 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLu Zhang
Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
Apr 08, 2024
Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
CORP: A Multi-Modal Dataset for Campus-Oriented Roadside Perception Tasks
Apr 04, 2024Numerous roadside perception datasets have been introduced to propel advancements in autonomous driving and intelligent transportation systems research and development. However, it has been observed that the majority of their concentrates is on urban arterial roads, inadvertently overlooking residential areas such as parks and campuses that exhibit entirely distinct characteristics. In light of this gap, we propose CORP, which stands as the first public benchmark dataset tailored for multi-modal roadside perception tasks under campus scenarios. Collected in a university campus, CORP consists of over 205k images plus 102k point clouds captured from 18 cameras and 9 LiDAR sensors. These sensors with different configurations are mounted on roadside utility poles to provide diverse viewpoints within the campus region. The annotations of CORP encompass multi-dimensional information beyond 2D and 3D bounding boxes, providing extra support for 3D seamless tracking and instance segmentation with unique IDs and pixel masks for identifying targets, to enhance the understanding of objects and their behaviors distributed across the campus premises. Unlike other roadside datasets about urban traffic, CORP extends the spectrum to highlight the challenges for multi-modal perception in campuses and other residential areas.
Heterogeneous Peridynamic Neural Operators: Discover Biotissue Constitutive Law and Microstructure From Digital Image Correlation Measurements
Mar 27, 2024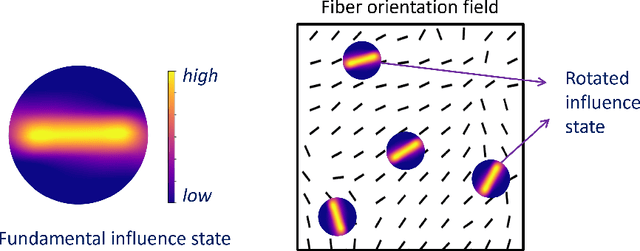
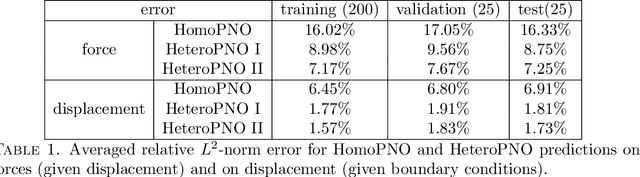
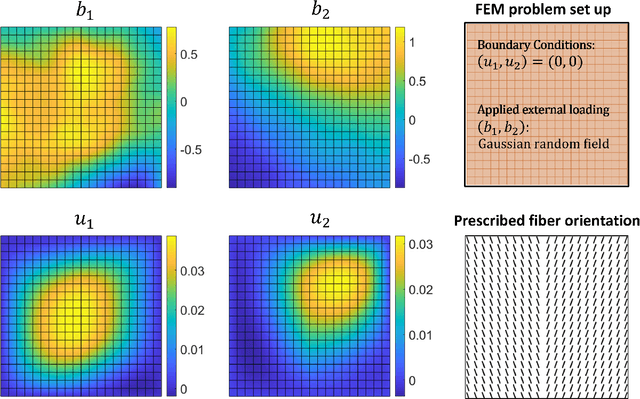
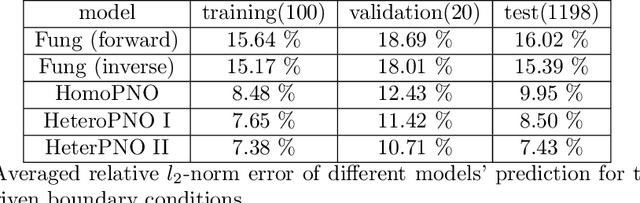
Human tissues are highly organized structures with specific collagen fiber arrangements varying from point to point. The effects of such heterogeneity play an important role for tissue function, and hence it is of critical to discover and understand the distribution of such fiber orientations from experimental measurements, such as the digital image correlation data. To this end, we introduce the heterogeneous peridynamic neural operator (HeteroPNO) approach, for data-driven constitutive modeling of heterogeneous anisotropic materials. The goal is to learn both a nonlocal constitutive law together with the material microstructure, in the form of a heterogeneous fiber orientation field, from loading field-displacement field measurements. To this end, we propose a two-phase learning approach. Firstly, we learn a homogeneous constitutive law in the form of a neural network-based kernel function and a nonlocal bond force, to capture complex homogeneous material responses from data. Then, in the second phase we reinitialize the learnt bond force and the kernel function, and training them together with a fiber orientation field for each material point. Owing to the state-based peridynamic skeleton, our HeteroPNO-learned material models are objective and have the balance of linear and angular momentum guaranteed. Moreover, the effects from heterogeneity and nonlinear constitutive relationship are captured by the kernel function and the bond force respectively, enabling physical interpretability. As a result, our HeteroPNO architecture can learn a constitutive model for a biological tissue with anisotropic heterogeneous response undergoing large deformation regime. Moreover, the framework is capable to provide displacement and stress field predictions for new and unseen loading instances.
Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters
Mar 18, 2024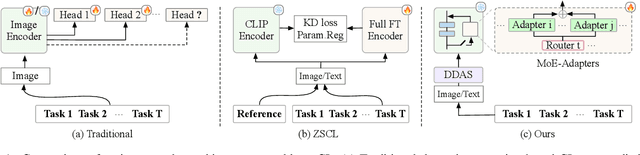
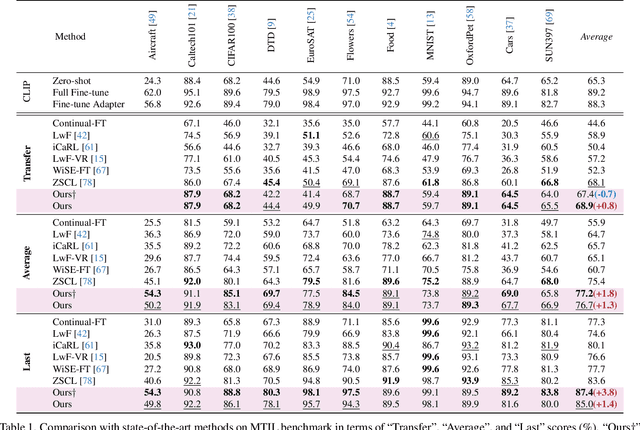
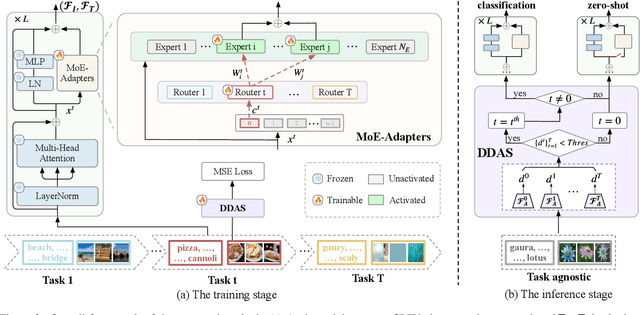
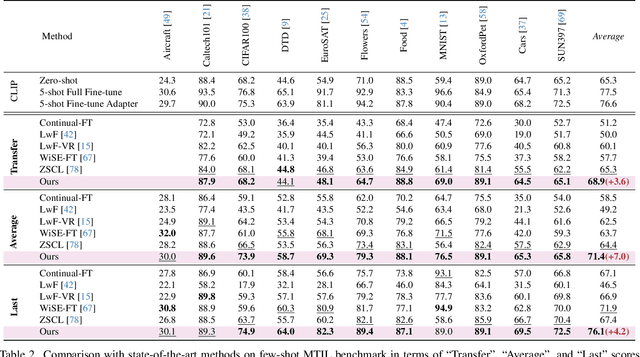
Continual learning can empower vision-language models to continuously acquire new knowledge, without the need for access to the entire historical dataset. However, mitigating the performance degradation in large-scale models is non-trivial due to (i) parameter shifts throughout lifelong learning and (ii) significant computational burdens associated with full-model tuning. In this work, we present a parameter-efficient continual learning framework to alleviate long-term forgetting in incremental learning with vision-language models. Our approach involves the dynamic expansion of a pre-trained CLIP model, through the integration of Mixture-of-Experts (MoE) adapters in response to new tasks. To preserve the zero-shot recognition capability of vision-language models, we further introduce a Distribution Discriminative Auto-Selector (DDAS) that automatically routes in-distribution and out-of-distribution inputs to the MoE Adapter and the original CLIP, respectively. Through extensive experiments across various settings, our proposed method consistently outperforms previous state-of-the-art approaches while concurrently reducing parameter training burdens by 60%. Our code locates at https://github.com/JiazuoYu/MoE-Adapters4CL
Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head
Mar 11, 2024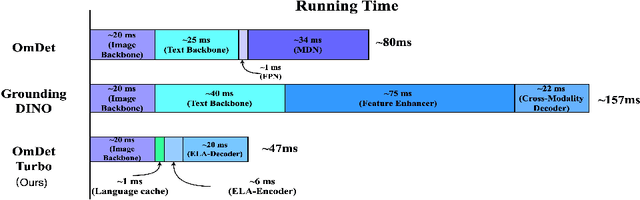
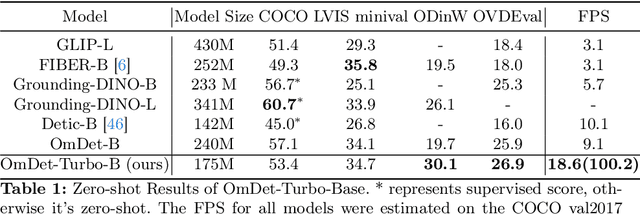
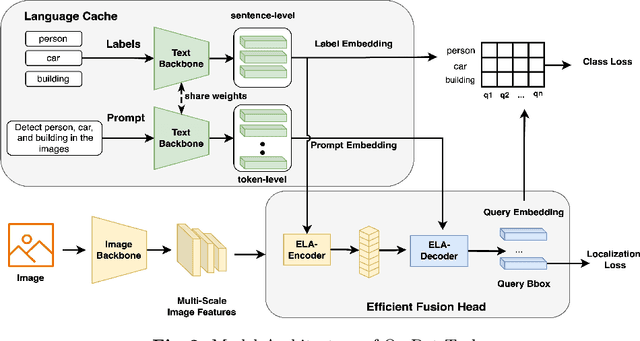

End-to-end transformer-based detectors (DETRs) have shown exceptional performance in both closed-set and open-vocabulary object detection (OVD) tasks through the integration of language modalities. However, their demanding computational requirements have hindered their practical application in real-time object detection (OD) scenarios. In this paper, we scrutinize the limitations of two leading models in the OVDEval benchmark, OmDet and Grounding-DINO, and introduce OmDet-Turbo. This novel transformer-based real-time OVD model features an innovative Efficient Fusion Head (EFH) module designed to alleviate the bottlenecks observed in OmDet and Grounding-DINO. Notably, OmDet-Turbo-Base achieves a 100.2 frames per second (FPS) with TensorRT and language cache techniques applied. Notably, in zero-shot scenarios on COCO and LVIS datasets, OmDet-Turbo achieves performance levels nearly on par with current state-of-the-art supervised models. Furthermore, it establishes new state-of-the-art benchmarks on ODinW and OVDEval, boasting an AP of 30.1 and an NMS-AP of 26.86, respectively. The practicality of OmDet-Turbo in industrial applications is underscored by its exceptional performance on benchmark datasets and superior inference speed, positioning it as a compelling choice for real-time object detection tasks. Code: \url{https://github.com/om-ai-lab/OmDet}
SIMPL: A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving
Feb 04, 2024This paper presents a Simple and effIcient Motion Prediction baseLine (SIMPL) for autonomous vehicles. Unlike conventional agent-centric methods with high accuracy but repetitive computations and scene-centric methods with compromised accuracy and generalizability, SIMPL delivers real-time, accurate motion predictions for all relevant traffic participants. To achieve improvements in both accuracy and inference speed, we propose a compact and efficient global feature fusion module that performs directed message passing in a symmetric manner, enabling the network to forecast future motion for all road users in a single feed-forward pass and mitigating accuracy loss caused by viewpoint shifting. Additionally, we investigate the continuous trajectory parameterization using Bernstein basis polynomials in trajectory decoding, allowing evaluations of states and their higher-order derivatives at any desired time point, which is valuable for downstream planning tasks. As a strong baseline, SIMPL exhibits highly competitive performance on Argoverse 1 & 2 motion forecasting benchmarks compared with other state-of-the-art methods. Furthermore, its lightweight design and low inference latency make SIMPL highly extensible and promising for real-world onboard deployment. We open-source the code at https://github.com/HKUST-Aerial-Robotics/SIMPL.
Long-Term Fair Decision Making through Deep Generative Models
Jan 20, 2024This paper studies long-term fair machine learning which aims to mitigate group disparity over the long term in sequential decision-making systems. To define long-term fairness, we leverage the temporal causal graph and use the 1-Wasserstein distance between the interventional distributions of different demographic groups at a sufficiently large time step as the quantitative metric. Then, we propose a three-phase learning framework where the decision model is trained on high-fidelity data generated by a deep generative model. We formulate the optimization problem as a performative risk minimization and adopt the repeated gradient descent algorithm for learning. The empirical evaluation shows the efficacy of the proposed method using both synthetic and semi-synthetic datasets.
Striking a Balance in Fairness for Dynamic Systems Through Reinforcement Learning
Jan 12, 2024While significant advancements have been made in the field of fair machine learning, the majority of studies focus on scenarios where the decision model operates on a static population. In this paper, we study fairness in dynamic systems where sequential decisions are made. Each decision may shift the underlying distribution of features or user behavior. We model the dynamic system through a Markov Decision Process (MDP). By acknowledging that traditional fairness notions and long-term fairness are distinct requirements that may not necessarily align with one another, we propose an algorithmic framework to integrate various fairness considerations with reinforcement learning using both pre-processing and in-processing approaches. Three case studies show that our method can strike a balance between traditional fairness notions, long-term fairness, and utility.
Scene 3-D Reconstruction System in Scattering Medium
Dec 14, 2023
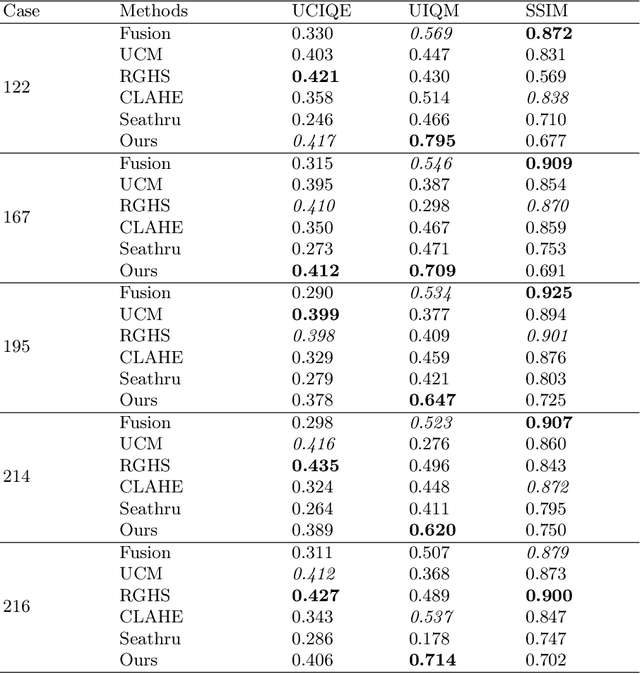


The research on neural radiance fields for new view synthesis has experienced explosive growth with the development of new models and extensions. The NERF algorithm, suitable for underwater scenes or scattering media, is also evolving. Existing underwater 3D reconstruction systems still face challenges such as extensive training time and low rendering efficiency. This paper proposes an improved underwater 3D reconstruction system to address these issues and achieve rapid, high-quality 3D reconstruction.To begin with, we enhance underwater videos captured by a monocular camera to correct the poor image quality caused by the physical properties of the water medium while ensuring consistency in enhancement across adjacent frames. Subsequently, we perform keyframe selection on the video frames to optimize resource utilization and eliminate the impact of dynamic objects on the reconstruction results. The selected keyframes, after pose estimation using COLMAP, undergo a three-dimensional reconstruction improvement process using neural radiance fields based on multi-resolution hash coding for model construction and rendering.
Long-Range Neural Atom Learning for Molecular Graphs
Nov 02, 2023Graph Neural Networks (GNNs) have been widely adopted for drug discovery with molecular graphs. Nevertheless, current GNNs are mainly good at leveraging short-range interactions (SRI) but struggle to capture long-range interactions (LRI), both of which are crucial for determining molecular properties. To tackle this issue, we propose a method that implicitly projects all original atoms into a few Neural Atoms, which abstracts the collective information of atomic groups within a molecule. Specifically, we explicitly exchange the information among neural atoms and project them back to the atoms' representations as an enhancement. With this mechanism, neural atoms establish the communication channels among distant nodes, effectively reducing the interaction scope of arbitrary node pairs into a single hop. To provide an inspection of our method from a physical perspective, we reveal its connection with the traditional LRI calculation method, Ewald Summation. We conduct extensive experiments on three long-range graph benchmarks, covering both graph-level and link-level tasks on molecular graphs. We empirically justify that our method can be equipped with an arbitrary GNN and help to capture LRI.