 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYulan He
Can We Catch the Elephant? The Evolvement of Hallucination Evaluation on Natural Language Generation: A Survey
Apr 18, 2024
Hallucination in Natural Language Generation (NLG) is like the elephant in the room, obvious but often overlooked until recent achievements significantly improved the fluency and grammatical accuracy of generated text. For Large Language Models (LLMs), hallucinations can happen in various downstream tasks and casual conversations, which need accurate assessment to enhance reliability and safety. However, current studies on hallucination evaluation vary greatly, and people still find it difficult to sort out and select the most appropriate evaluation methods. Moreover, as NLP research gradually shifts to the domain of LLMs, it brings new challenges to this direction. This paper provides a comprehensive survey on the evolvement of hallucination evaluation methods, aiming to address three key aspects: 1) Diverse definitions and granularity of facts; 2) The categories of automatic evaluators and their applicability; 3) Unresolved issues and future directions.
Set-Aligning Framework for Auto-Regressive Event Temporal Graph Generation
Apr 01, 2024Event temporal graphs have been shown as convenient and effective representations of complex temporal relations between events in text. Recent studies, which employ pre-trained language models to auto-regressively generate linearised graphs for constructing event temporal graphs, have shown promising results. However, these methods have often led to suboptimal graph generation as the linearised graphs exhibit set characteristics which are instead treated sequentially by language models. This discrepancy stems from the conventional text generation objectives, leading to erroneous penalisation of correct predictions caused by the misalignment of elements in target sequences. To address these challenges, we reframe the task as a conditional set generation problem, proposing a Set-aligning Framework tailored for the effective utilisation of Large Language Models (LLMs). The framework incorporates data augmentations and set-property regularisations designed to alleviate text generation loss penalties associated with the linearised graph edge sequences, thus encouraging the generation of more relation edges. Experimental results show that our framework surpasses existing baselines for event temporal graph generation. Furthermore, under zero-shot settings, the structural knowledge introduced through our framework notably improves model generalisation, particularly when the training examples available are limited.
Large, Small or Both: A Novel Data Augmentation Framework Based on Language Models for Debiasing Opinion Summarization
Mar 19, 2024
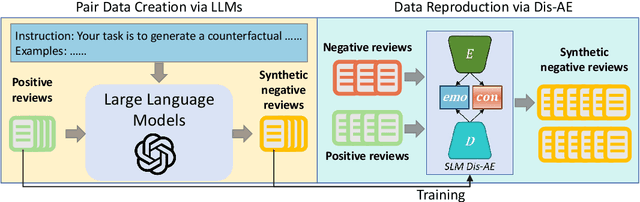
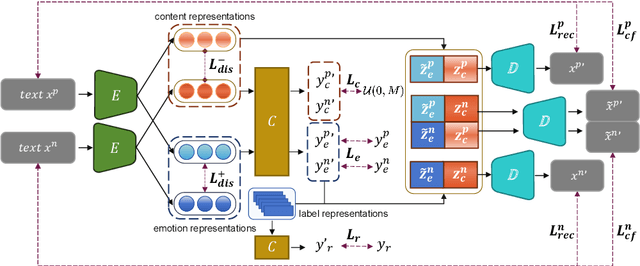
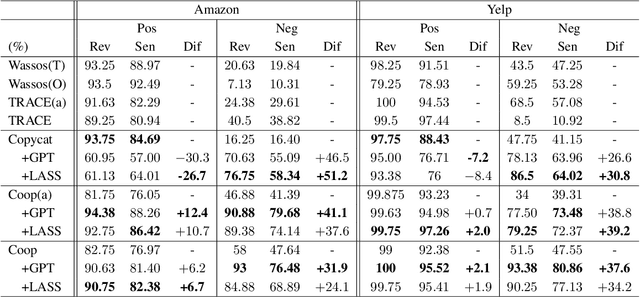
As more than 70$\%$ of reviews in the existing opinion summary data set are positive, current opinion summarization approaches are reluctant to generate negative summaries given the input of negative texts. To address such sentiment bias, a direct approach without the over-reliance on a specific framework is to generate additional data based on large language models to balance the emotional distribution of the dataset. However, data augmentation based on large language models faces two disadvantages: 1) the potential issues or toxicity in the augmented data; 2) the expensive costs. Therefore, in this paper, we propose a novel data augmentation framework based on both large and small language models for debiasing opinion summarization. In specific, a small size of synthesized negative reviews is obtained by rewriting the positive text via a large language model. Then, a disentangle reconstruction model is trained based on the generated data. After training, a large amount of synthetic data can be obtained by decoding the new representation obtained from the combination of different sample representations and filtering based on confusion degree and sentiment classification. Experiments have proved that our framework can effectively alleviate emotional bias same as using only large models, but more economically.
Scene Graph Aided Radiology Report Generation
Mar 08, 2024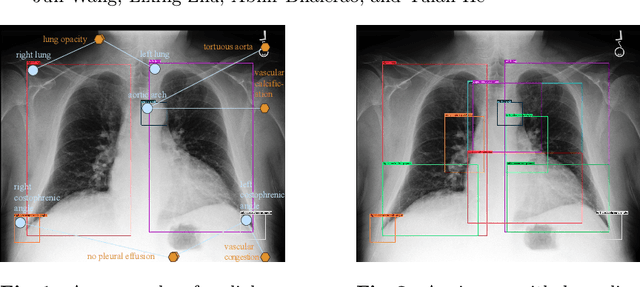
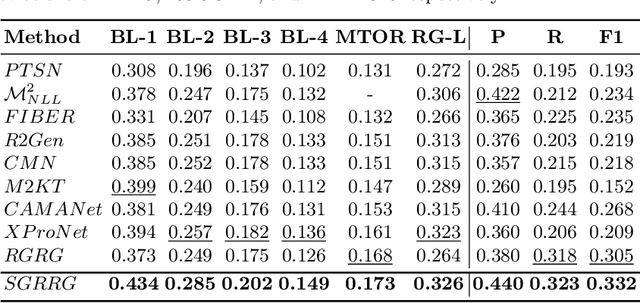
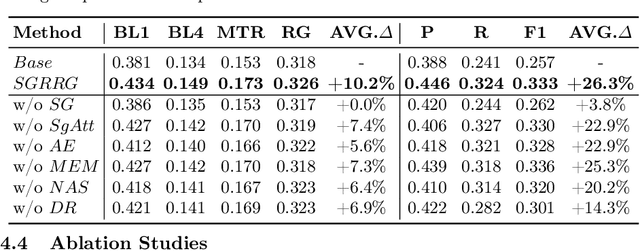

Radiology report generation (RRG) methods often lack sufficient medical knowledge to produce clinically accurate reports. The scene graph contains rich information to describe the objects in an image. We explore enriching the medical knowledge for RRG via a scene graph, which has not been done in the current RRG literature. To this end, we propose the Scene Graph aided RRG (SGRRG) network, a framework that generates region-level visual features, predicts anatomical attributes, and leverages an automatically generated scene graph, thus achieving medical knowledge distillation in an end-to-end manner. SGRRG is composed of a dedicated scene graph encoder responsible for translating the scene graph, and a scene graph-aided decoder that takes advantage of both patch-level and region-level visual information. A fine-grained, sentence-level attention method is designed to better dis-till the scene graph information. Extensive experiments demonstrate that SGRRG outperforms previous state-of-the-art methods in report generation and can better capture abnormal findings.
COPR: Continual Human Preference Learning via Optimal Policy Regularization
Feb 27, 2024Reinforcement Learning from Human Feedback (RLHF) is commonly utilized to improve the alignment of Large Language Models (LLMs) with human preferences. Given the evolving nature of human preferences, continual alignment becomes more crucial and practical in comparison to traditional static alignment. Nevertheless, making RLHF compatible with Continual Learning (CL) is challenging due to its complex process. Meanwhile, directly learning new human preferences may lead to Catastrophic Forgetting (CF) of historical preferences, resulting in helpless or harmful outputs. To overcome these challenges, we propose the Continual Optimal Policy Regularization (COPR) method, which draws inspiration from the optimal policy theory. COPR utilizes a sampling distribution as a demonstration and regularization constraints for CL. It adopts the Lagrangian Duality (LD) method to dynamically regularize the current policy based on the historically optimal policy, which prevents CF and avoids over-emphasizing unbalanced objectives. We also provide formal proof for the learnability of COPR. The experimental results show that COPR outperforms strong CL baselines on our proposed benchmark, in terms of reward-based, GPT-4 evaluations and human assessment. Furthermore, we validate the robustness of COPR under various CL settings, including different backbones, replay memory sizes, and learning orders.
Leveraging ChatGPT in Pharmacovigilance Event Extraction: An Empirical Study
Feb 24, 2024With the advent of large language models (LLMs), there has been growing interest in exploring their potential for medical applications. This research aims to investigate the ability of LLMs, specifically ChatGPT, in the context of pharmacovigilance event extraction, of which the main goal is to identify and extract adverse events or potential therapeutic events from textual medical sources. We conduct extensive experiments to assess the performance of ChatGPT in the pharmacovigilance event extraction task, employing various prompts and demonstration selection strategies. The findings demonstrate that while ChatGPT demonstrates reasonable performance with appropriate demonstration selection strategies, it still falls short compared to fully fine-tuned small models. Additionally, we explore the potential of leveraging ChatGPT for data augmentation. However, our investigation reveals that the inclusion of synthesized data into fine-tuning may lead to a decrease in performance, possibly attributed to noise in the ChatGPT-generated labels. To mitigate this, we explore different filtering strategies and find that, with the proper approach, more stable performance can be achieved, although constant improvement remains elusive.
Addressing Order Sensitivity of In-Context Demonstration Examples in Causal Language Models
Feb 23, 2024In-context learning has become a popular paradigm in natural language processing. However, its performance can be significantly influenced by the order of in-context demonstration examples. In this paper, we found that causal language models (CausalLMs) are more sensitive to this order compared to prefix language models (PrefixLMs). We attribute this phenomenon to the auto-regressive attention masks within CausalLMs, which restrict each token from accessing information from subsequent tokens. This results in different receptive fields for samples at different positions, thereby leading to representation disparities across positions. To tackle this challenge, we introduce an unsupervised fine-tuning method, termed the Information-Augmented and Consistency-Enhanced approach. This approach utilizes contrastive learning to align representations of in-context examples across different positions and introduces a consistency loss to ensure similar representations for inputs with different permutations. This enhances the model's predictive consistency across permutations. Experimental results on four benchmarks suggest that our proposed method can reduce the sensitivity to the order of in-context examples and exhibit robust generalizability, particularly when demonstrations are sourced from a pool different from that used in the training phase, or when the number of in-context examples differs from what is used during training.
Counterfactual Generation with Identifiability Guarantees
Feb 23, 2024Counterfactual generation lies at the core of various machine learning tasks, including image translation and controllable text generation. This generation process usually requires the identification of the disentangled latent representations, such as content and style, that underlie the observed data. However, it becomes more challenging when faced with a scarcity of paired data and labeling information. Existing disentangled methods crucially rely on oversimplified assumptions, such as assuming independent content and style variables, to identify the latent variables, even though such assumptions may not hold for complex data distributions. For instance, food reviews tend to involve words like tasty, whereas movie reviews commonly contain words such as thrilling for the same positive sentiment. This problem is exacerbated when data are sampled from multiple domains since the dependence between content and style may vary significantly over domains. In this work, we tackle the domain-varying dependence between the content and the style variables inherent in the counterfactual generation task. We provide identification guarantees for such latent-variable models by leveraging the relative sparsity of the influences from different latent variables. Our theoretical insights enable the development of a doMain AdapTive counTerfactual gEneration model, called (MATTE). Our theoretically grounded framework achieves state-of-the-art performance in unsupervised style transfer tasks, where neither paired data nor style labels are utilized, across four large-scale datasets. Code is available at https://github.com/hanqi-qi/Matte.git
Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning
Feb 22, 2024While Large language models (LLMs) have the capability to iteratively reflect on their own outputs, recent studies have observed their struggles with knowledge-rich problems without access to external resources. In addition to the inefficiency of LLMs in self-assessment, we also observe that LLMs struggle to revisit their predictions despite receiving explicit negative feedback. Therefore, We propose Mirror, a Multiple-perspective self-reflection method for knowledge-rich reasoning, to avoid getting stuck at a particular reflection iteration. Mirror enables LLMs to reflect from multiple-perspective clues, achieved through a heuristic interaction between a Navigator and a Reasoner. It guides agents toward diverse yet plausibly reliable reasoning trajectory without access to ground truth by encouraging (1) diversity of directions generated by Navigator and (2) agreement among strategically induced perturbations in responses generated by the Reasoner. The experiments on five reasoning datasets demonstrate that Mirror's superiority over several contemporary self-reflection approaches. Additionally, the ablation study studies clearly indicate that our strategies alleviate the aforementioned challenges.
Towards Unified Task Embeddings Across Multiple Models: Bridging the Gap for Prompt-Based Large Language Models and Beyond
Feb 22, 2024Task embedding, a meta-learning technique that captures task-specific information, has become prevalent, especially in areas such as multi-task learning, model editing, and interpretability. However, it faces challenges with the emergence of prompt-guided Large Language Models (LLMs) operating in a gradientfree manner. Existing task embedding methods rely on fine-tuned, task-specific language models, which hinders the adaptability of task embeddings across diverse models, especially prompt-based LLMs. To unleash the power of task embedding in the era of LLMs, we propose a framework for unified task embeddings (FUTE), harmonizing task embeddings from various models, including smaller language models and LLMs with varied prompts, within a single vector space. Such uniformity enables the comparison and analysis of similarities amongst different models, extending the scope and utility of existing task embedding methods in addressing multi-model scenarios, whilst maintaining their performance to be comparable to architecture-specific methods.