 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarianna Nezhurina
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024
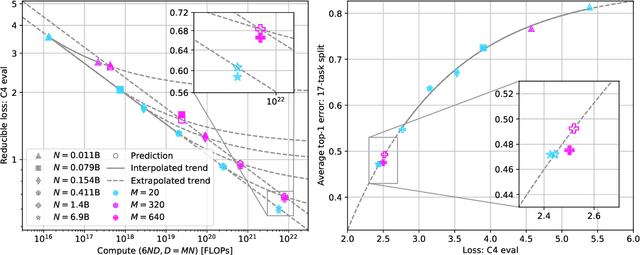
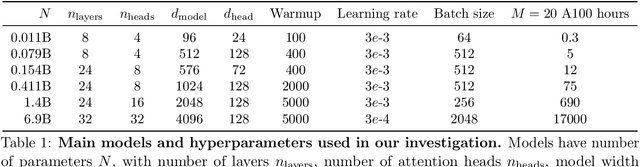
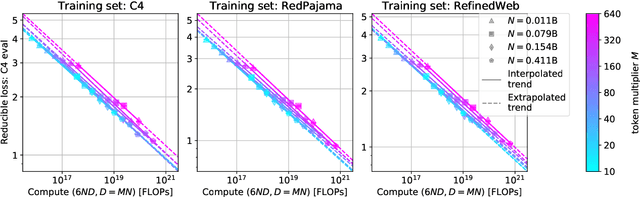

Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Aug 03, 2023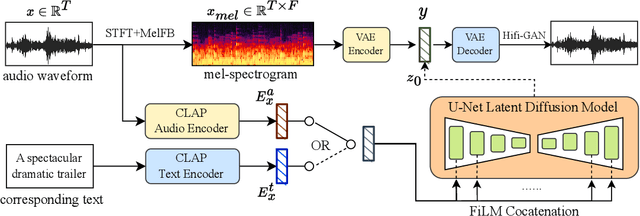
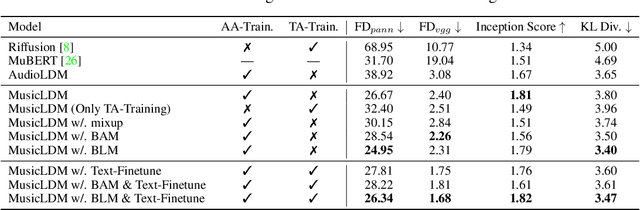
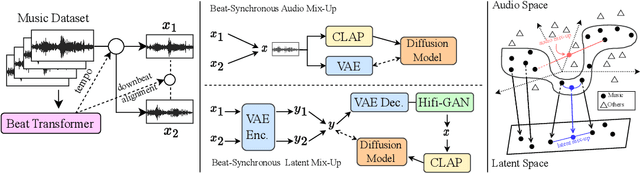
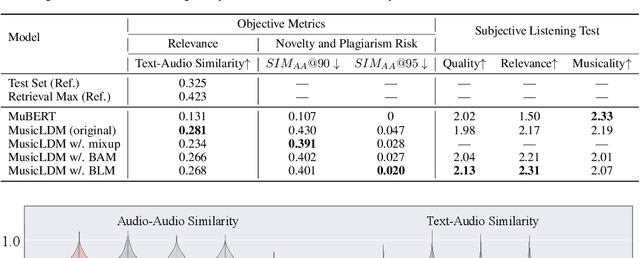
Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022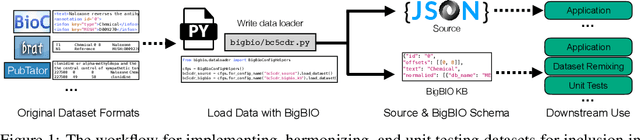
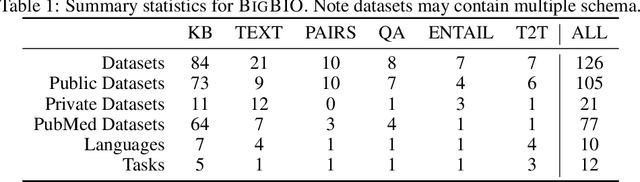

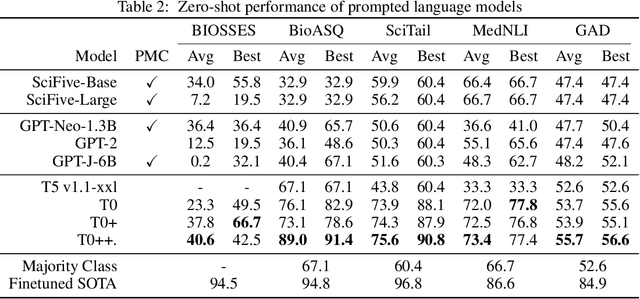
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical