 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeyuan Chen
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Mar 17, 2024
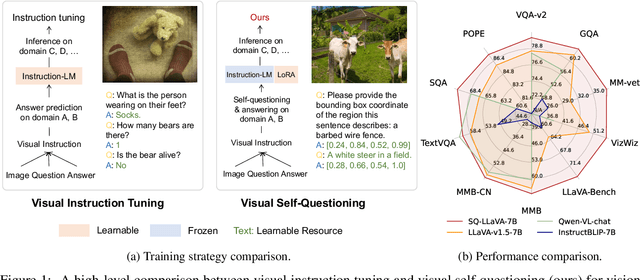
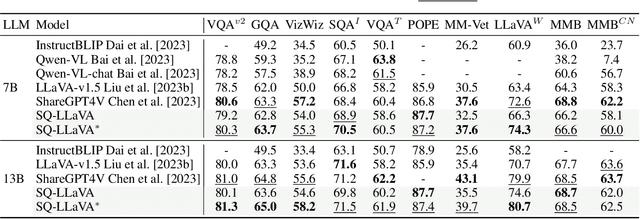
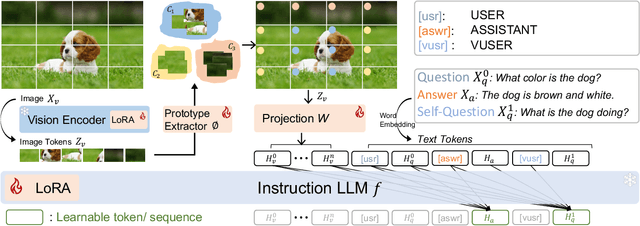
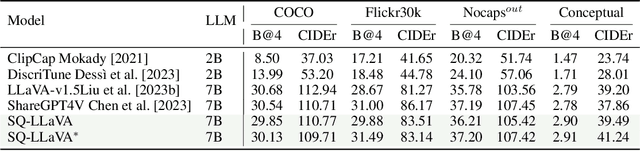
Recent advancements in the vision-language model have shown notable generalization in vision-language tasks after visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which are costly to obtain. However, the image contains rich contextual information that has been largely under-explored. This paper first attempts to harness this overlooked context within visual instruction data, training the model to self-supervised `learning' how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a consistent performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.
Bayesian Diffusion Models for 3D Shape Reconstruction
Mar 11, 2024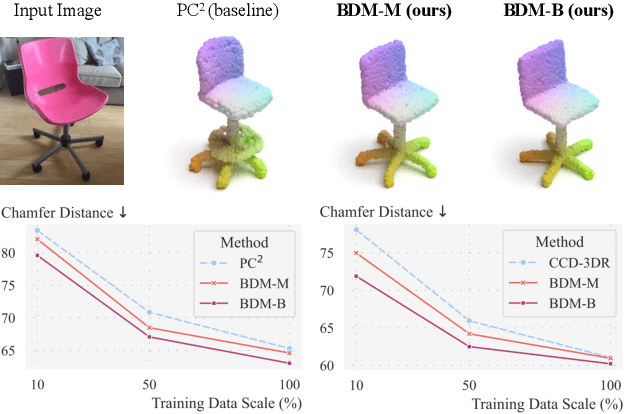
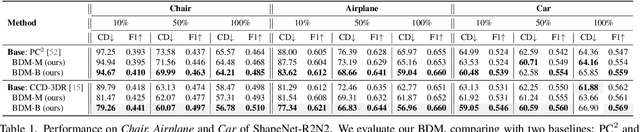
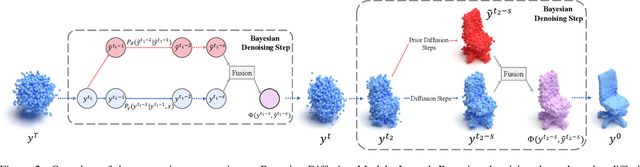
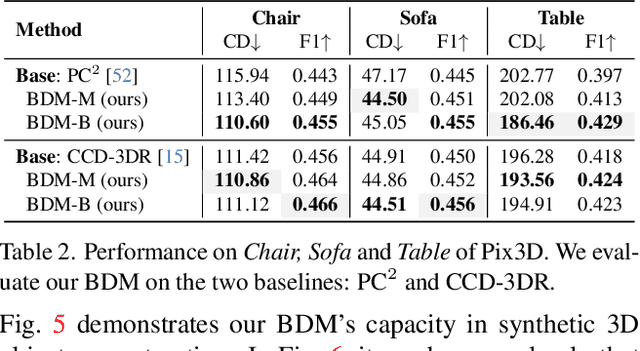
We present Bayesian Diffusion Models (BDM), a prediction algorithm that performs effective Bayesian inference by tightly coupling the top-down (prior) information with the bottom-up (data-driven) procedure via joint diffusion processes. We show the effectiveness of BDM on the 3D shape reconstruction task. Compared to prototypical deep learning data-driven approaches trained on paired (supervised) data-labels (e.g. image-point clouds) datasets, our BDM brings in rich prior information from standalone labels (e.g. point clouds) to improve the bottom-up 3D reconstruction. As opposed to the standard Bayesian frameworks where explicit prior and likelihood are required for the inference, BDM performs seamless information fusion via coupled diffusion processes with learned gradient computation networks. The specialty of our BDM lies in its capability to engage the active and effective information exchange and fusion of the top-down and bottom-up processes where each itself is a diffusion process. We demonstrate state-of-the-art results on both synthetic and real-world benchmarks for 3D shape reconstruction.
Pattern-wise Transparent Sequential Recommendation
Feb 29, 2024A transparent decision-making process is essential for developing reliable and trustworthy recommender systems. For sequential recommendation, it means that the model can identify critical items asthe justifications for its recommendation results. However, achieving both model transparency and recommendation performance simultaneously is challenging, especially for models that take the entire sequence of items as input without screening. In this paper,we propose an interpretable framework (named PTSR) that enables a pattern-wise transparent decision-making process. It breaks the sequence of items into multi-level patterns that serve as atomic units for the entire recommendation process. The contribution of each pattern to the outcome is quantified in the probability space. With a carefully designed pattern weighting correction, the pattern contribution can be learned in the absence of ground-truth critical patterns. The final recommended items are those items that most critical patterns strongly endorse. Extensive experiments on four public datasets demonstrate remarkable recommendation performance, while case studies validate the model transparency. Our code is available at https://anonymous.4open.science/r/PTSR-2237.
Dolfin: Diffusion Layout Transformers without Autoencoder
Oct 25, 2023In this paper, we introduce a novel generative model, Diffusion Layout Transformers without Autoencoder (Dolfin), which significantly improves the modeling capability with reduced complexity compared to existing methods. Dolfin employs a Transformer-based diffusion process to model layout generation. In addition to an efficient bi-directional (non-causal joint) sequence representation, we further propose an autoregressive diffusion model (Dolfin-AR) that is especially adept at capturing rich semantic correlations for the neighboring objects, such as alignment, size, and overlap. When evaluated against standard generative layout benchmarks, Dolfin notably improves performance across various metrics (fid, alignment, overlap, MaxIoU and DocSim scores), enhancing transparency and interoperability in the process. Moreover, Dolfin's applications extend beyond layout generation, making it suitable for modeling geometric structures, such as line segments. Our experiments present both qualitative and quantitative results to demonstrate the advantages of Dolfin.
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions
Aug 19, 2023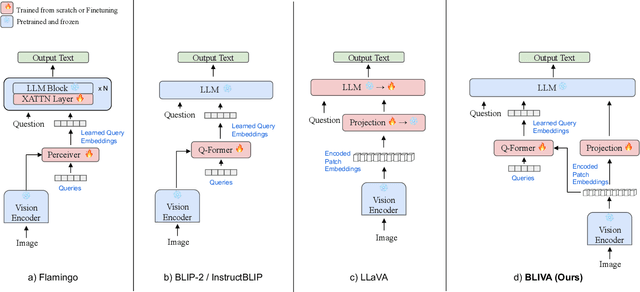
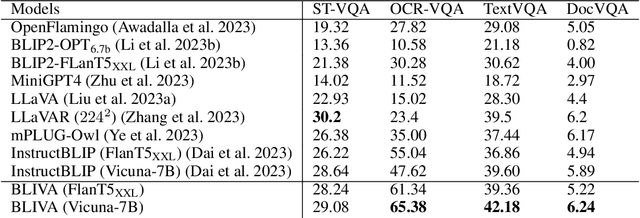

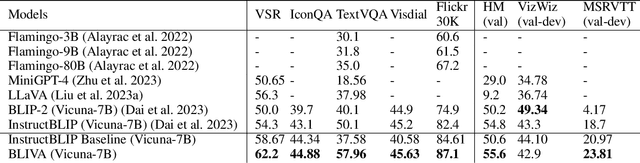
Vision Language Models (VLMs), which extend Large Language Models (LLM) by incorporating visual understanding capability, have demonstrated significant advancements in addressing open-ended visual question-answering (VQA) tasks. However, these models cannot accurately interpret images infused with text, a common occurrence in real-world scenarios. Standard procedures for extracting information from images often involve learning a fixed set of query embeddings. These embeddings are designed to encapsulate image contexts and are later used as soft prompt inputs in LLMs. Yet, this process is limited to the token count, potentially curtailing the recognition of scenes with text-rich context. To improve upon them, the present study introduces BLIVA: an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach assists the model to capture intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76\% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9\% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence. To demonstrate the broad industry applications enabled by BLIVA, we evaluate the model using a new dataset comprising YouTube thumbnails paired with question-answer sets across 13 diverse categories. For researchers interested in further exploration, our code and models are freely accessible at https://github.com/mlpc-ucsd/BLIVA.git
Beyond Semantics: Learning a Behavior Augmented Relevance Model with Self-supervised Learning
Aug 16, 2023
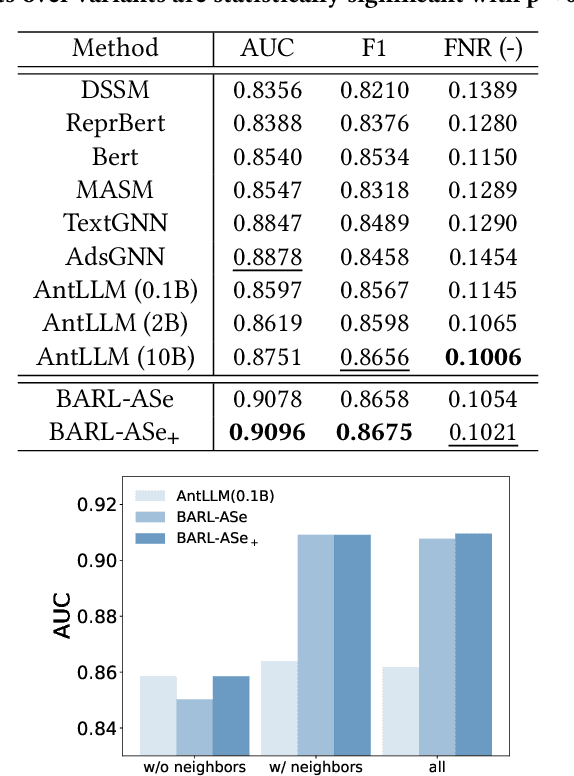
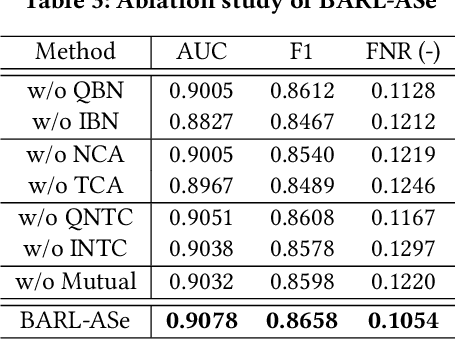
Relevance modeling aims to locate desirable items for corresponding queries, which is crucial for search engines to ensure user experience. Although most conventional approaches address this problem by assessing the semantic similarity between the query and item, pure semantic matching is not everything.
BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
Aug 11, 2023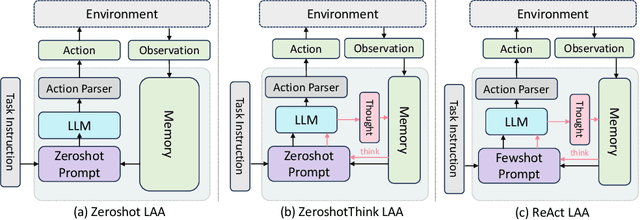
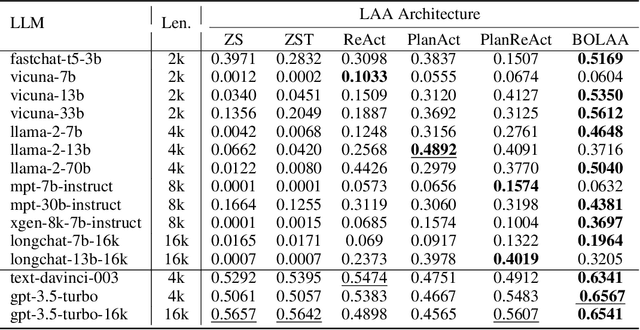
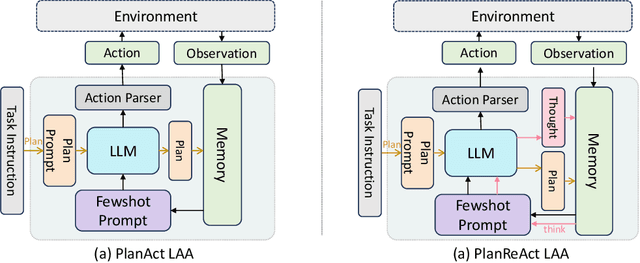
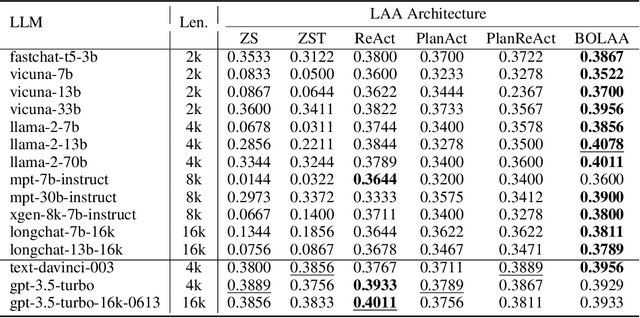
The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, \textit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Aug 07, 2023
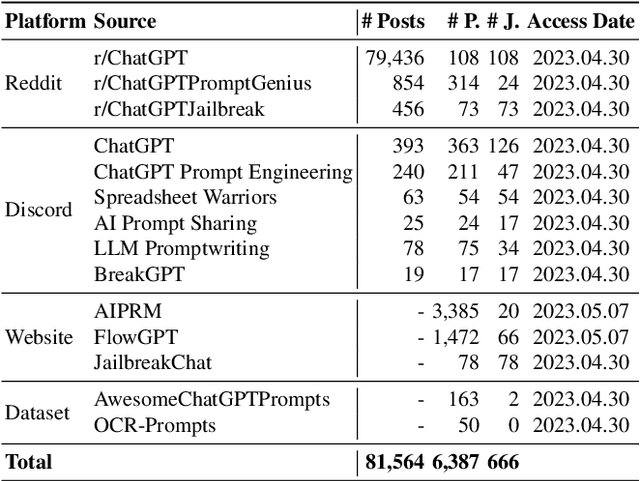
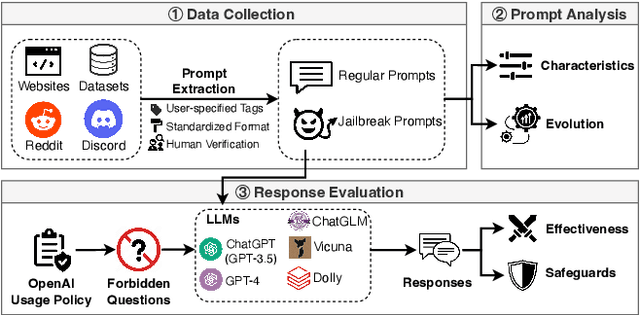

The misuse of large language models (LLMs) has garnered significant attention from the general public and LLM vendors. In response, efforts have been made to align LLMs with human values and intent use. However, a particular type of adversarial prompts, known as jailbreak prompt, has emerged and continuously evolved to bypass the safeguards and elicit harmful content from LLMs. In this paper, we conduct the first measurement study on jailbreak prompts in the wild, with 6,387 prompts collected from four platforms over six months. Leveraging natural language processing technologies and graph-based community detection methods, we discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from public platforms to private ones, posing new challenges for LLM vendors in proactive detection. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 46,800 samples across 13 forbidden scenarios. Our experiments show that current LLMs and safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify two highly effective jailbreak prompts which achieve 0.99 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and they have persisted online for over 100 days. Our work sheds light on the severe and evolving threat landscape of jailbreak prompts. We hope our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
Aug 04, 2023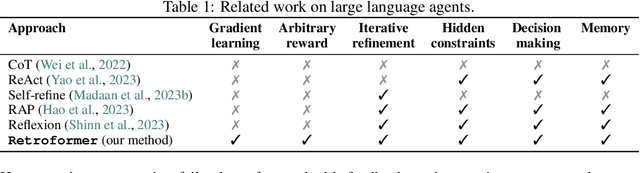
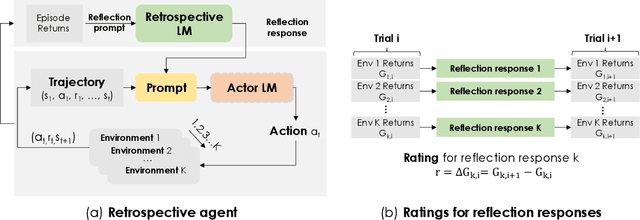
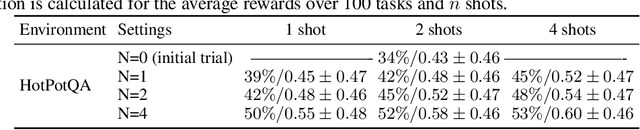
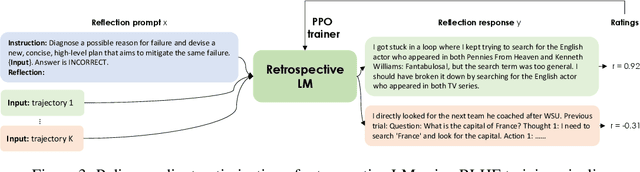
Recent months have seen the emergence of a powerful new trend in which large language models (LLMs) are augmented to become autonomous language agents capable of performing objective oriented multi-step tasks on their own, rather than merely responding to queries from human users. Most existing language agents, however, are not optimized using environment-specific rewards. Although some agents enable iterative refinement through verbal feedback, they do not reason and plan in ways that are compatible with gradient-based learning from rewards. This paper introduces a principled framework for reinforcing large language agents by learning a retrospective model, which automatically tunes the language agent prompts from environment feedback through policy gradient. Specifically, our proposed agent architecture learns from rewards across multiple environments and tasks, for fine-tuning a pre-trained language model which refines the language agent prompt by summarizing the root cause of prior failed attempts and proposing action plans. Experimental results on various tasks demonstrate that the language agents improve over time and that our approach considerably outperforms baselines that do not properly leverage gradients from the environment. This demonstrates that using policy gradient optimization to improve language agents, for which we believe our work is one of the first, seems promising and can be applied to optimize other models in the agent architecture to enhance agent performances over time.
REX: Rapid Exploration and eXploitation for AI Agents
Jul 18, 2023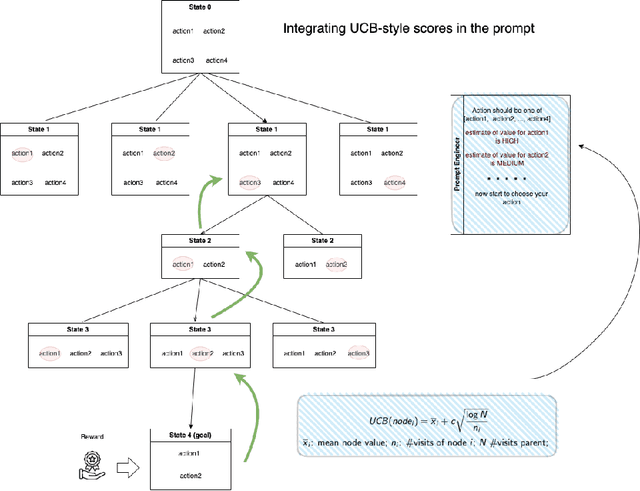
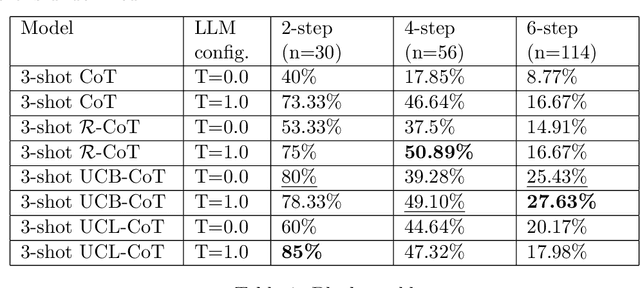
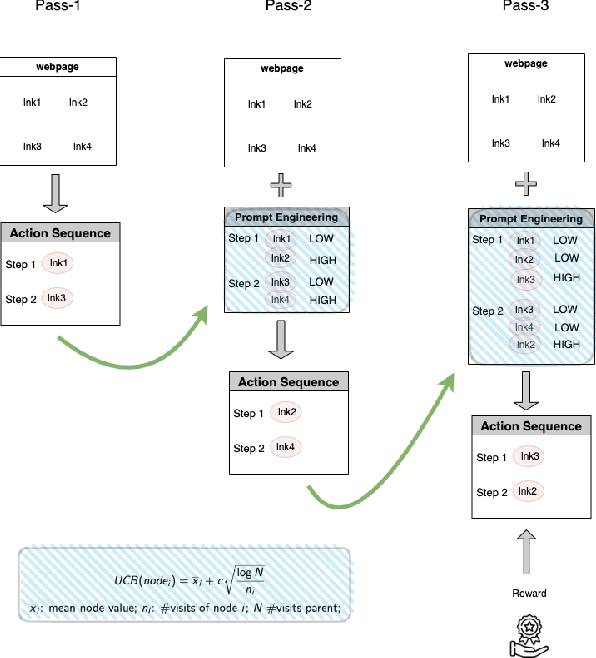

In this paper, we propose an enhanced approach for Rapid Exploration and eXploitation for AI Agents called REX. Existing AutoGPT-style techniques have inherent limitations, such as a heavy reliance on precise descriptions for decision-making, and the lack of a systematic approach to leverage try-and-fail procedures akin to traditional Reinforcement Learning (RL). REX introduces an additional layer of rewards and integrates concepts similar to Upper Confidence Bound (UCB) scores, leading to more robust and efficient AI agent performance. This approach has the advantage of enabling the utilization of offline behaviors from logs and allowing seamless integration with existing foundation models while it does not require any model fine-tuning. Through comparative analysis with existing methods such as Chain-of-Thoughts(CoT) and Reasoning viA Planning(RAP), REX-based methods demonstrate comparable performance and, in certain cases, even surpass the results achieved by these existing techniques. Notably, REX-based methods exhibit remarkable reductions in execution time, enhancing their practical applicability across a diverse set of scenarios.