 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYue Yu
Heterogeneous Peridynamic Neural Operators: Discover Biotissue Constitutive Law and Microstructure From Digital Image Correlation Measurements
Mar 27, 2024
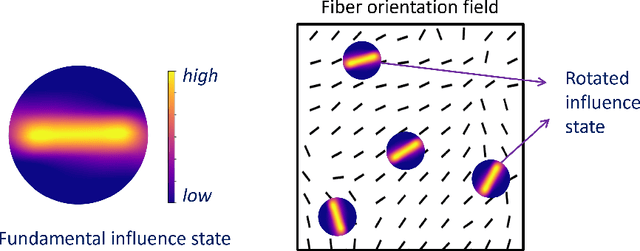
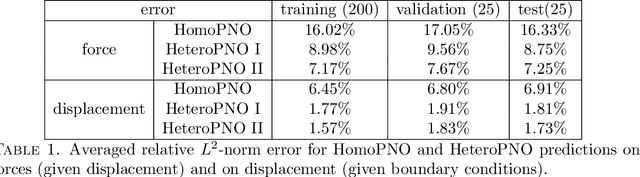
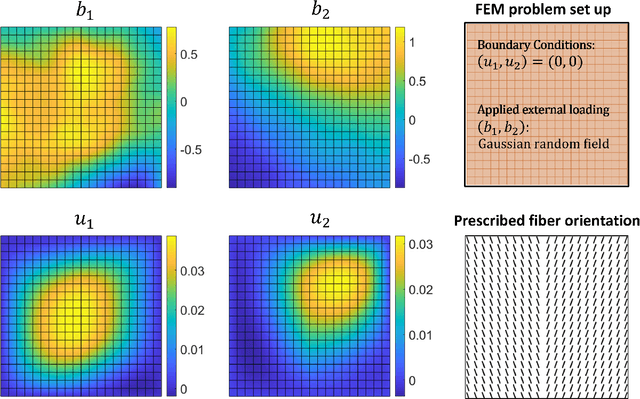
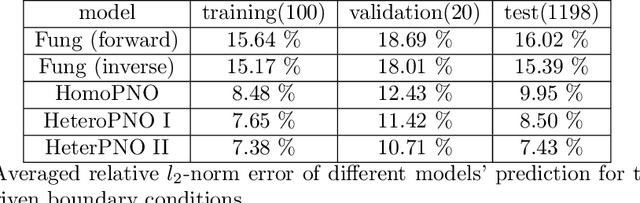
Human tissues are highly organized structures with specific collagen fiber arrangements varying from point to point. The effects of such heterogeneity play an important role for tissue function, and hence it is of critical to discover and understand the distribution of such fiber orientations from experimental measurements, such as the digital image correlation data. To this end, we introduce the heterogeneous peridynamic neural operator (HeteroPNO) approach, for data-driven constitutive modeling of heterogeneous anisotropic materials. The goal is to learn both a nonlocal constitutive law together with the material microstructure, in the form of a heterogeneous fiber orientation field, from loading field-displacement field measurements. To this end, we propose a two-phase learning approach. Firstly, we learn a homogeneous constitutive law in the form of a neural network-based kernel function and a nonlocal bond force, to capture complex homogeneous material responses from data. Then, in the second phase we reinitialize the learnt bond force and the kernel function, and training them together with a fiber orientation field for each material point. Owing to the state-based peridynamic skeleton, our HeteroPNO-learned material models are objective and have the balance of linear and angular momentum guaranteed. Moreover, the effects from heterogeneity and nonlinear constitutive relationship are captured by the kernel function and the bond force respectively, enabling physical interpretability. As a result, our HeteroPNO architecture can learn a constitutive model for a biological tissue with anisotropic heterogeneous response undergoing large deformation regime. Moreover, the framework is capable to provide displacement and stress field predictions for new and unseen loading instances.
GenView: Enhancing View Quality with Pretrained Generative Model for Self-Supervised Learning
Mar 18, 2024
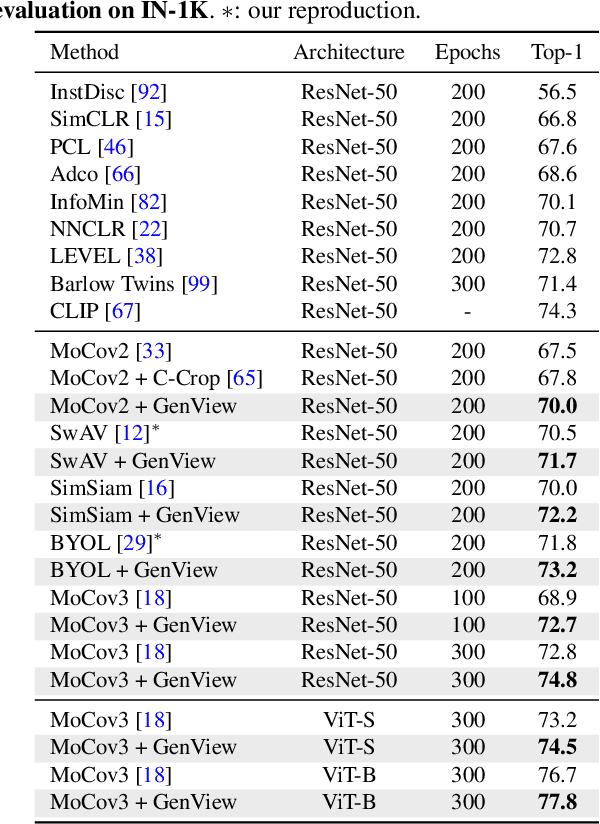
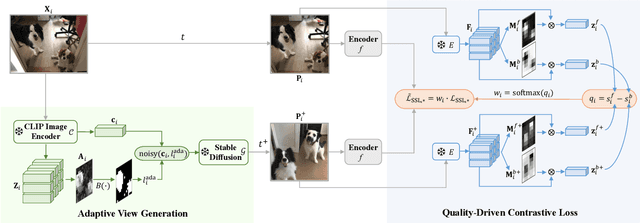
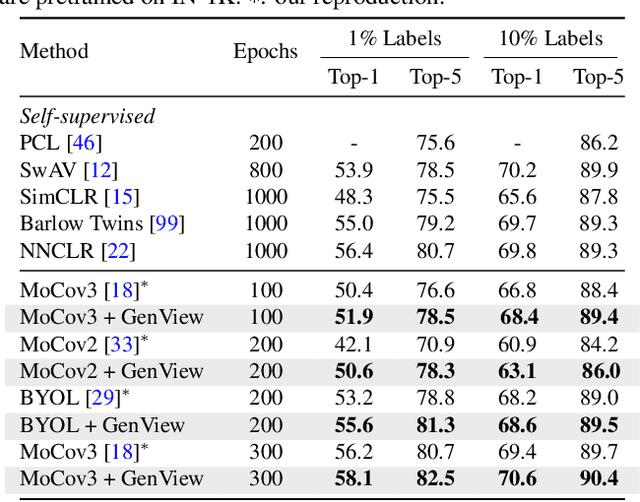
Self-supervised learning has achieved remarkable success in acquiring high-quality representations from unlabeled data. The widely adopted contrastive learning framework aims to learn invariant representations by minimizing the distance between positive views originating from the same image. However, existing techniques to construct positive views highly rely on manual transformations, resulting in limited diversity and potentially false positive pairs. To tackle these challenges, we present GenView, a controllable framework that augments the diversity of positive views leveraging the power of pretrained generative models while preserving semantics. We develop an adaptive view generation method that dynamically adjusts the noise level in sampling to ensure the preservation of essential semantic meaning while introducing variability. Additionally, we introduce a quality-driven contrastive loss, which assesses the quality of positive pairs by considering both foreground similarity and background diversity. This loss prioritizes the high-quality positive pairs we construct while reducing the influence of low-quality pairs, thereby mitigating potential semantic inconsistencies introduced by generative models and aggressive data augmentation. Thanks to the improved positive view quality and the quality-driven contrastive loss, GenView significantly improves self-supervised learning across various tasks. For instance, GenView improves MoCov2 performance by 2.5%/2.2% on ImageNet linear/semi-supervised classification. Moreover, GenView even performs much better than naively augmenting the ImageNet dataset with Laion400M or ImageNet21K. Code is available at https://github.com/xiaojieli0903/genview.
ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models
Mar 17, 2024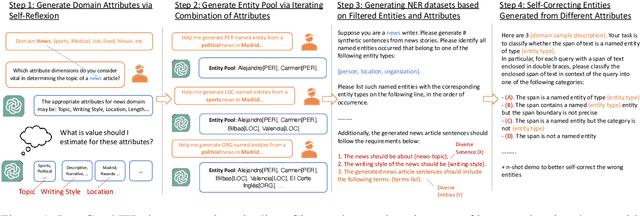

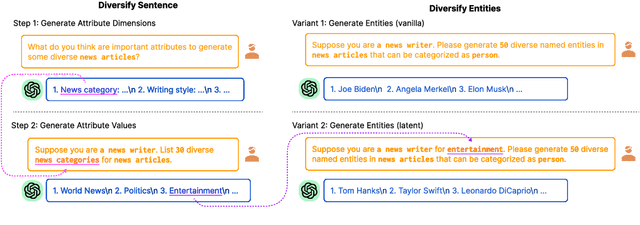

Although Large Language Models (LLMs) exhibit remarkable adaptability across domains, these models often fall short in structured knowledge extraction tasks such as named entity recognition (NER). This paper explores an innovative, cost-efficient strategy to harness LLMs with modest NER capabilities for producing superior NER datasets. Our approach diverges from the basic class-conditional prompts by instructing LLMs to self-reflect on the specific domain, thereby generating domain-relevant attributes (such as category and emotions for movie reviews), which are utilized for creating attribute-rich training data. Furthermore, we preemptively generate entity terms and then develop NER context data around these entities, effectively bypassing the LLMs' challenges with complex structures. Our experiments across both general and niche domains reveal significant performance enhancements over conventional data generation methods while being more cost-effective than existing alternatives.
VM-UNET-V2 Rethinking Vision Mamba UNet for Medical Image Segmentation
Mar 14, 2024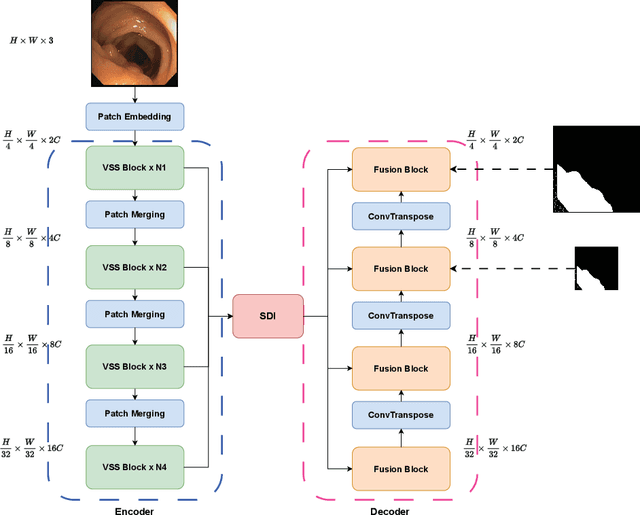
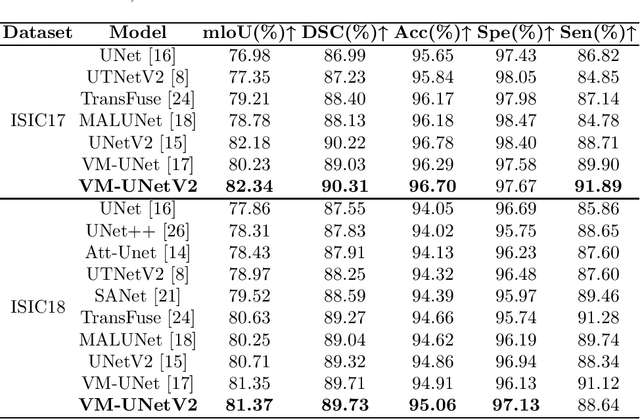
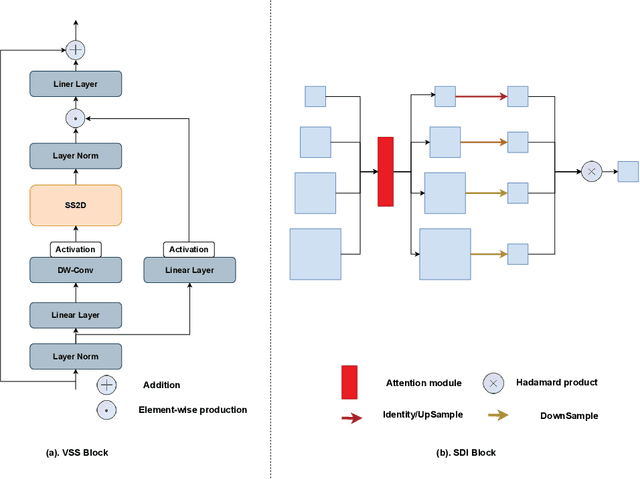
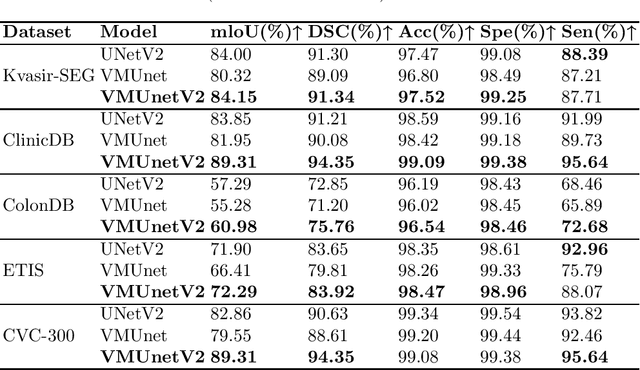
In the field of medical image segmentation, models based on both CNN and Transformer have been thoroughly investigated. However, CNNs have limited modeling capabilities for long-range dependencies, making it challenging to exploit the semantic information within images fully. On the other hand, the quadratic computational complexity poses a challenge for Transformers. Recently, State Space Models (SSMs), such as Mamba, have been recognized as a promising method. They not only demonstrate superior performance in modeling long-range interactions, but also preserve a linear computational complexity. Inspired by the Mamba architecture, We proposed Vison Mamba-UNetV2, the Visual State Space (VSS) Block is introduced to capture extensive contextual information, the Semantics and Detail Infusion (SDI) is introduced to augment the infusion of low-level and high-level features. We conduct comprehensive experiments on the ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir, CVC-ColonDB and ETIS-LaribPolypDB public datasets. The results indicate that VM-UNetV2 exhibits competitive performance in medical image segmentation tasks. Our code is available at https://github.com/nobodyplayer1/VM-UNetV2.
ACT-MNMT Auto-Constriction Turning for Multilingual Neural Machine Translation
Mar 11, 2024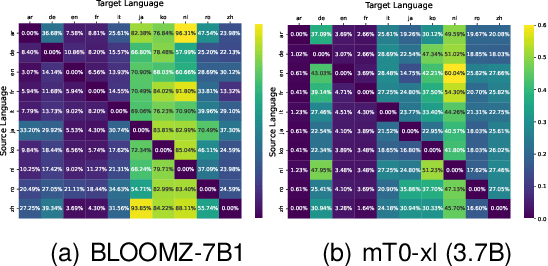

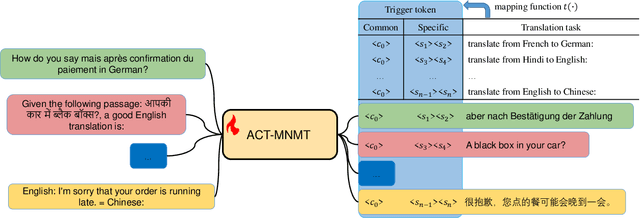
Large language model (LLM) has achieved promising performance in multilingual machine translation tasks through zero/few-shot prompts or prompt-tuning. However, due to the mixture of multilingual data during the pre-training of LLM, the LLM-based translation models face the off-target issue in both prompt-based methods, including a series of phenomena, namely instruction misunderstanding, translation with wrong language and over-generation. For this issue, this paper introduces an \textbf{\underline{A}}uto-\textbf{\underline{C}}onstriction \textbf{\underline{T}}urning mechanism for \textbf{\underline{M}}ultilingual \textbf{\underline{N}}eural \textbf{\underline{M}}achine \textbf{\underline{T}}ranslation (\model), which is a novel supervised fine-tuning mechanism and orthogonal to the traditional prompt-based methods. In this method, \model automatically constructs a constrained template in the target side by adding trigger tokens ahead of the ground truth. Furthermore, trigger tokens can be arranged and combined freely to represent different task semantics, and they can be iteratively updated to maximize the label likelihood. Experiments are performed on WMT test sets with multiple metrics, and the experimental results demonstrate that \model achieves substantially improved performance across multiple translation directions and reduce the off-target phenomena in the translation.
COPR: Continual Human Preference Learning via Optimal Policy Regularization
Feb 27, 2024Reinforcement Learning from Human Feedback (RLHF) is commonly utilized to improve the alignment of Large Language Models (LLMs) with human preferences. Given the evolving nature of human preferences, continual alignment becomes more crucial and practical in comparison to traditional static alignment. Nevertheless, making RLHF compatible with Continual Learning (CL) is challenging due to its complex process. Meanwhile, directly learning new human preferences may lead to Catastrophic Forgetting (CF) of historical preferences, resulting in helpless or harmful outputs. To overcome these challenges, we propose the Continual Optimal Policy Regularization (COPR) method, which draws inspiration from the optimal policy theory. COPR utilizes a sampling distribution as a demonstration and regularization constraints for CL. It adopts the Lagrangian Duality (LD) method to dynamically regularize the current policy based on the historically optimal policy, which prevents CF and avoids over-emphasizing unbalanced objectives. We also provide formal proof for the learnability of COPR. The experimental results show that COPR outperforms strong CL baselines on our proposed benchmark, in terms of reward-based, GPT-4 evaluations and human assessment. Furthermore, we validate the robustness of COPR under various CL settings, including different backbones, replay memory sizes, and learning orders.
RAM-EHR: Retrieval Augmentation Meets Clinical Predictions on Electronic Health Records
Feb 25, 2024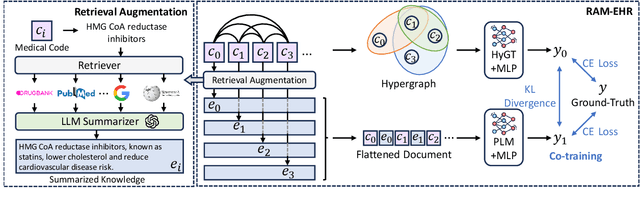
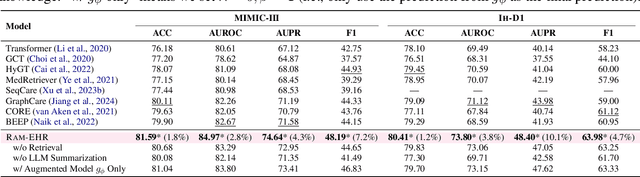

We present RAM-EHR, a Retrieval AugMentation pipeline to improve clinical predictions on Electronic Health Records (EHRs). RAM-EHR first collects multiple knowledge sources, converts them into text format, and uses dense retrieval to obtain information related to medical concepts. This strategy addresses the difficulties associated with complex names for the concepts. RAM-EHR then augments the local EHR predictive model co-trained with consistency regularization to capture complementary information from patient visits and summarized knowledge. Experiments on two EHR datasets show the efficacy of RAM-EHR over previous knowledge-enhanced baselines (3.4% gain in AUROC and 7.2% gain in AUPR), emphasizing the effectiveness of the summarized knowledge from RAM-EHR for clinical prediction tasks. The code will be published at \url{https://github.com/ritaranx/RAM-EHR}.
Multi-modal Stance Detection: New Datasets and Model
Feb 22, 2024Stance detection is a challenging task that aims to identify public opinion from social media platforms with respect to specific targets. Previous work on stance detection largely focused on pure texts. In this paper, we study multi-modal stance detection for tweets consisting of texts and images, which are prevalent in today's fast-growing social media platforms where people often post multi-modal messages. To this end, we create five new multi-modal stance detection datasets of different domains based on Twitter, in which each example consists of a text and an image. In addition, we propose a simple yet effective Targeted Multi-modal Prompt Tuning framework (TMPT), where target information is leveraged to learn multi-modal stance features from textual and visual modalities. Experimental results on our three benchmark datasets show that the proposed TMPT achieves state-of-the-art performance in multi-modal stance detection.
ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
Feb 21, 2024Retrieval-augmented generation enhances large language models (LLMs) by incorporating relevant information from external knowledge sources. This enables LLMs to adapt to specific domains and mitigate hallucinations in knowledge-intensive tasks. However, existing retrievers are often misaligned with LLMs due to their separate training processes and the black-box nature of LLMs. To address this challenge, we propose ARL2, a retriever learning technique that harnesses LLMs as labelers. ARL2 leverages LLMs to annotate and score relevant evidence, enabling learning the retriever from robust LLM supervision. Furthermore, ARL2 uses an adaptive self-training strategy for curating high-quality and diverse relevance data, which can effectively reduce the annotation cost. Extensive experiments demonstrate the effectiveness of ARL2, achieving accuracy improvements of 5.4% on NQ and 4.6% on MMLU compared to the state-of-the-art methods. Additionally, ARL2 exhibits robust transfer learning capabilities and strong zero-shot generalization abilities. Our code will be published at \url{https://github.com/zhanglingxi-cs/ARL2}.
Endowing Pre-trained Graph Models with Provable Fairness
Feb 20, 2024Pre-trained graph models (PGMs) aim to capture transferable inherent structural properties and apply them to different downstream tasks. Similar to pre-trained language models, PGMs also inherit biases from human society, resulting in discriminatory behavior in downstream applications. The debiasing process of existing fair methods is generally coupled with parameter optimization of GNNs. However, different downstream tasks may be associated with different sensitive attributes in reality, directly employing existing methods to improve the fairness of PGMs is inflexible and inefficient. Moreover, most of them lack a theoretical guarantee, i.e., provable lower bounds on the fairness of model predictions, which directly provides assurance in a practical scenario. To overcome these limitations, we propose a novel adapter-tuning framework that endows pre-trained graph models with provable fairness (called GraphPAR). GraphPAR freezes the parameters of PGMs and trains a parameter-efficient adapter to flexibly improve the fairness of PGMs in downstream tasks. Specifically, we design a sensitive semantic augmenter on node representations, to extend the node representations with different sensitive attribute semantics for each node. The extended representations will be used to further train an adapter, to prevent the propagation of sensitive attribute semantics from PGMs to task predictions. Furthermore, with GraphPAR, we quantify whether the fairness of each node is provable, i.e., predictions are always fair within a certain range of sensitive attribute semantics. Experimental evaluations on real-world datasets demonstrate that GraphPAR achieves state-of-the-art prediction performance and fairness on node classification task. Furthermore, based on our GraphPAR, around 90\% nodes have provable fairness.