 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeibei Wang
Robust Proximity Detection using On-Device Gait Monitoring
Apr 30, 2024
Proximity detection in indoor environments based on WiFi signals has gained significant attention in recent years. Existing works rely on the dynamic signal reflections and their extracted features are dependent on motion strength. To address this issue, we design a robust WiFi-based proximity detector by considering gait monitoring. Specifically, we propose a gait score that accurately evaluates gait presence by leveraging the speed estimated from the autocorrelation function (ACF) of channel state information (CSI). By combining this gait score with a proximity feature, our approach effectively distinguishes different transition patterns, enabling more reliable proximity detection. In addition, to enhance the stability of the detection process, we employ a state machine and extract temporal information, ensuring continuous proximity detection even during subtle movements. Extensive experiments conducted in different environments demonstrate an overall detection rate of 92.5% and a low false alarm rate of 1.12% with a delay of 0.825s.
CORP: A Multi-Modal Dataset for Campus-Oriented Roadside Perception Tasks
Apr 04, 2024Numerous roadside perception datasets have been introduced to propel advancements in autonomous driving and intelligent transportation systems research and development. However, it has been observed that the majority of their concentrates is on urban arterial roads, inadvertently overlooking residential areas such as parks and campuses that exhibit entirely distinct characteristics. In light of this gap, we propose CORP, which stands as the first public benchmark dataset tailored for multi-modal roadside perception tasks under campus scenarios. Collected in a university campus, CORP consists of over 205k images plus 102k point clouds captured from 18 cameras and 9 LiDAR sensors. These sensors with different configurations are mounted on roadside utility poles to provide diverse viewpoints within the campus region. The annotations of CORP encompass multi-dimensional information beyond 2D and 3D bounding boxes, providing extra support for 3D seamless tracking and instance segmentation with unique IDs and pixel masks for identifying targets, to enhance the understanding of objects and their behaviors distributed across the campus premises. Unlike other roadside datasets about urban traffic, CORP extends the spectrum to highlight the challenges for multi-modal perception in campuses and other residential areas.
mmID: High-Resolution mmWave Imaging for Human Identification
Feb 01, 2024Achieving accurate human identification through RF imaging has been a persistent challenge, primarily attributed to the limited aperture size and its consequent impact on imaging resolution. The existing imaging solution enables tasks such as pose estimation, activity recognition, and human tracking based on deep neural networks by estimating skeleton joints. In contrast to estimating joints, this paper proposes to improve imaging resolution by estimating the human figure as a whole using conditional generative adversarial networks (cGAN). In order to reduce training complexity, we use an estimated spatial spectrum using the MUltiple SIgnal Classification (MUSIC) algorithm as input to the cGAN. Our system generates environmentally independent, high-resolution images that can extract unique physical features useful for human identification. We use a simple convolution layers-based classification network to obtain the final identification result. From the experimental results, we show that resolution of the image produced by our trained generator is high enough to enable human identification. Our finding indicates high-resolution accuracy with 5% mean silhouette difference to the Kinect device. Extensive experiments in different environments on multiple testers demonstrate that our system can achieve 93% overall test accuracy in unseen environments for static human target identification.
Trustworthy Edge Machine Learning: A Survey
Oct 27, 2023The convergence of Edge Computing (EC) and Machine Learning (ML), known as Edge Machine Learning (EML), has become a highly regarded research area by utilizing distributed network resources to perform joint training and inference in a cooperative manner. However, EML faces various challenges due to resource constraints, heterogeneous network environments, and diverse service requirements of different applications, which together affect the trustworthiness of EML in the eyes of its stakeholders. This survey provides a comprehensive summary of definitions, attributes, frameworks, techniques, and solutions for trustworthy EML. Specifically, we first emphasize the importance of trustworthy EML within the context of Sixth-Generation (6G) networks. We then discuss the necessity of trustworthiness from the perspective of challenges encountered during deployment and real-world application scenarios. Subsequently, we provide a preliminary definition of trustworthy EML and explore its key attributes. Following this, we introduce fundamental frameworks and enabling technologies for trustworthy EML systems, and provide an in-depth literature review of the latest solutions to enhance trustworthiness of EML. Finally, we discuss corresponding research challenges and open issues.
EdgeCalib: Multi-Frame Weighted Edge Features for Automatic Targetless LiDAR-Camera Calibration
Oct 25, 2023In multimodal perception systems, achieving precise extrinsic calibration between LiDAR and camera is of critical importance. Previous calibration methods often required specific targets or manual adjustments, making them both labor-intensive and costly. Online calibration methods based on features have been proposed, but these methods encounter challenges such as imprecise feature extraction, unreliable cross-modality associations, and high scene-specific requirements. To address this, we introduce an edge-based approach for automatic online calibration of LiDAR and cameras in real-world scenarios. The edge features, which are prevalent in various environments, are aligned in both images and point clouds to determine the extrinsic parameters. Specifically, stable and robust image edge features are extracted using a SAM-based method and the edge features extracted from the point cloud are weighted through a multi-frame weighting strategy for feature filtering. Finally, accurate extrinsic parameters are optimized based on edge correspondence constraints. We conducted evaluations on both the KITTI dataset and our dataset. The results show a state-of-the-art rotation accuracy of 0.086{\deg} and a translation accuracy of 0.977 cm, outperforming existing edge-based calibration methods in both precision and robustness.
RadioSES: mmWave-Based Audioradio Speech Enhancement and Separation System
Apr 14, 2022



Speech enhancement and separation have been a long-standing problem, especially with the recent advances using a single microphone. Although microphones perform well in constrained settings, their performance for speech separation decreases in noisy conditions. In this work, we propose RadioSES, an audioradio speech enhancement and separation system that overcomes inherent problems in audio-only systems. By fusing a complementary radio modality, RadioSES can estimate the number of speakers, solve source association problem, separate and enhance noisy mixture speeches, and improve both intelligibility and perceptual quality. We perform millimeter-wave sensing to detect and localize speakers, and introduce an audioradio deep learning framework to fuse the separate radio features with the mixed audio features. Extensive experiments using commercial off-the-shelf devices show that RadioSES outperforms a variety of state-of-the-art baselines, with consistent performance gains in different environmental settings. Compared with the audiovisual methods, RadioSES provides similar improvements (e.g., ~3 dB gains in SiSDR), along with the benefits of lower computational complexity and being less privacy concerning.
Generalizing Aggregation Functions in GNNs:High-Capacity GNNs via Nonlinear Neighborhood Aggregators
Feb 18, 2022



Graph neural networks (GNNs) have achieved great success in many graph learning tasks. The main aspect powering existing GNNs is the multi-layer network architecture to learn the nonlinear graph representations for the specific learning tasks. The core operation in GNNs is message propagation in which each node updates its representation by aggregating its neighbors' representations. Existing GNNs mainly adopt either linear neighborhood aggregation (mean,sum) or max aggregator in their message propagation. (1) For linear aggregators, the whole nonlinearity and network's capacity of GNNs are generally limited due to deeper GNNs usually suffer from over-smoothing issue. (2) For max aggregator, it usually fails to be aware of the detailed information of node representations within neighborhood. To overcome these issues, we re-think the message propagation mechanism in GNNs and aim to develop the general nonlinear aggregators for neighborhood information aggregation in GNNs. One main aspect of our proposed nonlinear aggregators is that they provide the optimally balanced aggregators between max and mean/sum aggregations. Thus, our aggregators can inherit both (i) high nonlinearity that increases network's capacity and (ii) detail-sensitivity that preserves the detailed information of representations together in GNNs' message propagation. Promising experiments on several datasets show the effectiveness of the proposed nonlinear aggregators.
Neural BRDFs: Representation and Operations
Nov 14, 2021



Bidirectional reflectance distribution functions (BRDFs) are pervasively used in computer graphics to produce realistic physically-based appearance. In recent years, several works explored using neural networks to represent BRDFs, taking advantage of neural networks' high compression rate and their ability to fit highly complex functions. However, once represented, the BRDFs will be fixed and therefore lack flexibility to take part in follow-up operations. In this paper, we present a form of "Neural BRDF algebra", and focus on both representation and operations of BRDFs at the same time. We propose a representation neural network to compress BRDFs into latent vectors, which is able to represent BRDFs accurately. We further propose several operations that can be applied solely in the latent space, such as layering and interpolation. Spatial variation is straightforward to achieve by using textures of latent vectors. Furthermore, our representation can be efficiently evaluated and sampled, providing a competitive solution to more expensive Monte Carlo layering approaches.
SVBRDF Recovery From a Single Image With Highlights using a Pretrained Generative Adversarial Network
Oct 29, 2021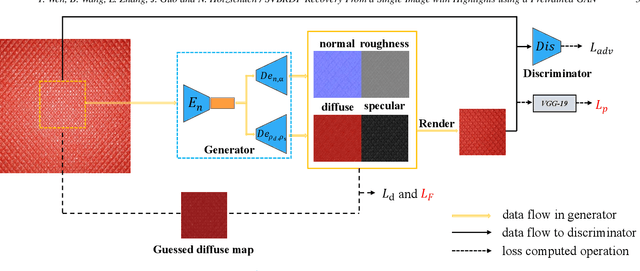
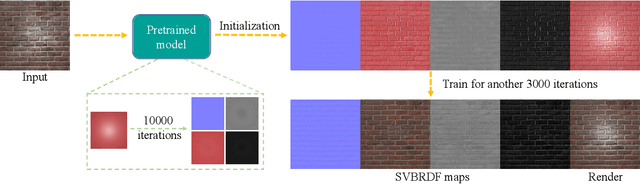
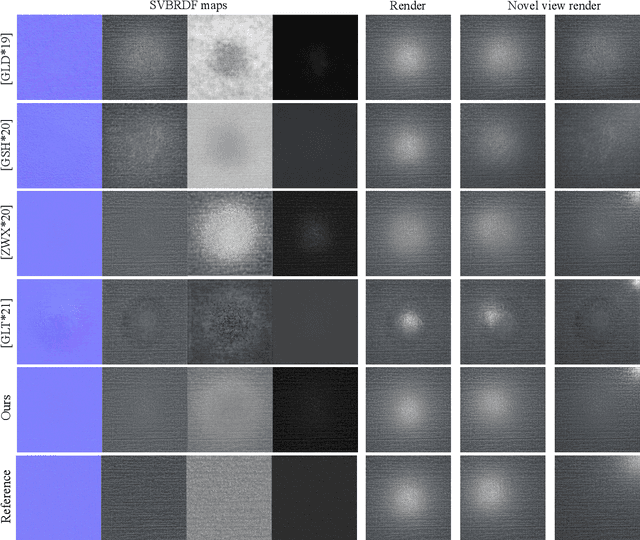

Spatially-varying bi-directional reflectance distribution functions (SVBRDFs) are crucial for designers to incorporate new materials in virtual scenes, making them look more realistic. Reconstruction of SVBRDFs is a long-standing problem. Existing methods either rely on extensive acquisition system or require huge datasets which are nontrivial to acquire. We aim to recover SVBRDFs from a single image, without any datasets. A single image contains incomplete information about the SVBRDF, making the reconstruction task highly ill-posed. It is also difficult to separate between the changes in color that are caused by the material and those caused by the illumination, without the prior knowledge learned from the dataset. In this paper, we use an unsupervised generative adversarial neural network (GAN) to recover SVBRDFs maps with a single image as input. To better separate the effects due to illumination from the effects due to the material, we add the hypothesis that the material is stationary and introduce a new loss function based on Fourier coefficients to enforce this stationarity. For efficiency, we train the network in two stages: reusing a trained model to initialize the SVBRDFs and fine-tune it based on the input image. Our method generates high-quality SVBRDFs maps from a single input photograph, and provides more vivid rendering results compared to previous work. The two-stage training boosts runtime performance, making it 8 times faster than previous work.
RadioMic: Sound Sensing via mmWave Signals
Aug 06, 2021



Voice interfaces has become an integral part of our lives, with the proliferation of smart devices. Today, IoT devices mainly rely on microphones to sense sound. Microphones, however, have fundamental limitations, such as weak source separation, limited range in the presence of acoustic insulation, and being prone to multiple side-channel attacks. In this paper, we propose RadioMic, a radio-based sound sensing system to mitigate these issues and enrich sound applications. RadioMic constructs sound based on tiny vibrations on active sources (e.g., a speaker or human throat) or object surfaces (e.g., paper bag), and can work through walls, even a soundproof one. To convert the extremely weak sound vibration in the radio signals into sound signals, RadioMic introduces radio acoustics, and presents training-free approaches for robust sound detection and high-fidelity sound recovery. It then exploits a neural network to further enhance the recovered sound by expanding the recoverable frequencies and reducing the noises. RadioMic translates massive online audios to synthesized data to train the network, and thus minimizes the need of RF data. We thoroughly evaluate RadioMic under different scenarios using a commodity mmWave radar. The results show RadioMic outperforms the state-of-the-art systems significantly. We believe RadioMic provides new horizons for sound sensing and inspires attractive sensing capabilities of mmWave sensing devices