 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTao Sun
A Survey of Reasoning for Substitution Relationships: Definitions, Methods, and Directions
Apr 09, 2024
Substitute relationships are fundamental to people's daily lives across various domains. This study aims to comprehend and predict substitute relationships among products in diverse fields, extensively analyzing the application of machine learning algorithms, natural language processing, and other technologies. By comparing model methodologies across different domains, such as defining substitutes, representing and learning substitute relationships, and substitute reasoning, this study offers a methodological foundation for delving deeper into substitute relationships. Through ongoing research and innovation, we can further refine the personalization and accuracy of substitute recommendation systems, thus advancing the development and application of this field.
Accelerating Federated Learning by Selecting Beneficial Herd of Local Gradients
Mar 25, 2024Federated Learning (FL) is a distributed machine learning framework in communication network systems. However, the systems' Non-Independent and Identically Distributed (Non-IID) data negatively affect the convergence efficiency of the global model, since only a subset of these data samples are beneficial for model convergence. In pursuit of this subset, a reliable approach involves determining a measure of validity to rank the samples within the dataset. In this paper, We propose the BHerd strategy which selects a beneficial herd of local gradients to accelerate the convergence of the FL model. Specifically, we map the distribution of the local dataset to the local gradients and use the Herding strategy to obtain a permutation of the set of gradients, where the more advanced gradients in the permutation are closer to the average of the set of gradients. These top portion of the gradients will be selected and sent to the server for global aggregation. We conduct experiments on different datasets, models and scenarios by building a prototype system, and experimental results demonstrate that our BHerd strategy is effective in selecting beneficial local gradients to mitigate the effects brought by the Non-IID dataset, thus accelerating model convergence.
RJUA-MedDQA: A Multimodal Benchmark for Medical Document Question Answering and Clinical Reasoning
Feb 19, 2024Recent advancements in Large Language Models (LLMs) and Large Multi-modal Models (LMMs) have shown potential in various medical applications, such as Intelligent Medical Diagnosis. Although impressive results have been achieved, we find that existing benchmarks do not reflect the complexity of real medical reports and specialized in-depth reasoning capabilities. In this work, we introduced RJUA-MedDQA, a comprehensive benchmark in the field of medical specialization, which poses several challenges: comprehensively interpreting imgage content across diverse challenging layouts, possessing numerical reasoning ability to identify abnormal indicators and demonstrating clinical reasoning ability to provide statements of disease diagnosis, status and advice based on medical contexts. We carefully design the data generation pipeline and proposed the Efficient Structural Restoration Annotation (ESRA) Method, aimed at restoring textual and tabular content in medical report images. This method substantially enhances annotation efficiency, doubling the productivity of each annotator, and yields a 26.8% improvement in accuracy. We conduct extensive evaluations, including few-shot assessments of 5 LMMs which are capable of solving Chinese medical QA tasks. To further investigate the limitations and potential of current LMMs, we conduct comparative experiments on a set of strong LLMs by using image-text generated by ESRA method. We report the performance of baselines and offer several observations: (1) The overall performance of existing LMMs is still limited; however LMMs more robust to low-quality and diverse-structured images compared to LLMs. (3) Reasoning across context and image content present significant challenges. We hope this benchmark helps the community make progress on these challenging tasks in multi-modal medical document understanding and facilitate its application in healthcare.
REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models
Feb 10, 2024The integration of multimodal Electronic Health Records (EHR) data has significantly improved clinical predictive capabilities. Leveraging clinical notes and multivariate time-series EHR, existing models often lack the medical context relevent to clinical tasks, prompting the incorporation of external knowledge, particularly from the knowledge graph (KG). Previous approaches with KG knowledge have primarily focused on structured knowledge extraction, neglecting unstructured data modalities and semantic high dimensional medical knowledge. In response, we propose REALM, a Retrieval-Augmented Generation (RAG) driven framework to enhance multimodal EHR representations that address these limitations. Firstly, we apply Large Language Model (LLM) to encode long context clinical notes and GRU model to encode time-series EHR data. Secondly, we prompt LLM to extract task-relevant medical entities and match entities in professionally labeled external knowledge graph (PrimeKG) with corresponding medical knowledge. By matching and aligning with clinical standards, our framework eliminates hallucinations and ensures consistency. Lastly, we propose an adaptive multimodal fusion network to integrate extracted knowledge with multimodal EHR data. Our extensive experiments on MIMIC-III mortality and readmission tasks showcase the superior performance of our REALM framework over baselines, emphasizing the effectiveness of each module. REALM framework contributes to refining the use of multimodal EHR data in healthcare and bridging the gap with nuanced medical context essential for informed clinical predictions.
OrchMoE: Efficient Multi-Adapter Learning with Task-Skill Synergy
Jan 19, 2024We advance the field of Parameter-Efficient Fine-Tuning (PEFT) with our novel multi-adapter method, OrchMoE, which capitalizes on modular skill architecture for enhanced forward transfer in neural networks. Unlike prior models that depend on explicit task identification inputs, OrchMoE automatically discerns task categories, streamlining the learning process. This is achieved through an integrated mechanism comprising an Automatic Task Classification module and a Task-Skill Allocation module, which collectively deduce task-specific classifications and tailor skill allocation matrices. Our extensive evaluations on the 'Super Natural Instructions' dataset, featuring 1,600 diverse instructional tasks, indicate that OrchMoE substantially outperforms comparable multi-adapter baselines in terms of both performance and sample utilization efficiency, all while operating within the same parameter constraints. These findings suggest that OrchMoE offers a significant leap forward in multi-task learning efficiency.
GACE: Learning Graph-Based Cross-Page Ads Embedding For Click-Through Rate Prediction
Jan 15, 2024Predicting click-through rate (CTR) is the core task of many ads online recommendation systems, which helps improve user experience and increase platform revenue. In this type of recommendation system, we often encounter two main problems: the joint usage of multi-page historical advertising data and the cold start of new ads. In this paper, we proposed GACE, a graph-based cross-page ads embedding generation method. It can warm up and generate the representation embedding of cold-start and existing ads across various pages. Specifically, we carefully build linkages and a weighted undirected graph model considering semantic and page-type attributes to guide the direction of feature fusion and generation. We designed a variational auto-encoding task as pre-training module and generated embedding representations for new and old ads based on this task. The results evaluated in the public dataset AliEC from RecBole and the real-world industry dataset from Alipay show that our GACE method is significantly superior to the SOTA method. In the online A/B test, the click-through rate on three real-world pages from Alipay has increased by 3.6%, 2.13%, and 3.02%, respectively. Especially in the cold-start task, the CTR increased by 9.96%, 7.51%, and 8.97%, respectively.
xCoT: Cross-lingual Instruction Tuning for Cross-lingual Chain-of-Thought Reasoning
Jan 13, 2024Chain-of-thought (CoT) has emerged as a powerful technique to elicit reasoning in large language models and improve a variety of downstream tasks. CoT mainly demonstrates excellent performance in English, but its usage in low-resource languages is constrained due to poor language generalization. To bridge the gap among different languages, we propose a cross-lingual instruction fine-tuning framework (xCOT) to transfer knowledge from high-resource languages to low-resource languages. Specifically, the multilingual instruction training data (xCOT-INSTRUCT) is created to encourage the semantic alignment of multiple languages. We introduce cross-lingual in-context few-shot learning (xICL)) to accelerate multilingual agreement in instruction tuning, where some fragments of source languages in examples are randomly substituted by their counterpart translations of target languages. During multilingual instruction tuning, we adopt the randomly online CoT strategy to enhance the multilingual reasoning ability of the large language model by first translating the query to another language and then answering in English. To further facilitate the language transfer, we leverage the high-resource CoT to supervise the training of low-resource languages with cross-lingual distillation. Experimental results on previous benchmarks demonstrate the superior performance of xCoT in reducing the gap among different languages, highlighting its potential to reduce the cross-lingual gap.
Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning
Dec 06, 2023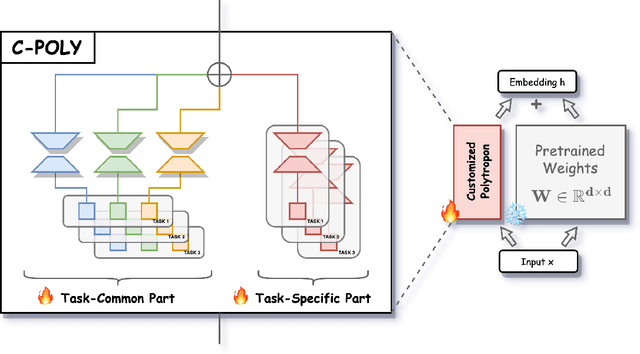
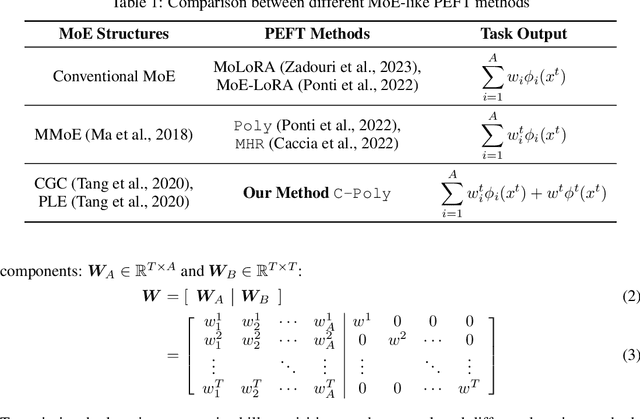
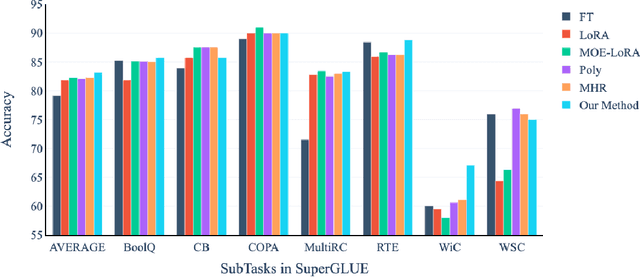
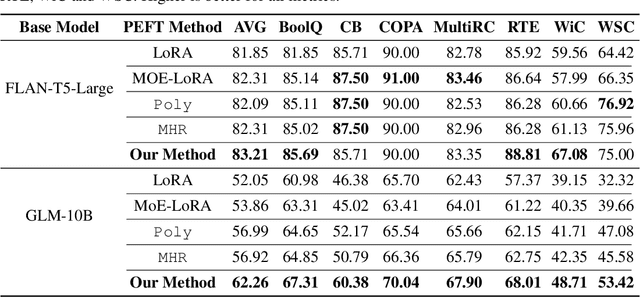
Modular and composable transfer learning is an emerging direction in the field of Parameter Efficient Fine-Tuning, as it enables neural networks to better organize various aspects of knowledge, leading to improved cross-task generalization. In this paper, we introduce a novel approach Customized Polytropon C-Poly that combines task-common skills and task-specific skills, while the skill parameters being highly parameterized using low-rank techniques. Each task is associated with a customizable number of exclusive specialized skills and also benefits from skills shared with peer tasks. A skill assignment matrix is jointly learned. To evaluate our approach, we conducted extensive experiments on the Super-NaturalInstructions and the SuperGLUE benchmarks. Our findings demonstrate that C-Poly outperforms fully-shared, task-specific, and skill-indistinguishable baselines, significantly enhancing the sample efficiency in multi-task learning scenarios.
Nothing Stands Still: A Spatiotemporal Benchmark on 3D Point Cloud Registration Under Large Geometric and Temporal Change
Nov 15, 2023
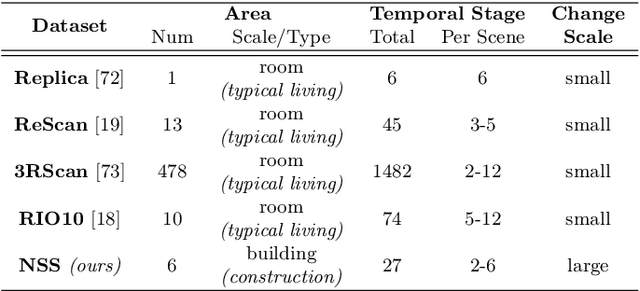
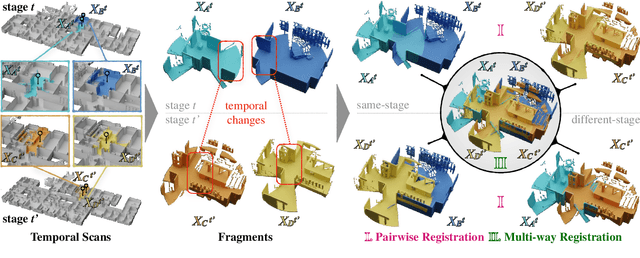
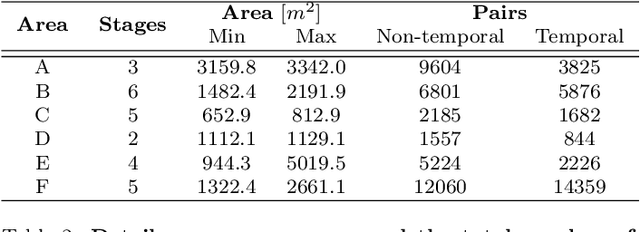
Building 3D geometric maps of man-made spaces is a well-established and active field that is fundamental to computer vision and robotics. However, considering the evolving nature of built environments, it is essential to question the capabilities of current mapping efforts in handling temporal changes. In addition, spatiotemporal mapping holds significant potential for achieving sustainability and circularity goals. Existing mapping approaches focus on small changes, such as object relocation or self-driving car operation; in all cases where the main structure of the scene remains fixed. Consequently, these approaches fail to address more radical changes in the structure of the built environment, such as geometry and topology. To this end, we introduce the Nothing Stands Still (NSS) benchmark, which focuses on the spatiotemporal registration of 3D scenes undergoing large spatial and temporal change, ultimately creating one coherent spatiotemporal map. Specifically, the benchmark involves registering two or more partial 3D point clouds (fragments) from the same scene but captured from different spatiotemporal views. In addition to the standard pairwise registration, we assess the multi-way registration of multiple fragments that belong to any temporal stage. As part of NSS, we introduce a dataset of 3D point clouds recurrently captured in large-scale building indoor environments that are under construction or renovation. The NSS benchmark presents three scenarios of increasing difficulty, to quantify the generalization ability of point cloud registration methods over space (within one building and across buildings) and time. We conduct extensive evaluations of state-of-the-art methods on NSS. The results demonstrate the necessity for novel methods specifically designed to handle large spatiotemporal changes. The homepage of our benchmark is at http://nothing-stands-still.com.
Rethinking SIGN Training: Provable Nonconvex Acceleration without First- and Second-Order Gradient Lipschitz
Oct 23, 2023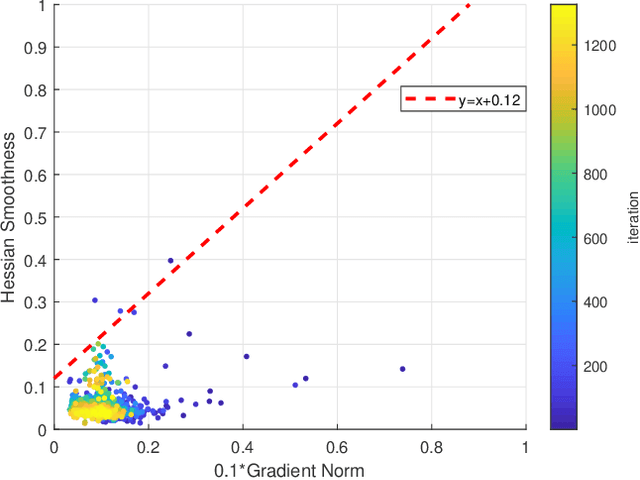
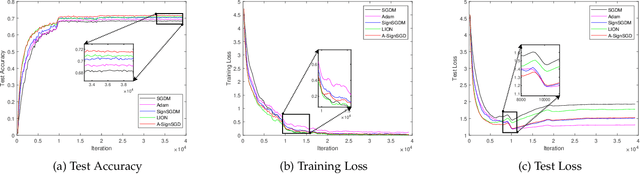
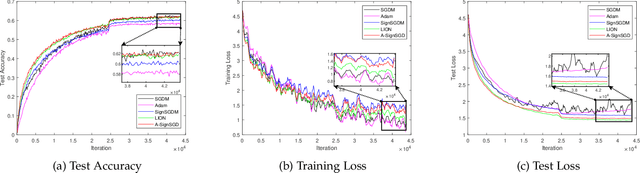
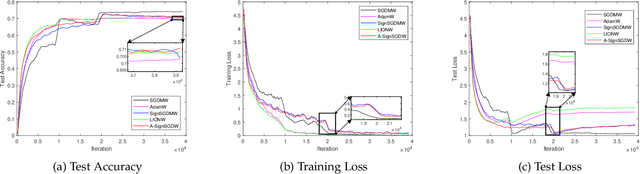
Sign-based stochastic methods have gained attention due to their ability to achieve robust performance despite using only the sign information for parameter updates. However, the current convergence analysis of sign-based methods relies on the strong assumptions of first-order gradient Lipschitz and second-order gradient Lipschitz, which may not hold in practical tasks like deep neural network training that involve high non-smoothness. In this paper, we revisit sign-based methods and analyze their convergence under more realistic assumptions of first- and second-order smoothness. We first establish the convergence of the sign-based method under weak first-order Lipschitz. Motivated by the weak first-order Lipschitz, we propose a relaxed second-order condition that still allows for nonconvex acceleration in sign-based methods. Based on our theoretical results, we gain insights into the computational advantages of the recently developed LION algorithm. In distributed settings, we prove that this nonconvex acceleration persists with linear speedup in the number of nodes, when utilizing fast communication compression gossip protocols. The novelty of our theoretical results lies in that they are derived under much weaker assumptions, thereby expanding the provable applicability of sign-based algorithms to a wider range of problems.