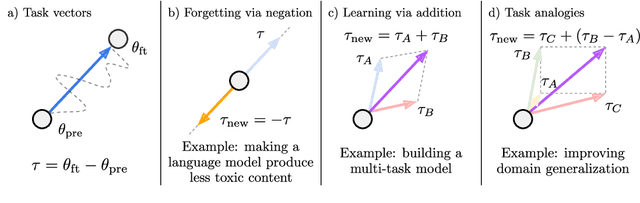
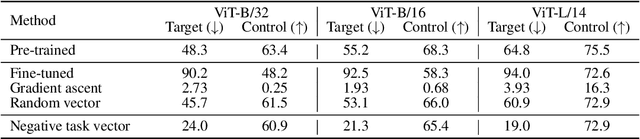
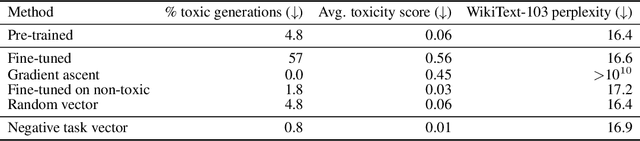
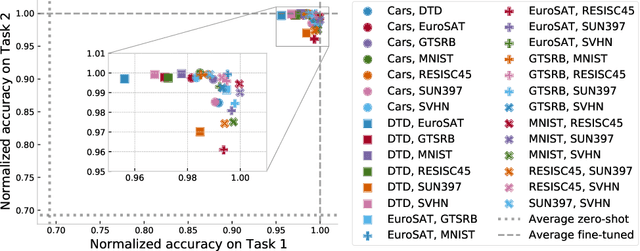
Changing how pre-trained models behave -- e.g., improving their performance on a downstream task or mitigating biases learned during pre-training -- is a common practice when developing machine learning systems. In this work, we propose a new paradigm for steering the behavior of neural networks, centered around \textit{task vectors}. A task vector specifies a direction in the weight space of a pre-trained model, such that movement in that direction improves performance on the task. We build task vectors by subtracting the weights of a pre-trained model from the weights of the same model after fine-tuning on a task. We show that these task vectors can be modified and combined together through arithmetic operations such as negation and addition, and the behavior of the resulting model is steered accordingly. Negating a task vector decreases performance on the target task, with little change in model behavior on control tasks. Moreover, adding task vectors together can improve performance on multiple tasks at once. Finally, when tasks are linked by an analogy relationship of the form ``A is to B as C is to D", combining task vectors from three of the tasks can improve performance on the fourth, even when no data from the fourth task is used for training. Overall, our experiments with several models, modalities and tasks show that task arithmetic is a simple, efficient and effective way of editing models.