 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Lei
FinLangNet: A Novel Deep Learning Framework for Credit Risk Prediction Using Linguistic Analogy in Financial Data
Apr 19, 2024
Recent industrial applications in risk prediction still heavily rely on extensively manually-tuned, statistical learning methods. Real-world financial data, characterized by its high-dimensionality, sparsity, high noise levels, and significant imbalance, poses unique challenges for the effective application of deep neural network models. In this work, we introduce a novel deep learning risk prediction framework, FinLangNet, which conceptualizes credit loan trajectories in a structure that mirrors linguistic constructs. This framework is tailored for credit risk prediction using real-world financial data, drawing on structural similarities to language by adapting natural language processing techniques. It focuses on analyzing the evolution and predictability of credit histories through detailed financial event sequences. Our research demonstrates that FinLangNet surpasses traditional statistical methods in predicting credit risk and that its integration with these methods enhances credit card fraud prediction models, achieving a significant improvement of over 1.5 points in the Kolmogorov-Smirnov metric.
Relationship Discovery for Drug Recommendation
Apr 18, 2024Medication recommendation systems are designed to deliver personalized drug suggestions that are closely aligned with individual patient needs. Previous studies have primarily concentrated on developing medication embeddings, achieving significant progress. Nonetheless, these approaches often fall short in accurately reflecting individual patient profiles, mainly due to challenges in distinguishing between various patient conditions and the inability to establish precise correlations between specific conditions and appropriate medications. In response to these issues, we introduce DisMed, a model that focuses on patient conditions to enhance personalization. DisMed employs causal inference to discern clear, quantifiable causal links. It then examines patient conditions in depth, recognizing and adapting to the evolving nuances of these conditions, and mapping them directly to corresponding medications. Additionally, DisMed leverages data from multiple patient visits to propose combinations of medications. Comprehensive testing on real-world datasets demonstrates that DisMed not only improves the customization of patient profiles but also surpasses leading models in both precision and safety.
Knowledge-Aware Multi-Intent Contrastive Learning for Multi-Behavior Recommendation
Apr 18, 2024Multi-behavioral recommendation optimizes user experiences by providing users with more accurate choices based on their diverse behaviors, such as view, add to cart, and purchase. Current studies on multi-behavioral recommendation mainly explore the connections and differences between multi-behaviors from an implicit perspective. Specifically, they directly model those relations using black-box neural networks. In fact, users' interactions with items under different behaviors are driven by distinct intents. For instance, when users view products, they tend to pay greater attention to information such as ratings and brands. However, when it comes to the purchasing phase, users become more price-conscious. To tackle this challenge and data sparsity problem in the multi-behavioral recommendation, we propose a novel model: Knowledge-Aware Multi-Intent Contrastive Learning (KAMCL) model. This model uses relationships in the knowledge graph to construct intents, aiming to mine the connections between users' multi-behaviors from the perspective of intents to achieve more accurate recommendations. KAMCL is equipped with two contrastive learning schemes to alleviate the data scarcity problem and further enhance user representations. Extensive experiments on three real datasets demonstrate the superiority of our model.
High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning
Apr 07, 2024Zero-shot learning(ZSL) aims to recognize new classes without prior exposure to their samples, relying on semantic knowledge from observed classes. However, current attention-based models may overlook the transferability of visual features and the distinctiveness of attribute localization when learning regional features in images. Additionally, they often overlook shared attributes among different objects. Highly discriminative attribute features are crucial for identifying and distinguishing unseen classes. To address these issues, we propose an innovative approach called High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning (HDAFL). HDAFL optimizes visual features by learning attribute features to obtain discriminative visual embeddings. Specifically, HDAFL utilizes multiple convolutional kernels to automatically learn discriminative regions highly correlated with attributes in images, eliminating irrelevant interference in image features. Furthermore, we introduce a Transformer-based attribute discrimination encoder to enhance the discriminative capability among attributes. Simultaneously, the method employs contrastive loss to alleviate dataset biases and enhance the transferability of visual features, facilitating better semantic transfer between seen and unseen classes. Experimental results demonstrate the effectiveness of HDAFL across three widely used datasets.
HDR Imaging for Dynamic Scenes with Events
Apr 04, 2024High dynamic range imaging (HDRI) for real-world dynamic scenes is challenging because moving objects may lead to hybrid degradation of low dynamic range and motion blur. Existing event-based approaches only focus on a separate task, while cascading HDRI and motion deblurring would lead to sub-optimal solutions, and unavailable ground-truth sharp HDR images aggravate the predicament. To address these challenges, we propose an Event-based HDRI framework within a Self-supervised learning paradigm, i.e., Self-EHDRI, which generalizes HDRI performance in real-world dynamic scenarios. Specifically, a self-supervised learning strategy is carried out by learning cross-domain conversions from blurry LDR images to sharp LDR images, which enables sharp HDR images to be accessible in the intermediate process even though ground-truth sharp HDR images are missing. Then, we formulate the event-based HDRI and motion deblurring model and conduct a unified network to recover the intermediate sharp HDR results, where both the high dynamic range and high temporal resolution of events are leveraged simultaneously for compensation. We construct large-scale synthetic and real-world datasets to evaluate the effectiveness of our method. Comprehensive experiments demonstrate that the proposed Self-EHDRI outperforms state-of-the-art approaches by a large margin. The codes, datasets, and results are available at https://lxp-whu.github.io/Self-EHDRI.
Bayesian Exploration of Pre-trained Models for Low-shot Image Classification
Mar 30, 2024Low-shot image classification is a fundamental task in computer vision, and the emergence of large-scale vision-language models such as CLIP has greatly advanced the forefront of research in this field. However, most existing CLIP-based methods lack the flexibility to effectively incorporate other pre-trained models that encompass knowledge distinct from CLIP. To bridge the gap, this work proposes a simple and effective probabilistic model ensemble framework based on Gaussian processes, which have previously demonstrated remarkable efficacy in processing small data. We achieve the integration of prior knowledge by specifying the mean function with CLIP and the kernel function with an ensemble of deep kernels built upon various pre-trained models. By regressing the classification label directly, our framework enables analytical inference, straightforward uncertainty quantification, and principled hyper-parameter tuning. Through extensive experiments on standard benchmarks, we demonstrate that our method consistently outperforms competitive ensemble baselines regarding predictive performance. Additionally, we assess the robustness of our method and the quality of the yielded uncertainty estimates on out-of-distribution datasets. We also illustrate that our method, despite relying on label regression, still enjoys superior model calibration compared to most deterministic baselines.
Bayesian Diffusion Models for 3D Shape Reconstruction
Mar 11, 2024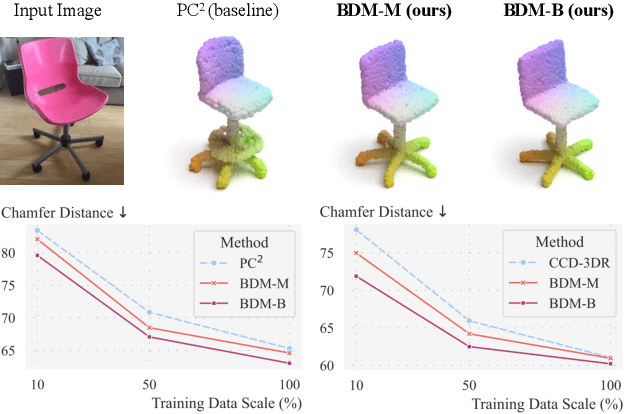
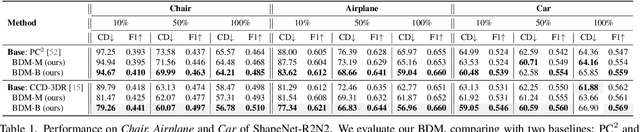
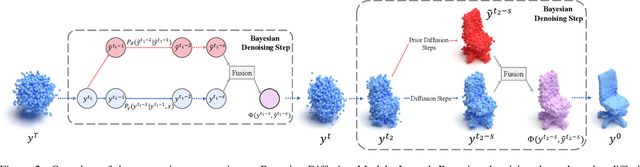
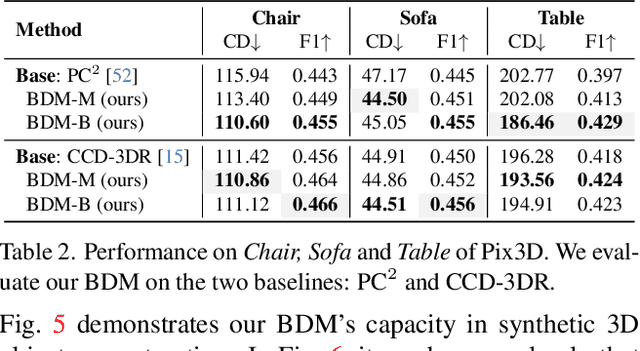
We present Bayesian Diffusion Models (BDM), a prediction algorithm that performs effective Bayesian inference by tightly coupling the top-down (prior) information with the bottom-up (data-driven) procedure via joint diffusion processes. We show the effectiveness of BDM on the 3D shape reconstruction task. Compared to prototypical deep learning data-driven approaches trained on paired (supervised) data-labels (e.g. image-point clouds) datasets, our BDM brings in rich prior information from standalone labels (e.g. point clouds) to improve the bottom-up 3D reconstruction. As opposed to the standard Bayesian frameworks where explicit prior and likelihood are required for the inference, BDM performs seamless information fusion via coupled diffusion processes with learned gradient computation networks. The specialty of our BDM lies in its capability to engage the active and effective information exchange and fusion of the top-down and bottom-up processes where each itself is a diffusion process. We demonstrate state-of-the-art results on both synthetic and real-world benchmarks for 3D shape reconstruction.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024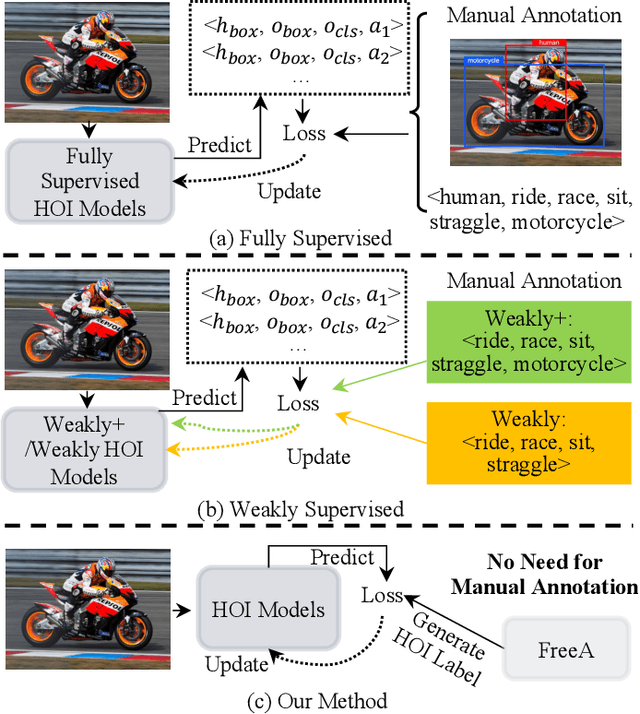
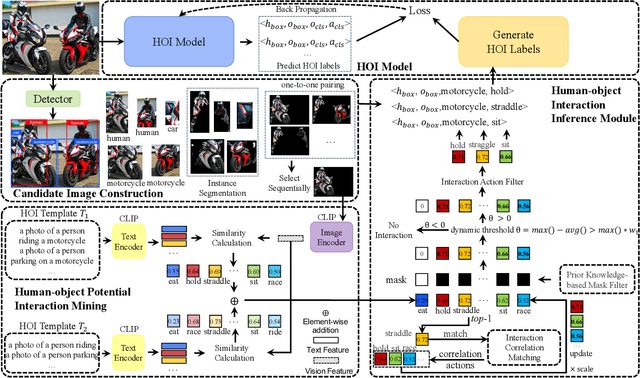
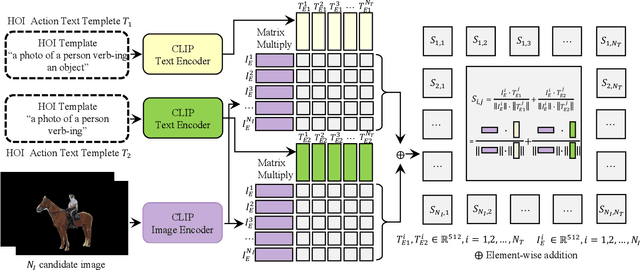
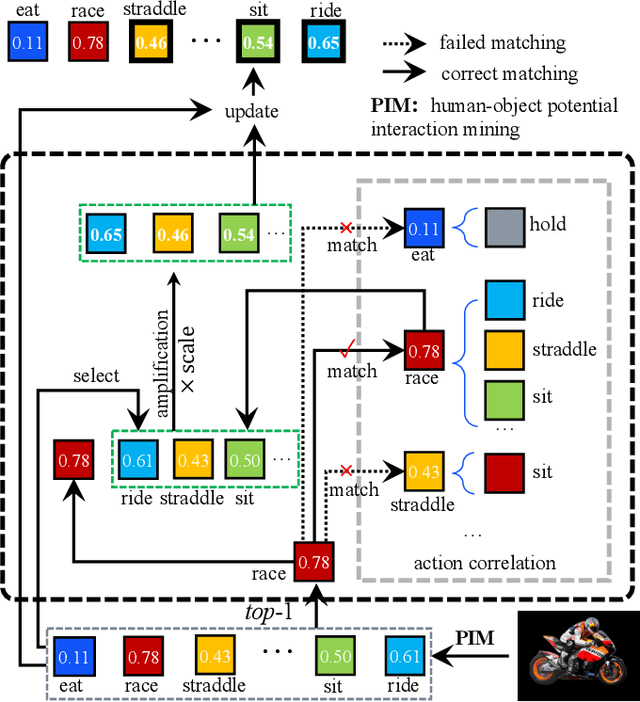
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.
Dual-Granularity Medication Recommendation Based on Causal Inference
Mar 01, 2024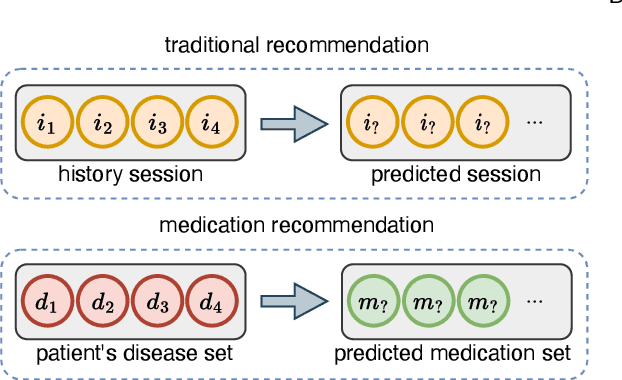
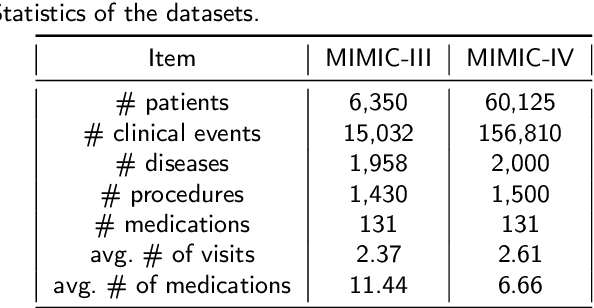
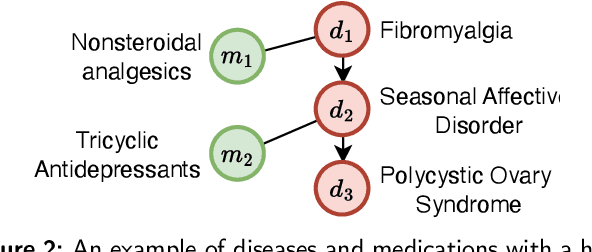
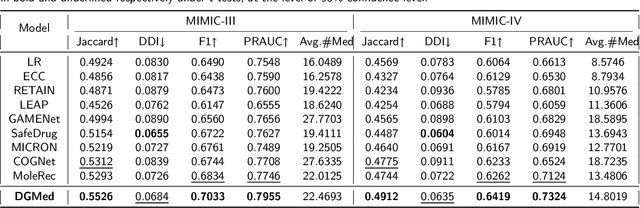
As medical demands grow and machine learning technology advances, AI-based diagnostic and treatment systems are garnering increasing attention. Medication recommendation aims to integrate patients' long-term health records with medical knowledge, recommending accuracy and safe medication combinations for specific conditions. However, most existing researches treat medication recommendation systems merely as variants of traditional recommendation systems, overlooking the heterogeneity between medications and diseases. To address this challenge, we propose DGMed, a framework for medication recommendation. DGMed utilizes causal inference to uncover the connections among medical entities and presents an innovative feature alignment method to tackle heterogeneity issues. Specifically, this study first applies causal inference to analyze the quantified therapeutic effects of medications on specific diseases from historical records, uncovering potential links between medical entities. Subsequently, we integrate molecular-level knowledge, aligning the embeddings of medications and diseases within the molecular space to effectively tackle their heterogeneity. Ultimately, based on relationships at the entity level, we adaptively adjust the recommendation probabilities of medication and recommend medication combinations according to the patient's current health condition. Experimental results on a real-world dataset show that our method surpasses existing state-of-the-art baselines in four evaluation metrics, demonstrating superior performance in both accuracy and safety aspects. Compared to the sub-optimal model, our approach improved accuracy by 4.40%, reduced the risk of side effects by 6.14%, and increased time efficiency by 47.15%.
COPR: Continual Human Preference Learning via Optimal Policy Regularization
Feb 27, 2024Reinforcement Learning from Human Feedback (RLHF) is commonly utilized to improve the alignment of Large Language Models (LLMs) with human preferences. Given the evolving nature of human preferences, continual alignment becomes more crucial and practical in comparison to traditional static alignment. Nevertheless, making RLHF compatible with Continual Learning (CL) is challenging due to its complex process. Meanwhile, directly learning new human preferences may lead to Catastrophic Forgetting (CF) of historical preferences, resulting in helpless or harmful outputs. To overcome these challenges, we propose the Continual Optimal Policy Regularization (COPR) method, which draws inspiration from the optimal policy theory. COPR utilizes a sampling distribution as a demonstration and regularization constraints for CL. It adopts the Lagrangian Duality (LD) method to dynamically regularize the current policy based on the historically optimal policy, which prevents CF and avoids over-emphasizing unbalanced objectives. We also provide formal proof for the learnability of COPR. The experimental results show that COPR outperforms strong CL baselines on our proposed benchmark, in terms of reward-based, GPT-4 evaluations and human assessment. Furthermore, we validate the robustness of COPR under various CL settings, including different backbones, replay memory sizes, and learning orders.