 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Sun
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024
This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
THQA: A Perceptual Quality Assessment Database for Talking Heads
Apr 13, 2024In the realm of media technology, digital humans have gained prominence due to rapid advancements in computer technology. However, the manual modeling and control required for the majority of digital humans pose significant obstacles to efficient development. The speech-driven methods offer a novel avenue for manipulating the mouth shape and expressions of digital humans. Despite the proliferation of driving methods, the quality of many generated talking head (TH) videos remains a concern, impacting user visual experiences. To tackle this issue, this paper introduces the Talking Head Quality Assessment (THQA) database, featuring 800 TH videos generated through 8 diverse speech-driven methods. Extensive experiments affirm the THQA database's richness in character and speech features. Subsequent subjective quality assessment experiments analyze correlations between scoring results and speech-driven methods, ages, and genders. In addition, experimental results show that mainstream image and video quality assessment methods have limitations for the THQA database, underscoring the imperative for further research to enhance TH video quality assessment. The THQA database is publicly accessible at https://github.com/zyj-2000/THQA.
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.
A resource-constrained stochastic scheduling algorithm for homeless street outreach and gleaning edible food
Mar 15, 2024


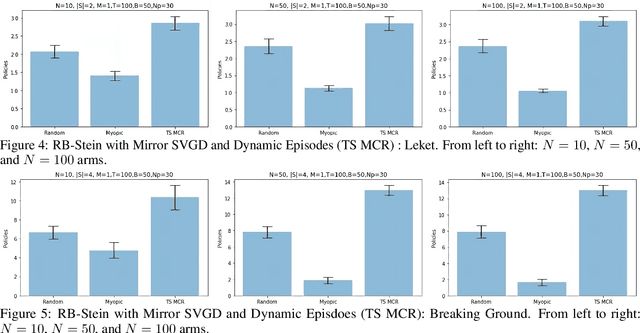
We developed a common algorithmic solution addressing the problem of resource-constrained outreach encountered by social change organizations with different missions and operations: Breaking Ground -- an organization that helps individuals experiencing homelessness in New York transition to permanent housing and Leket -- the national food bank of Israel that rescues food from farms and elsewhere to feed the hungry. Specifically, we developed an estimation and optimization approach for partially-observed episodic restless bandits under $k$-step transitions. The results show that our Thompson sampling with Markov chain recovery (via Stein variational gradient descent) algorithm significantly outperforms baselines for the problems of both organizations. We carried out this work in a prospective manner with the express goal of devising a flexible-enough but also useful-enough solution that can help overcome a lack of sustainable impact in data science for social good.
API Pack: A Massive Multilingual Dataset for API Call Generation
Feb 16, 2024We introduce API Pack, a multilingual dataset featuring over one million instruction-API call pairs aimed at advancing large language models' API call generation capabilities. Through experiments, we demonstrate API Pack's efficacy in enhancing models for this specialized task while maintaining their overall proficiency at general coding. Fine-tuning CodeLlama-13B on just 20,000 Python instances yields over 10% and 5% higher accuracy than GPT-3.5 and GPT-4 respectively in generating unseen API calls. Scaling to 100k examples improves generalization to new APIs not seen during training. In addition, cross-lingual API call generation is achieved without needing extensive data per language. The dataset, fine-tuned models, and overall code base are publicly available at https://github.com/zguo0525/API-Pack.
PresAIse, A Prescriptive AI Solution for Enterprises
Feb 13, 2024Prescriptive AI represents a transformative shift in decision-making, offering causal insights and actionable recommendations. Despite its huge potential, enterprise adoption often faces several challenges. The first challenge is caused by the limitations of observational data for accurate causal inference which is typically a prerequisite for good decision-making. The second pertains to the interpretability of recommendations, which is crucial for enterprise decision-making settings. The third challenge is the silos between data scientists and business users, hindering effective collaboration. This paper outlines an initiative from IBM Research, aiming to address some of these challenges by offering a suite of prescriptive AI solutions. Leveraging insights from various research papers, the solution suite includes scalable causal inference methods, interpretable decision-making approaches, and the integration of large language models (LLMs) to bridge communication gaps via a conversation agent. A proof-of-concept, PresAIse, demonstrates the solutions' potential by enabling non-ML experts to interact with prescriptive AI models via a natural language interface, democratizing advanced analytics for strategic decision-making.
Perceptual Video Quality Assessment: A Survey
Feb 05, 2024Perceptual video quality assessment plays a vital role in the field of video processing due to the existence of quality degradations introduced in various stages of video signal acquisition, compression, transmission and display. With the advancement of internet communication and cloud service technology, video content and traffic are growing exponentially, which further emphasizes the requirement for accurate and rapid assessment of video quality. Therefore, numerous subjective and objective video quality assessment studies have been conducted over the past two decades for both generic videos and specific videos such as streaming, user-generated content (UGC), 3D, virtual and augmented reality (VR and AR), high frame rate (HFR), audio-visual, etc. This survey provides an up-to-date and comprehensive review of these video quality assessment studies. Specifically, we first review the subjective video quality assessment methodologies and databases, which are necessary for validating the performance of video quality metrics. Second, the objective video quality assessment algorithms for general purposes are surveyed and concluded according to the methodologies utilized in the quality measures. Third, we overview the objective video quality assessment measures for specific applications and emerging topics. Finally, the performances of the state-of-the-art video quality assessment measures are compared and analyzed. This survey provides a systematic overview of both classical works and recent progresses in the realm of video quality assessment, which can help other researchers quickly access the field and conduct relevant research.
Q-Boost: On Visual Quality Assessment Ability of Low-level Multi-Modality Foundation Models
Dec 23, 2023Recent advancements in Multi-modality Large Language Models (MLLMs) have demonstrated remarkable capabilities in complex high-level vision tasks. However, the exploration of MLLM potential in visual quality assessment, a vital aspect of low-level vision, remains limited. To address this gap, we introduce Q-Boost, a novel strategy designed to enhance low-level MLLMs in image quality assessment (IQA) and video quality assessment (VQA) tasks, which is structured around two pivotal components: 1) Triadic-Tone Integration: Ordinary prompt design simply oscillates between the binary extremes of $positive$ and $negative$. Q-Boost innovates by incorporating a `middle ground' approach through $neutral$ prompts, allowing for a more balanced and detailed assessment. 2) Multi-Prompt Ensemble: Multiple quality-centric prompts are used to mitigate bias and acquire more accurate evaluation. The experimental results show that the low-level MLLMs exhibit outstanding zeros-shot performance on the IQA/VQA tasks equipped with the Q-Boost strategy.
Exploring the Naturalness of AI-Generated Images
Dec 14, 2023The proliferation of Artificial Intelligence-Generated Images (AGIs) has greatly expanded the Image Naturalness Assessment (INA) problem. Different from early definitions that mainly focus on tone-mapped images with limited distortions (e.g., exposure, contrast, and color reproduction), INA on AI-generated images is especially challenging as it has more diverse contents and could be affected by factors from multiple perspectives, including low-level technical distortions and high-level rationality distortions. In this paper, we take the first step to benchmark and assess the visual naturalness of AI-generated images. First, we construct the AI-Generated Image Naturalness (AGIN) database by conducting a large-scale subjective study to collect human opinions on the overall naturalness as well as perceptions from technical and rationality perspectives. AGIN verifies that naturalness is universally and disparately affected by both technical and rationality distortions. Second, we propose the Joint Objective Image Naturalness evaluaTor (JOINT), to automatically learn the naturalness of AGIs that aligns human ratings. Specifically, JOINT imitates human reasoning in naturalness evaluation by jointly learning both technical and rationality perspectives. Experimental results show our proposed JOINT significantly surpasses baselines for providing more subjectively consistent results on naturalness assessment. Our database and code will be released in https://github.com/zijianchen98/AGIN.
FS-BAND: A Frequency-Sensitive Banding Detector
Nov 30, 2023Banding artifact, as known as staircase-like contour, is a common quality annoyance that happens in compression, transmission, etc. scenarios, which largely affects the user's quality of experience (QoE). The banding distortion typically appears as relatively small pixel-wise variations in smooth backgrounds, which is difficult to analyze in the spatial domain but easily reflected in the frequency domain. In this paper, we thereby study the banding artifact from the frequency aspect and propose a no-reference banding detection model to capture and evaluate banding artifacts, called the Frequency-Sensitive BANding Detector (FS-BAND). The proposed detector is able to generate a pixel-wise banding map with a perception correlated quality score. Experimental results show that the proposed FS-BAND method outperforms state-of-the-art image quality assessment (IQA) approaches with higher accuracy in banding classification task.