 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Duan
Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
Apr 08, 2024
Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
MM-Gaussian: 3D Gaussian-based Multi-modal Fusion for Localization and Reconstruction in Unbounded Scenes
Apr 05, 2024Localization and mapping are critical tasks for various applications such as autonomous vehicles and robotics. The challenges posed by outdoor environments present particular complexities due to their unbounded characteristics. In this work, we present MM-Gaussian, a LiDAR-camera multi-modal fusion system for localization and mapping in unbounded scenes. Our approach is inspired by the recently developed 3D Gaussians, which demonstrate remarkable capabilities in achieving high rendering quality and fast rendering speed. Specifically, our system fully utilizes the geometric structure information provided by solid-state LiDAR to address the problem of inaccurate depth encountered when relying solely on visual solutions in unbounded, outdoor scenarios. Additionally, we utilize 3D Gaussian point clouds, with the assistance of pixel-level gradient descent, to fully exploit the color information in photos, thereby achieving realistic rendering effects. To further bolster the robustness of our system, we designed a relocalization module, which assists in returning to the correct trajectory in the event of a localization failure. Experiments conducted in multiple scenarios demonstrate the effectiveness of our method.
CRPlace: Camera-Radar Fusion with BEV Representation for Place Recognition
Mar 22, 2024The integration of complementary characteristics from camera and radar data has emerged as an effective approach in 3D object detection. However, such fusion-based methods remain unexplored for place recognition, an equally important task for autonomous systems. Given that place recognition relies on the similarity between a query scene and the corresponding candidate scene, the stationary background of a scene is expected to play a crucial role in the task. As such, current well-designed camera-radar fusion methods for 3D object detection can hardly take effect in place recognition because they mainly focus on dynamic foreground objects. In this paper, a background-attentive camera-radar fusion-based method, named CRPlace, is proposed to generate background-attentive global descriptors from multi-view images and radar point clouds for accurate place recognition. To extract stationary background features effectively, we design an adaptive module that generates the background-attentive mask by utilizing the camera BEV feature and radar dynamic points. With the guidance of a background mask, we devise a bidirectional cross-attention-based spatial fusion strategy to facilitate comprehensive spatial interaction between the background information of the camera BEV feature and the radar BEV feature. As the first camera-radar fusion-based place recognition network, CRPlace has been evaluated thoroughly on the nuScenes dataset. The results show that our algorithm outperforms a variety of baseline methods across a comprehensive set of metrics (recall@1 reaches 91.2%).
Spatio-Temporal Fluid Dynamics Modeling via Physical-Awareness and Parameter Diffusion Guidance
Mar 18, 2024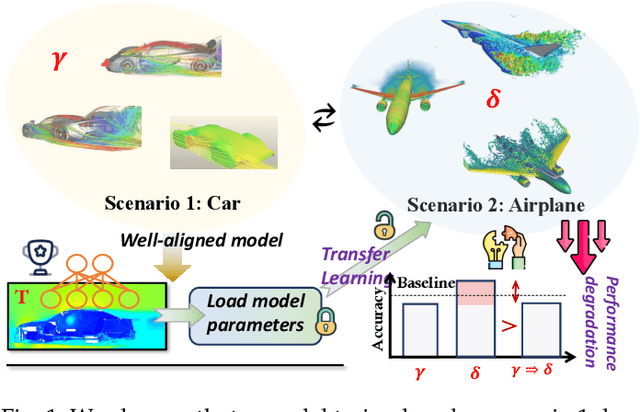
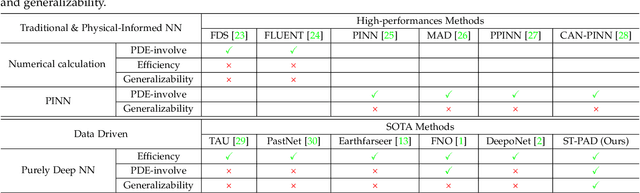
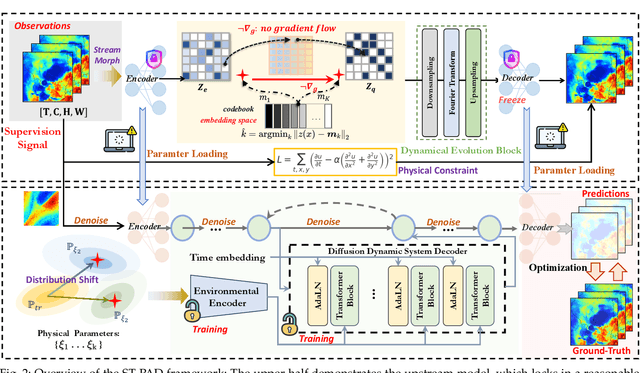
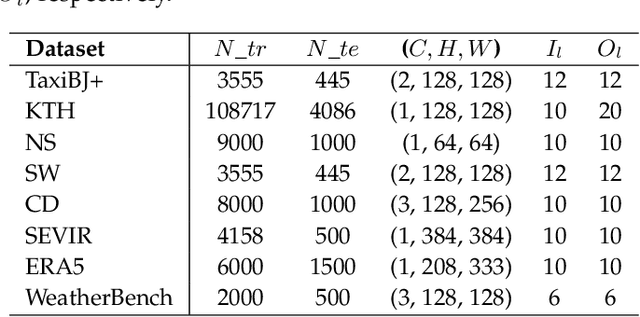
This paper proposes a two-stage framework named ST-PAD for spatio-temporal fluid dynamics modeling in the field of earth sciences, aiming to achieve high-precision simulation and prediction of fluid dynamics through spatio-temporal physics awareness and parameter diffusion guidance. In the upstream stage, we design a vector quantization reconstruction module with temporal evolution characteristics, ensuring balanced and resilient parameter distribution by introducing general physical constraints. In the downstream stage, a diffusion probability network involving parameters is utilized to generate high-quality future states of fluids, while enhancing the model's generalization ability by perceiving parameters in various physical setups. Extensive experiments on multiple benchmark datasets have verified the effectiveness and robustness of the ST-PAD framework, which showcase that ST-PAD outperforms current mainstream models in fluid dynamics modeling and prediction, especially in effectively capturing local representations and maintaining significant advantages in OOD generations.
mmPlace: Robust Place Recognition with Intermediate Frequency Signal of Low-cost Single-chip Millimeter Wave Radar
Mar 07, 2024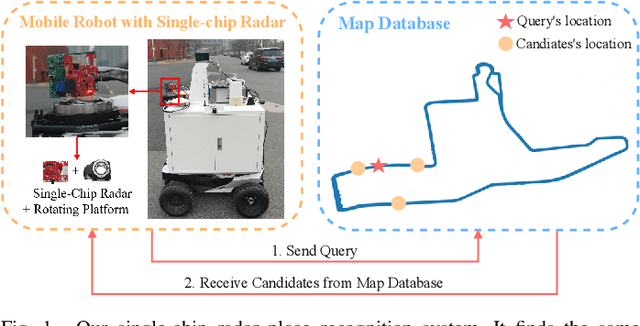

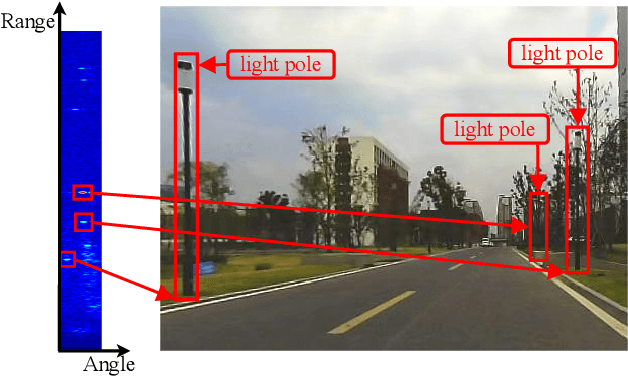
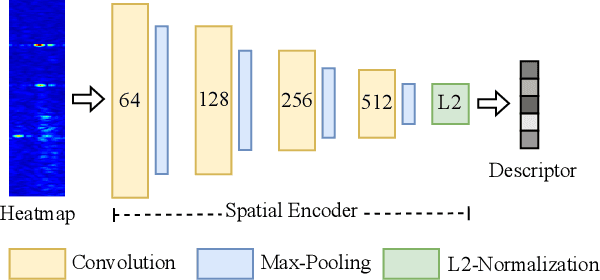
Place recognition is crucial for tasks like loop-closure detection and re-localization. Single-chip millimeter wave radar (single-chip radar in short) emerges as a low-cost sensor option for place recognition, with the advantage of insensitivity to degraded visual environments. However, it encounters two challenges. Firstly, sparse point cloud from single-chip radar leads to poor performance when using current place recognition methods, which assume much denser data. Secondly, its performance significantly declines in scenarios involving rotational and lateral variations, due to limited overlap in its field of view (FOV). We propose mmPlace, a robust place recognition system to address these challenges. Specifically, mmPlace transforms intermediate frequency (IF) signal into range azimuth heatmap and employs a spatial encoder to extract features. Additionally, to improve the performance in scenarios involving rotational and lateral variations, mmPlace employs a rotating platform and concatenates heatmaps in a rotation cycle, effectively expanding the system's FOV. We evaluate mmPlace's performance on the milliSonic dataset, which is collected on the University of Science and Technology of China (USTC) campus, the city roads surrounding the campus, and an underground parking garage. The results demonstrate that mmPlace outperforms point cloud-based methods and achieves 87.37% recall@1 in scenarios involving rotational and lateral variations.
CaT-GNN: Enhancing Credit Card Fraud Detection via Causal Temporal Graph Neural Networks
Feb 22, 2024Credit card fraud poses a significant threat to the economy. While Graph Neural Network (GNN)-based fraud detection methods perform well, they often overlook the causal effect of a node's local structure on predictions. This paper introduces a novel method for credit card fraud detection, the \textbf{\underline{Ca}}usal \textbf{\underline{T}}emporal \textbf{\underline{G}}raph \textbf{\underline{N}}eural \textbf{N}etwork (CaT-GNN), which leverages causal invariant learning to reveal inherent correlations within transaction data. By decomposing the problem into discovery and intervention phases, CaT-GNN identifies causal nodes within the transaction graph and applies a causal mixup strategy to enhance the model's robustness and interpretability. CaT-GNN consists of two key components: Causal-Inspector and Causal-Intervener. The Causal-Inspector utilizes attention weights in the temporal attention mechanism to identify causal and environment nodes without introducing additional parameters. Subsequently, the Causal-Intervener performs a causal mixup enhancement on environment nodes based on the set of nodes. Evaluated on three datasets, including a private financial dataset and two public datasets, CaT-GNN demonstrates superior performance over existing state-of-the-art methods. Our findings highlight the potential of integrating causal reasoning with graph neural networks to improve fraud detection capabilities in financial transactions.
EdgeCalib: Multi-Frame Weighted Edge Features for Automatic Targetless LiDAR-Camera Calibration
Oct 25, 2023In multimodal perception systems, achieving precise extrinsic calibration between LiDAR and camera is of critical importance. Previous calibration methods often required specific targets or manual adjustments, making them both labor-intensive and costly. Online calibration methods based on features have been proposed, but these methods encounter challenges such as imprecise feature extraction, unreliable cross-modality associations, and high scene-specific requirements. To address this, we introduce an edge-based approach for automatic online calibration of LiDAR and cameras in real-world scenarios. The edge features, which are prevalent in various environments, are aligned in both images and point clouds to determine the extrinsic parameters. Specifically, stable and robust image edge features are extracted using a SAM-based method and the edge features extracted from the point cloud are weighted through a multi-frame weighting strategy for feature filtering. Finally, accurate extrinsic parameters are optimized based on edge correspondence constraints. We conducted evaluations on both the KITTI dataset and our dataset. The results show a state-of-the-art rotation accuracy of 0.086{\deg} and a translation accuracy of 0.977 cm, outperforming existing edge-based calibration methods in both precision and robustness.
OCC-VO: Dense Mapping via 3D Occupancy-Based Visual Odometry for Autonomous Driving
Sep 20, 2023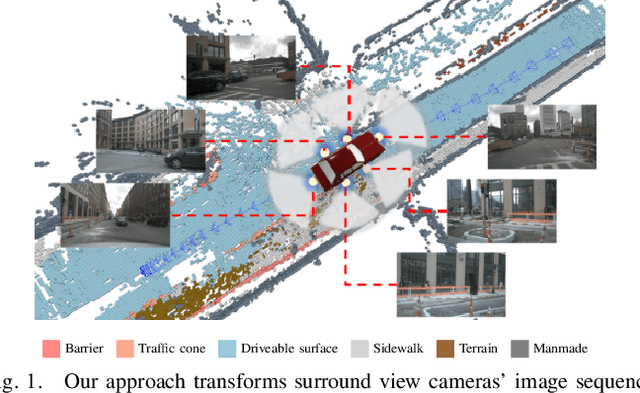
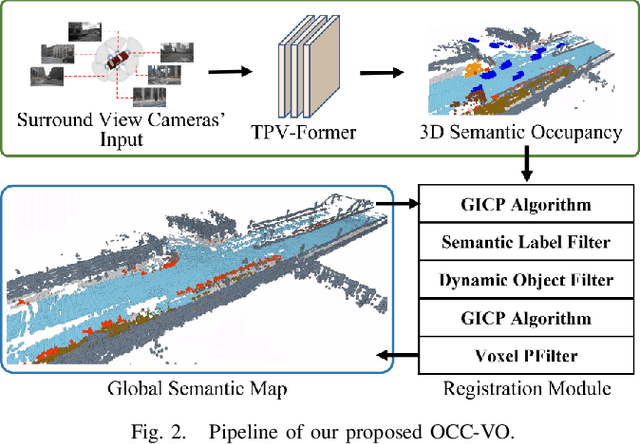
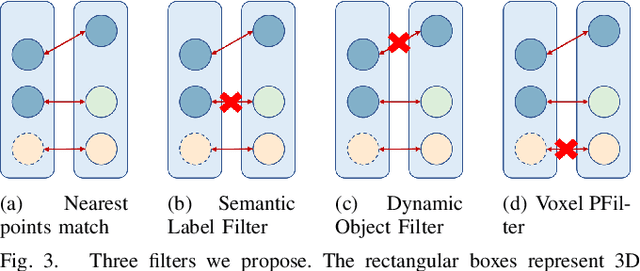
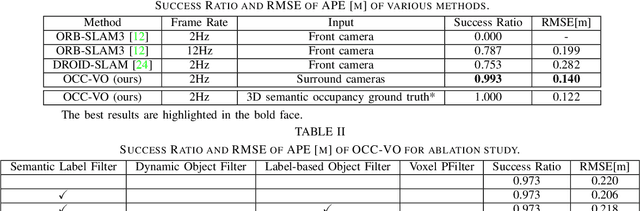
Visual Odometry (VO) plays a pivotal role in autonomous systems, with a principal challenge being the lack of depth information in camera images. This paper introduces OCC-VO, a novel framework that capitalizes on recent advances in deep learning to transform 2D camera images into 3D semantic occupancy, thereby circumventing the traditional need for concurrent estimation of ego poses and landmark locations. Within this framework, we utilize the TPV-Former to convert surround view cameras' images into 3D semantic occupancy. Addressing the challenges presented by this transformation, we have specifically tailored a pose estimation and mapping algorithm that incorporates Semantic Label Filter, Dynamic Object Filter, and finally, utilizes Voxel PFilter for maintaining a consistent global semantic map. Evaluations on the Occ3D-nuScenes not only showcase a 20.6% improvement in Success Ratio and a 29.6% enhancement in trajectory accuracy against ORB-SLAM3, but also emphasize our ability to construct a comprehensive map. Our implementation is open-sourced and available at: https://github.com/USTCLH/OCC-VO.
USTC FLICAR: A Multisensor Fusion Dataset of LiDAR-Inertial-Camera for Heavy-duty Autonomous Aerial Work Robots
Apr 04, 2023
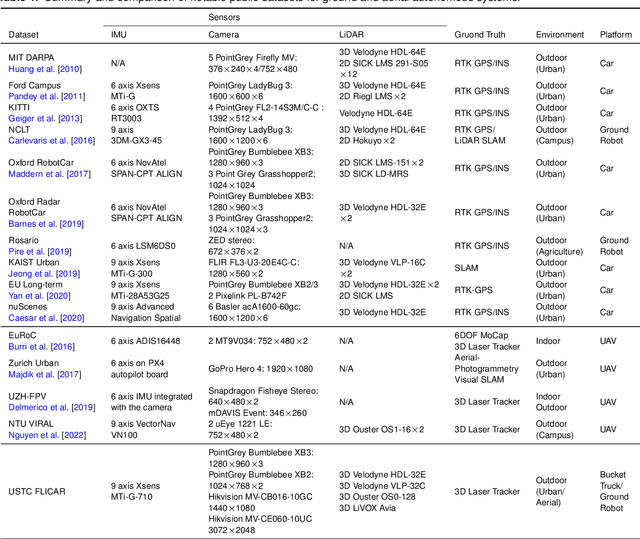

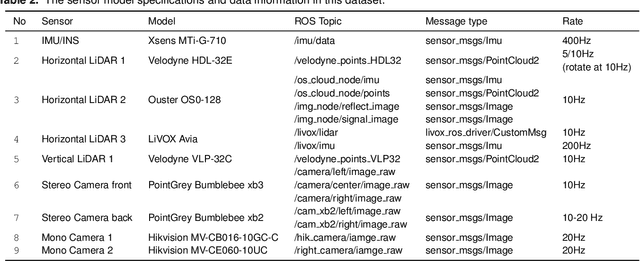
In this paper, we present the USTC FLICAR Dataset, which is dedicated to the development of simultaneous localization and mapping and precise 3D reconstruction of the workspace for heavy-duty autonomous aerial work robots. In recent years, numerous public datasets have played significant roles in the advancement of autonomous cars and unmanned aerial vehicles (UAVs). However, these two platforms differ from aerial work robots: UAVs are limited in their payload capacity, while cars are restricted to two-dimensional movements. To fill this gap, we create the Giraffe mapping robot based on a bucket truck, which is equipped with a variety of well-calibrated and synchronized sensors: four 3D LiDARs, two stereo cameras, two monocular cameras, Inertial Measurement Units (IMUs), and a GNSS/INS system. A laser tracker is used to record the millimeter-level ground truth positions. We also make its ground twin, the Okapi mapping robot, to gather data for comparison. The proposed dataset extends the typical autonomous driving sensing suite to aerial scenes. Therefore, the dataset is named FLICAR to denote flying cars. We believe this dataset can also represent the flying car scenarios, specifically the takeoff and landing of VTOL (Vertical Takeoff and Landing) flying cars. The dataset is available for download at: https://ustc-flicar.github.io.
$P^{3}O$: Transferring Visual Representations for Reinforcement Learning via Prompting
Mar 27, 2023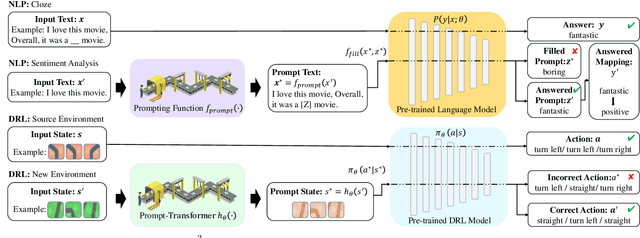
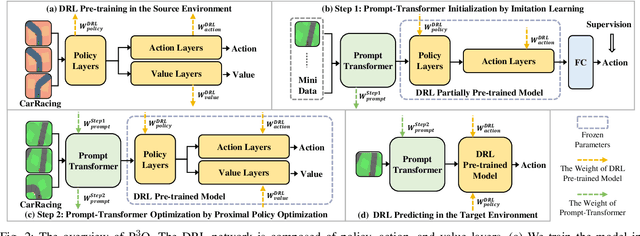
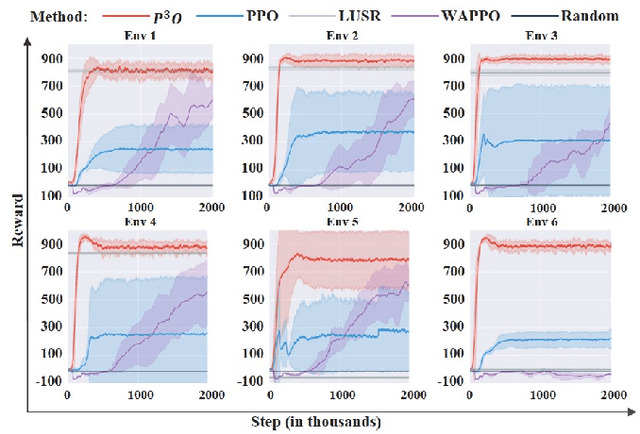
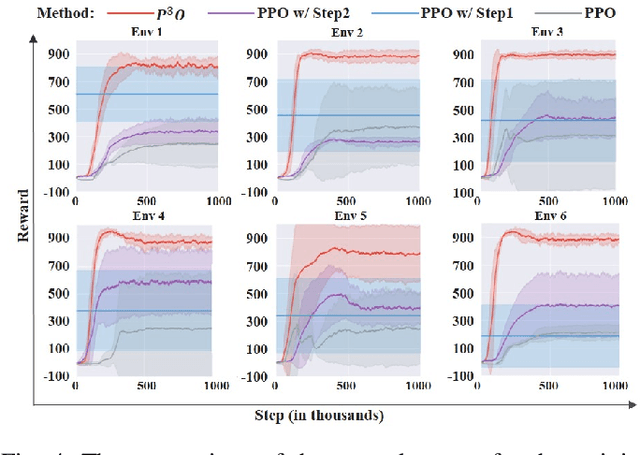
It is important for deep reinforcement learning (DRL) algorithms to transfer their learned policies to new environments that have different visual inputs. In this paper, we introduce Prompt based Proximal Policy Optimization ($P^{3}O$), a three-stage DRL algorithm that transfers visual representations from a target to a source environment by applying prompting. The process of $P^{3}O$ consists of three stages: pre-training, prompting, and predicting. In particular, we specify a prompt-transformer for representation conversion and propose a two-step training process to train the prompt-transformer for the target environment, while the rest of the DRL pipeline remains unchanged. We implement $P^{3}O$ and evaluate it on the OpenAI CarRacing video game. The experimental results show that $P^{3}O$ outperforms the state-of-the-art visual transferring schemes. In particular, $P^{3}O$ allows the learned policies to perform well in environments with different visual inputs, which is much more effective than retraining the policies in these environments.