 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Xu
A Cause-Effect Look at Alleviating Hallucination of Knowledge-grounded Dialogue Generation
Apr 04, 2024
Empowered by the large-scale pretrained language models, existing dialogue systems have demonstrated impressive performance conducting fluent and natural-sounding conversations. However, they are still plagued by the hallucination problem, causing unpredictable factual errors in the generated responses. Recently, knowledge-grounded dialogue generation models, that intentionally invoke external knowledge resources to more informative responses, are also proven to be effective in reducing hallucination. Following the idea of getting high-quality knowledge, a few efforts have achieved pretty good performance on this issue. As some inevitable knowledge noises may also lead to hallucinations, it is emergent to investigate the reason and future directions for building noise-tolerant methods in KGD tasks. In this paper, we analyze the causal story behind this problem with counterfactual reasoning methods. Based on the causal effect analysis, we propose a possible solution for alleviating the hallucination in KGD by exploiting the dialogue-knowledge interaction. Experimental results of our example implementation show that this method can reduce hallucination without disrupting other dialogue performance, while keeping adaptive to different generation models. We hope our efforts can support and call for more attention to developing lightweight techniques towards robust and trusty dialogue systems.
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Apr 03, 2024Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLM\footnote{\url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at \url{https://github.com/THUDM/ChatGLM-Math}.
3DMIT: 3D Multi-modal Instruction Tuning for Scene Understanding
Jan 16, 2024The remarkable potential of multi-modal large language models (MLLMs) in comprehending both vision and language information has been widely acknowledged. However, the scarcity of 3D scenes-language pairs in comparison to their 2D counterparts, coupled with the inadequacy of existing approaches in understanding of 3D scenes by LLMs, poses a significant challenge. In response, we collect and construct an extensive dataset comprising 75K instruction-response pairs tailored for 3D scenes. This dataset addresses tasks related to 3D VQA, 3D grounding, and 3D conversation. To further enhance the integration of 3D spatial information into LLMs, we introduce a novel and efficient prompt tuning paradigm, 3DMIT. This paradigm eliminates the alignment stage between 3D scenes and language and extends the instruction prompt with the 3D modality information including the entire scene and segmented objects. We evaluate the effectiveness of our method across diverse tasks in the 3D scene domain and find that our approach serves as a strategic means to enrich LLMs' comprehension of the 3D world. Our code is available at https://github.com/staymylove/3DMIT.
Forecasting Cryptocurrency Staking Rewards
Jan 16, 2024This research explores a relatively unexplored area of predicting cryptocurrency staking rewards, offering potential insights to researchers and investors. We investigate two predictive methodologies: a) a straightforward sliding-window average, and b) linear regression models predicated on historical data. The findings reveal that ETH staking rewards can be forecasted with an RMSE within 0.7% and 1.1% of the mean value for 1-day and 7-day look-aheads respectively, using a 7-day sliding-window average approach. Additionally, we discern diverse prediction accuracies across various cryptocurrencies, including SOL, XTZ, ATOM, and MATIC. Linear regression is identified as superior to the moving-window average for perdicting in the short term for XTZ and ATOM. The results underscore the generally stable and predictable nature of staking rewards for most assets, with MATIC presenting a noteworthy exception.
Coordinated Navigation Control of Cross-Domain Unmanned Systems via Guiding Vector Fields
Dec 18, 2023This paper proposes a distributed guiding-vector-field (DGVF) controller for cross-domain unmanned systems (CDUSs) consisting of heterogeneous unmanned aerial vehicles (UAVs) and unmanned surface vehicles (USVs), to achieve coordinated navigation whereas maneuvering along their prescribed paths. In particular, the DGVF controller provides a hierarchical architecture of an upper-level heterogeneous guidance velocity controller and a lower-level signal tracking regulator. Therein, the upper-level controller is to govern multiple heterogeneous USVs and UAVs to approach and maneuver along the prescribed paths and coordinate the formation simultaneously, whereas the low-level regulator is to track the corresponding desired guidance signals provided by the upper-level module. Significantly, the heterogeneous coordination among neighboring UAVs and USVs is achieved merely by the lightweight communication of a scalar (i.e., the additional virtual coordinate), which substantially decreases the communication and computational costs. Sufficient conditions assuring asymptotical convergence of the closed-loop system are derived in presence of the exponentially vanishing tracking errors. Finally, real-lake experiments are conducted on a self-established cross-domain heterogeneous platform consisting of three M-100 UAVs, two HUSTER-16 USVs, a HUSTER-12C USV, and a WiFi 5G wireless communication station to verify the effectiveness of the present DGVF controller.
* 14 pages
AlignBench: Benchmarking Chinese Alignment of Large Language Models
Dec 05, 2023Alignment has become a critical step for instruction-tuned Large Language Models (LLMs) to become helpful assistants. However, effective evaluation of alignment for emerging Chinese LLMs is still significantly lacking, calling for real-scenario grounded, open-ended, challenging and automatic evaluations tailored for alignment. To fill in this gap, we introduce AlignBench, a comprehensive multi-dimensional benchmark for evaluating LLMs' alignment in Chinese. Equipped with a human-in-the-loop data curation pipeline, our benchmark employs a rule-calibrated multi-dimensional LLM-as-Judge with Chain-of-Thought to generate explanations and final ratings as evaluations, ensuring high reliability and interpretability. Furthermore, we report AlignBench evaluated by CritiqueLLM, a dedicated Chinese evaluator LLM that recovers 95% of GPT-4's evaluation ability. We will provide public APIs for evaluating AlignBench with CritiqueLLM to facilitate the evaluation of LLMs' Chinese alignment. All evaluation codes, data, and LLM generations are available at \url{https://github.com/THUDM/AlignBench}.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 12, 2023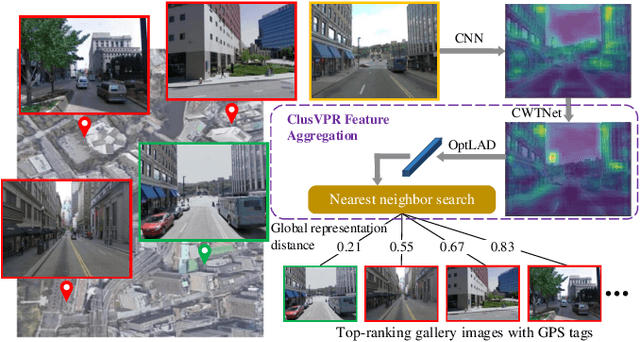
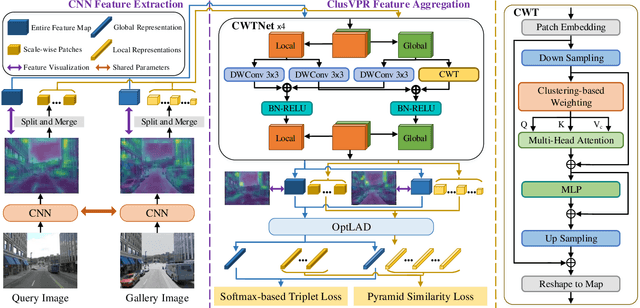
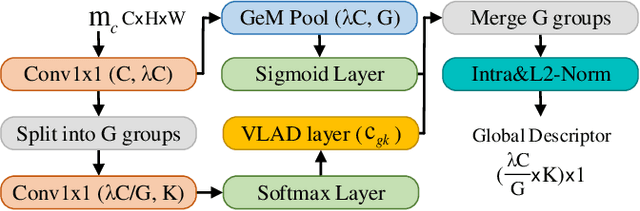
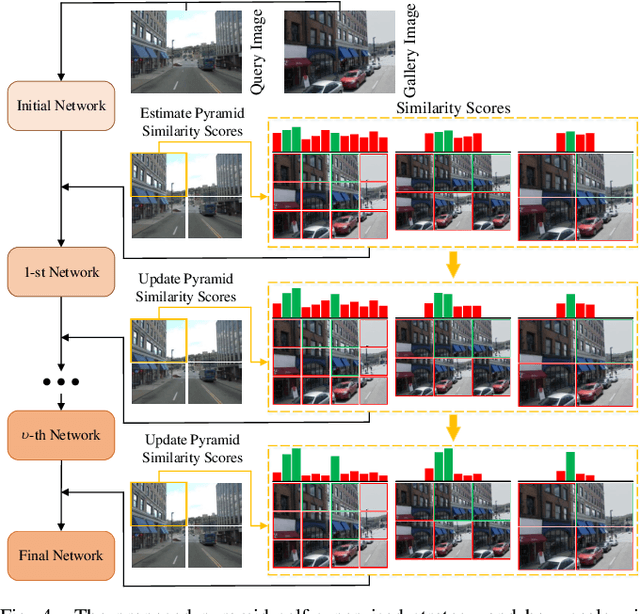
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.
Exploring Multi-Modal Contextual Knowledge for Open-Vocabulary Object Detection
Aug 30, 2023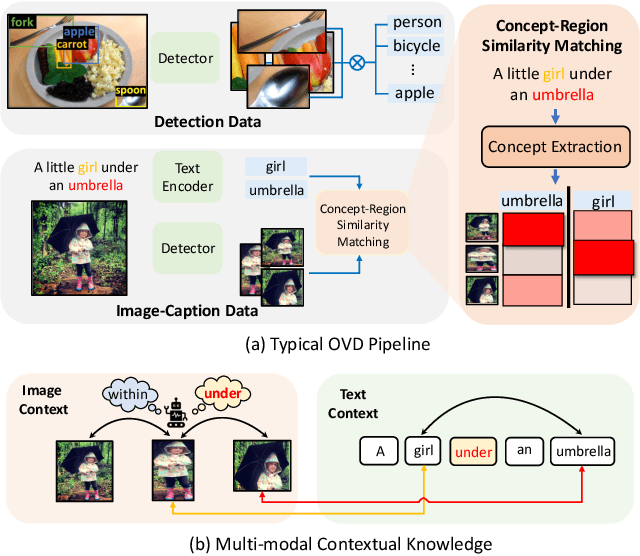
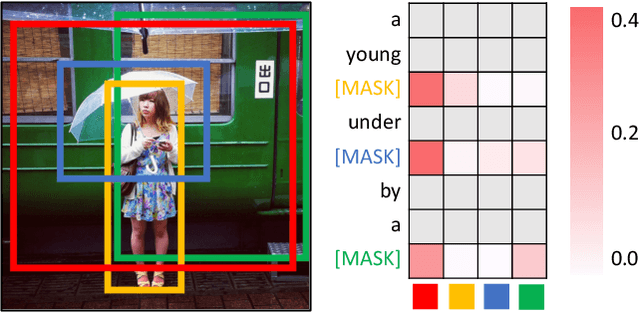
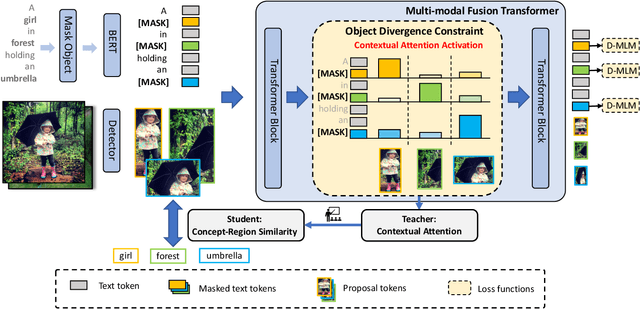
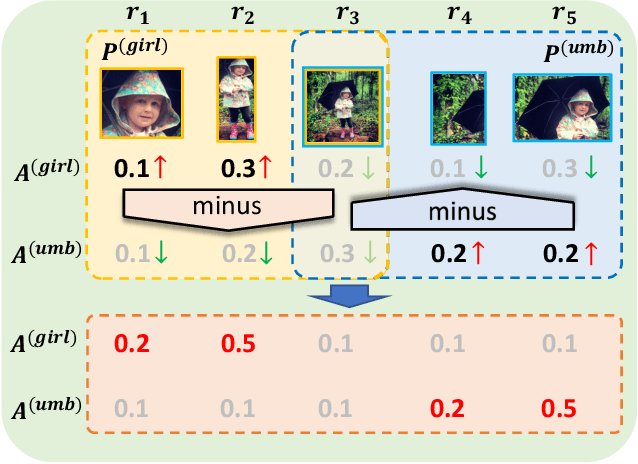
In this paper, we for the first time explore helpful multi-modal contextual knowledge to understand novel categories for open-vocabulary object detection (OVD). The multi-modal contextual knowledge stands for the joint relationship across regions and words. However, it is challenging to incorporate such multi-modal contextual knowledge into OVD. The reason is that previous detection frameworks fail to jointly model multi-modal contextual knowledge, as object detectors only support vision inputs and no caption description is provided at test time. To this end, we propose a multi-modal contextual knowledge distillation framework, MMC-Det, to transfer the learned contextual knowledge from a teacher fusion transformer with diverse multi-modal masked language modeling (D-MLM) to a student detector. The diverse multi-modal masked language modeling is realized by an object divergence constraint upon traditional multi-modal masked language modeling (MLM), in order to extract fine-grained region-level visual contexts, which are vital to object detection. Extensive experiments performed upon various detection datasets show the effectiveness of our multi-modal context learning strategy, where our approach well outperforms the recent state-of-the-art methods.
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions
Aug 19, 2023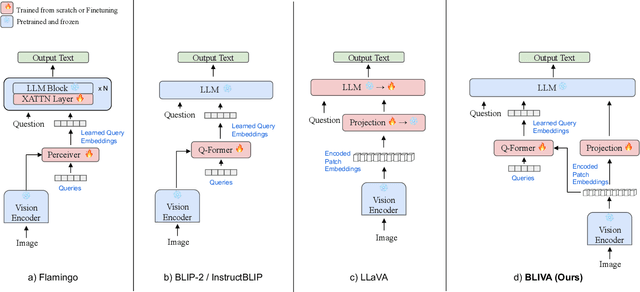
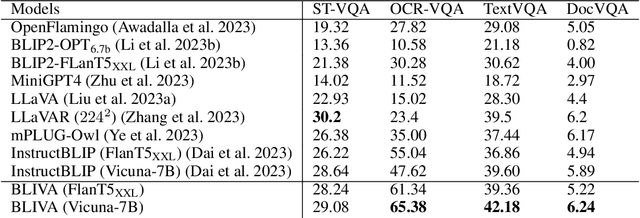

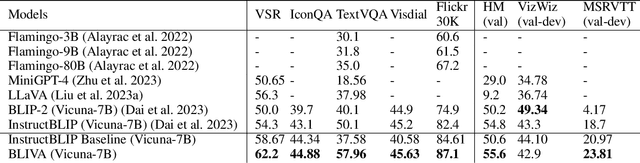
Vision Language Models (VLMs), which extend Large Language Models (LLM) by incorporating visual understanding capability, have demonstrated significant advancements in addressing open-ended visual question-answering (VQA) tasks. However, these models cannot accurately interpret images infused with text, a common occurrence in real-world scenarios. Standard procedures for extracting information from images often involve learning a fixed set of query embeddings. These embeddings are designed to encapsulate image contexts and are later used as soft prompt inputs in LLMs. Yet, this process is limited to the token count, potentially curtailing the recognition of scenes with text-rich context. To improve upon them, the present study introduces BLIVA: an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach assists the model to capture intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76\% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9\% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence. To demonstrate the broad industry applications enabled by BLIVA, we evaluate the model using a new dataset comprising YouTube thumbnails paired with question-answer sets across 13 diverse categories. For researchers interested in further exploration, our code and models are freely accessible at https://github.com/mlpc-ucsd/BLIVA.git
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023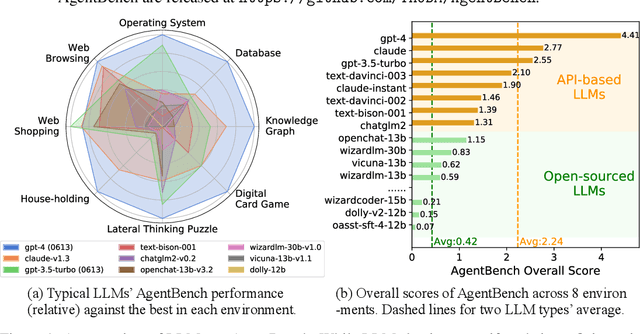
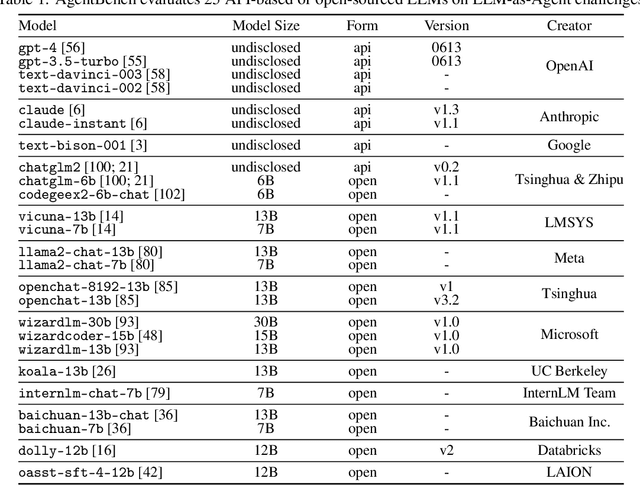
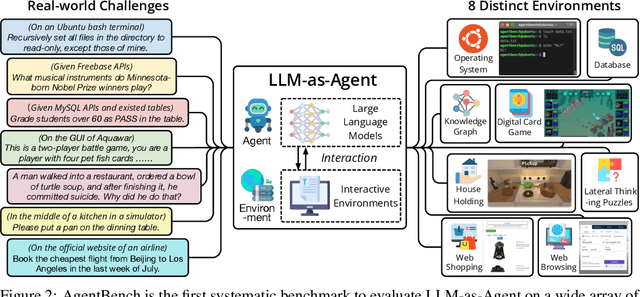
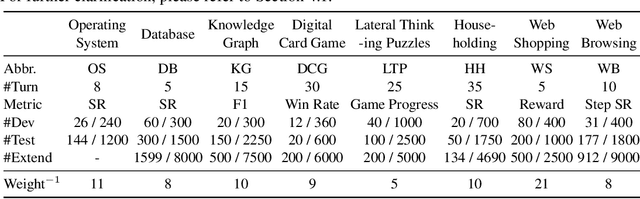
Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench