 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Guo
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024
This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024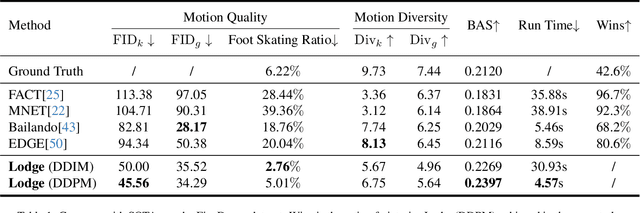
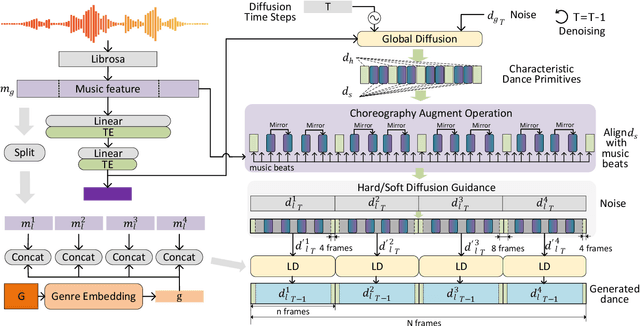
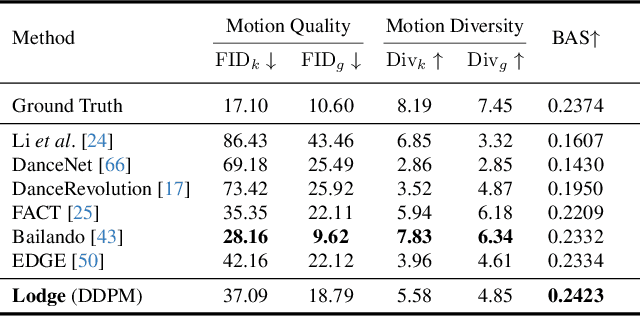
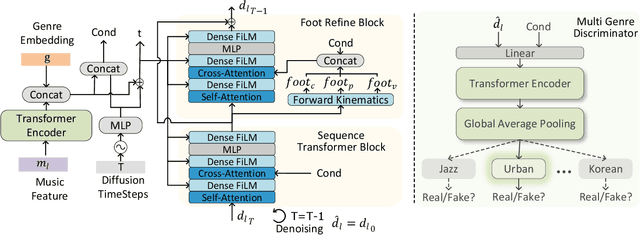
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
Semantic Human Mesh Reconstruction with Textures
Mar 05, 2024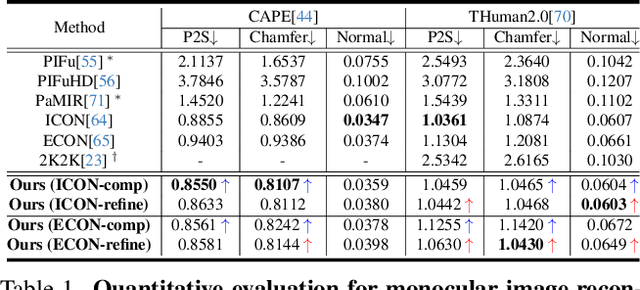
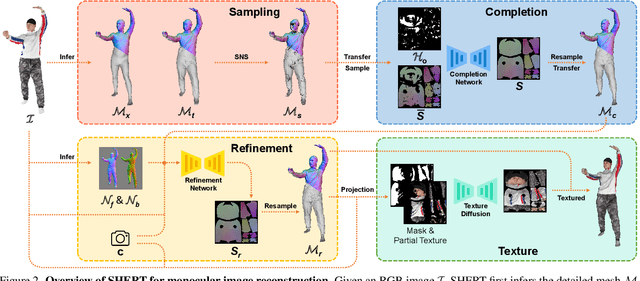
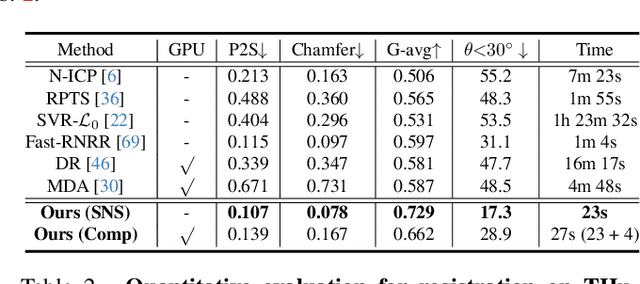
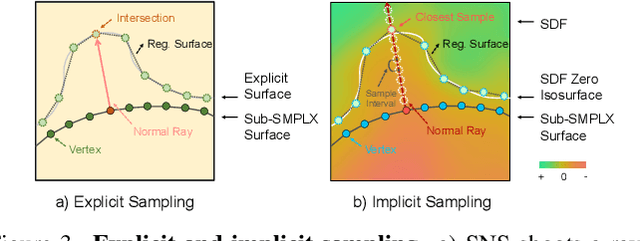
The field of 3D detailed human mesh reconstruction has made significant progress in recent years. However, current methods still face challenges when used in industrial applications due to unstable results, low-quality meshes, and a lack of UV unwrapping and skinning weights. In this paper, we present SHERT, a novel pipeline that can reconstruct semantic human meshes with textures and high-precision details. SHERT applies semantic- and normal-based sampling between the detailed surface (eg mesh and SDF) and the corresponding SMPL-X model to obtain a partially sampled semantic mesh and then generates the complete semantic mesh by our specifically designed self-supervised completion and refinement networks. Using the complete semantic mesh as a basis, we employ a texture diffusion model to create human textures that are driven by both images and texts. Our reconstructed meshes have stable UV unwrapping, high-quality triangle meshes, and consistent semantic information. The given SMPL-X model provides semantic information and shape priors, allowing SHERT to perform well even with incorrect and incomplete inputs. The semantic information also makes it easy to substitute and animate different body parts such as the face, body, and hands. Quantitative and qualitative experiments demonstrate that SHERT is capable of producing high-fidelity and robust semantic meshes that outperform state-of-the-art methods.
Optimal Projection for 3D Gaussian Splatting
Feb 02, 20243D Gaussian Splatting has garnered extensive attention and application in real-time neural rendering. Concurrently, concerns have been raised about the limitations of this technology in aspects such as point cloud storage, performance , and robustness in sparse viewpoints , leading to various improvements. However, there has been a notable lack of attention to the projection errors introduced by the local affine approximation inherent in the splatting itself, and the consequential impact of these errors on the quality of photo-realistic rendering. This paper addresses the projection error function of 3D Gaussian Splatting, commencing with the residual error from the first-order Taylor expansion of the projection function $\phi$. The analysis establishes a correlation between the error and the Gaussian mean position. Subsequently, leveraging function optimization theory, this paper analyzes the function's minima to provide an optimal projection strategy for Gaussian Splatting referred to Optimal Gaussian Splatting. Experimental validation further confirms that this projection methodology reduces artifacts, resulting in a more convincingly realistic rendering.
360-GS: Layout-guided Panoramic Gaussian Splatting For Indoor Roaming
Feb 01, 20243D Gaussian Splatting (3D-GS) has recently attracted great attention with real-time and photo-realistic renderings. This technique typically takes perspective images as input and optimizes a set of 3D elliptical Gaussians by splatting them onto the image planes, resulting in 2D Gaussians. However, applying 3D-GS to panoramic inputs presents challenges in effectively modeling the projection onto the spherical surface of ${360^\circ}$ images using 2D Gaussians. In practical applications, input panoramas are often sparse, leading to unreliable initialization of 3D Gaussians and subsequent degradation of 3D-GS quality. In addition, due to the under-constrained geometry of texture-less planes (e.g., walls and floors), 3D-GS struggles to model these flat regions with elliptical Gaussians, resulting in significant floaters in novel views. To address these issues, we propose 360-GS, a novel $360^{\circ}$ Gaussian splatting for a limited set of panoramic inputs. Instead of splatting 3D Gaussians directly onto the spherical surface, 360-GS projects them onto the tangent plane of the unit sphere and then maps them to the spherical projections. This adaptation enables the representation of the projection using Gaussians. We guide the optimization of 360-GS by exploiting layout priors within panoramas, which are simple to obtain and contain strong structural information about the indoor scene. Our experimental results demonstrate that 360-GS allows panoramic rendering and outperforms state-of-the-art methods with fewer artifacts in novel view synthesis, thus providing immersive roaming in indoor scenarios.
Distributed Task-Oriented Communication Networks with Multimodal Semantic Relay and Edge Intelligence
Jan 19, 2024In this article, we present a novel framework, named distributed task-oriented communication networks (DTCN), based on recent advances in multimodal semantic transmission and edge intelligence. In DTCN, the multimodal knowledge of semantic relays and the adaptive adjustment capability of edge intelligence can be integrated to improve task performance. Specifically, we propose the key techniques in the framework, such as semantic alignment and complement, a semantic relay scheme for deep joint source-channel relay coding, and collaborative device-server optimization and inference. Furthermore, a multimodal classification task is used as an example to demonstrate the benefits of the proposed DTCN over existing methods. Numerical results validate that DTCN can significantly improve the accuracy of classification tasks, even in harsh communication scenarios (e.g., low signal-to-noise regime), thanks to multimodal semantic relay and edge intelligence.
Exploring Multi-Modal Control in Music-Driven Dance Generation
Jan 01, 2024Existing music-driven 3D dance generation methods mainly concentrate on high-quality dance generation, but lack sufficient control during the generation process. To address these issues, we propose a unified framework capable of generating high-quality dance movements and supporting multi-modal control, including genre control, semantic control, and spatial control. First, we decouple the dance generation network from the dance control network, thereby avoiding the degradation in dance quality when adding additional control information. Second, we design specific control strategies for different control information and integrate them into a unified framework. Experimental results show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and controllability.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023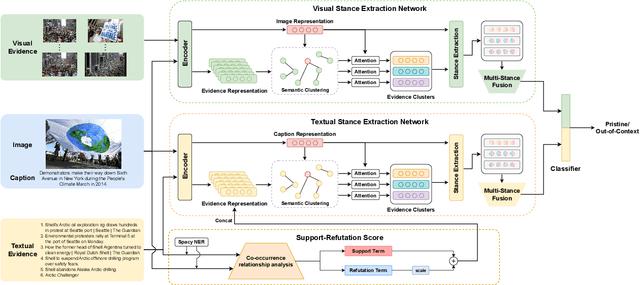
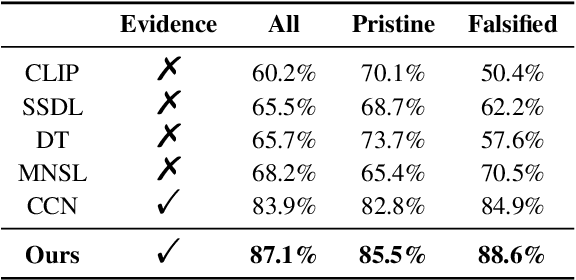
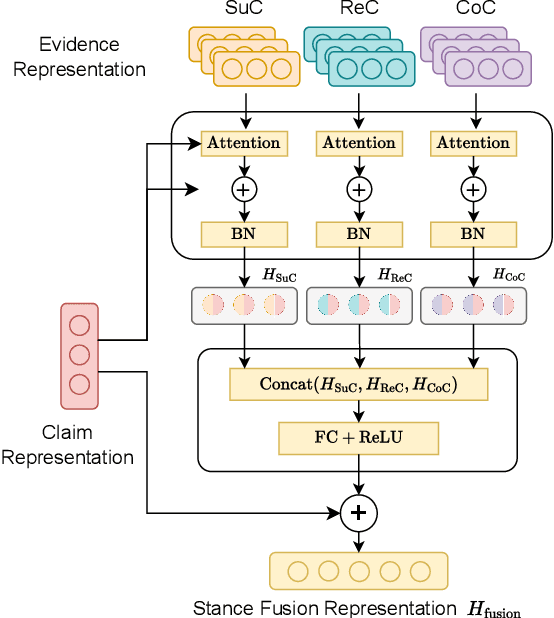
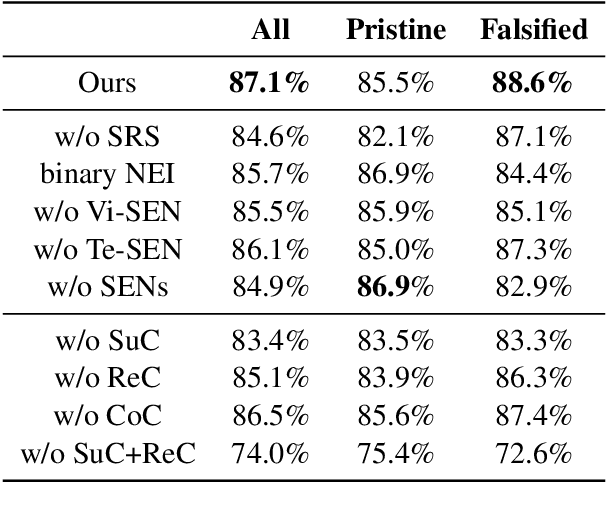
Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.
ESSAformer: Efficient Transformer for Hyperspectral Image Super-resolution
Jul 26, 2023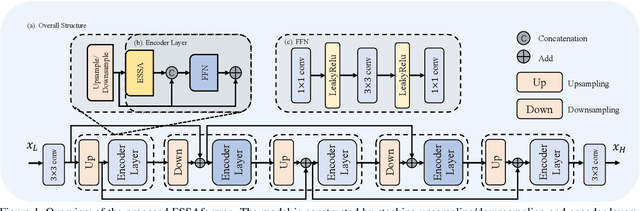

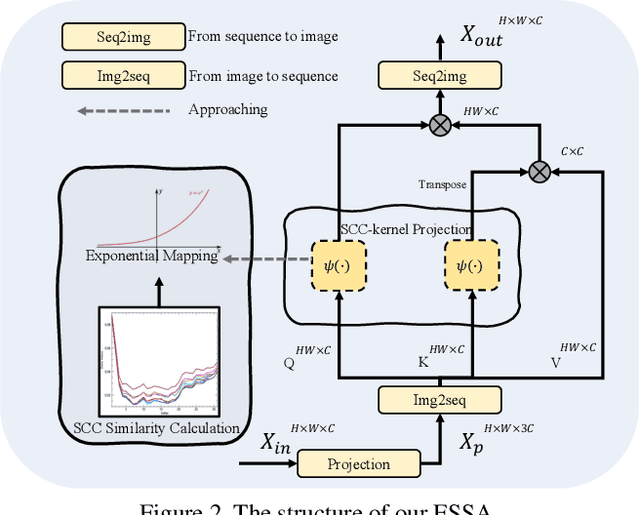
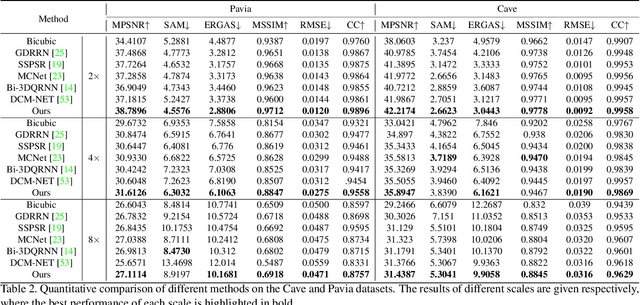
Single hyperspectral image super-resolution (single-HSI-SR) aims to restore a high-resolution hyperspectral image from a low-resolution observation. However, the prevailing CNN-based approaches have shown limitations in building long-range dependencies and capturing interaction information between spectral features. This results in inadequate utilization of spectral information and artifacts after upsampling. To address this issue, we propose ESSAformer, an ESSA attention-embedded Transformer network for single-HSI-SR with an iterative refining structure. Specifically, we first introduce a robust and spectral-friendly similarity metric, \ie, the spectral correlation coefficient of the spectrum (SCC), to replace the original attention matrix and incorporates inductive biases into the model to facilitate training. Built upon it, we further utilize the kernelizable attention technique with theoretical support to form a novel efficient SCC-kernel-based self-attention (ESSA) and reduce attention computation to linear complexity. ESSA enlarges the receptive field for features after upsampling without bringing much computation and allows the model to effectively utilize spatial-spectral information from different scales, resulting in the generation of more natural high-resolution images. Without the need for pretraining on large-scale datasets, our experiments demonstrate ESSA's effectiveness in both visual quality and quantitative results.
Attention-guided Multi-step Fusion: A Hierarchical Fusion Network for Multimodal Recommendation
Apr 24, 2023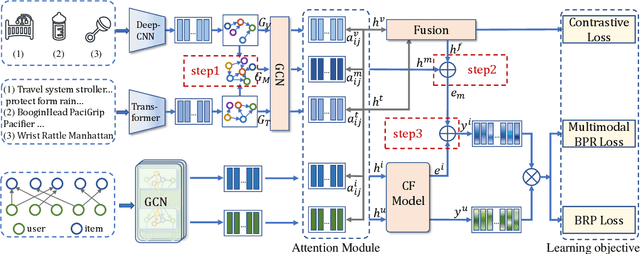
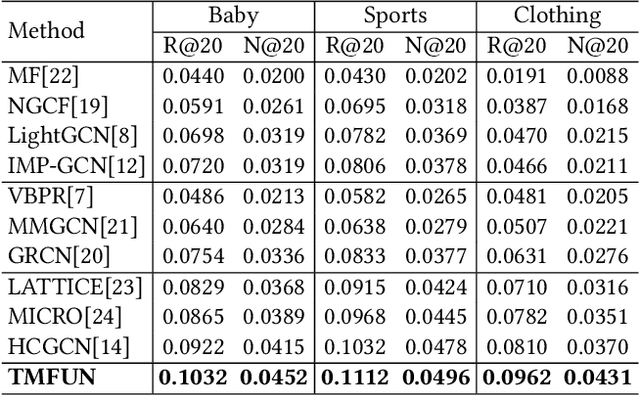
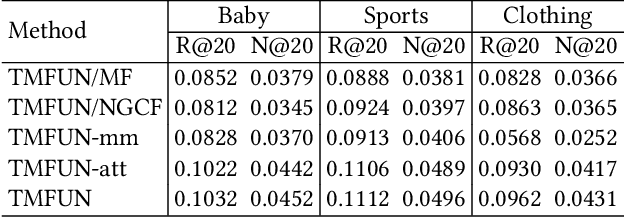
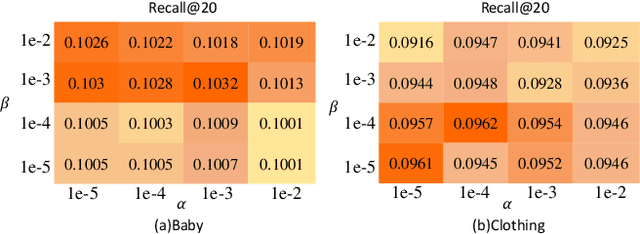
The main idea of multimodal recommendation is the rational utilization of the item's multimodal information to improve the recommendation performance. Previous works directly integrate item multimodal features with item ID embeddings, ignoring the inherent semantic relations contained in the multimodal features. In this paper, we propose a novel and effective aTtention-guided Multi-step FUsion Network for multimodal recommendation, named TMFUN. Specifically, our model first constructs modality feature graph and item feature graph to model the latent item-item semantic structures. Then, we use the attention module to identify inherent connections between user-item interaction data and multimodal data, evaluate the impact of multimodal data on different interactions, and achieve early-step fusion of item features. Furthermore, our model optimizes item representation through the attention-guided multi-step fusion strategy and contrastive learning to improve recommendation performance. The extensive experiments on three real-world datasets show that our model has superior performance compared to the state-of-the-art models.