 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoge Deng
Accelerating Federated Learning by Selecting Beneficial Herd of Local Gradients
Mar 25, 2024
Federated Learning (FL) is a distributed machine learning framework in communication network systems. However, the systems' Non-Independent and Identically Distributed (Non-IID) data negatively affect the convergence efficiency of the global model, since only a subset of these data samples are beneficial for model convergence. In pursuit of this subset, a reliable approach involves determining a measure of validity to rank the samples within the dataset. In this paper, We propose the BHerd strategy which selects a beneficial herd of local gradients to accelerate the convergence of the FL model. Specifically, we map the distribution of the local dataset to the local gradients and use the Herding strategy to obtain a permutation of the set of gradients, where the more advanced gradients in the permutation are closer to the average of the set of gradients. These top portion of the gradients will be selected and sent to the server for global aggregation. We conduct experiments on different datasets, models and scenarios by building a prototype system, and experimental results demonstrate that our BHerd strategy is effective in selecting beneficial local gradients to mitigate the effects brought by the Non-IID dataset, thus accelerating model convergence.
Towards Understanding the Generalizability of Delayed Stochastic Gradient Descent
Aug 18, 2023



Stochastic gradient descent (SGD) performed in an asynchronous manner plays a crucial role in training large-scale machine learning models. However, the generalization performance of asynchronous delayed SGD, which is an essential metric for assessing machine learning algorithms, has rarely been explored. Existing generalization error bounds are rather pessimistic and cannot reveal the correlation between asynchronous delays and generalization. In this paper, we investigate sharper generalization error bound for SGD with asynchronous delay $\tau$. Leveraging the generating function analysis tool, we first establish the average stability of the delayed gradient algorithm. Based on this algorithmic stability, we provide upper bounds on the generalization error of $\tilde{\mathcal{O}}(\frac{T-\tau}{n\tau})$ and $\tilde{\mathcal{O}}(\frac{1}{n})$ for quadratic convex and strongly convex problems, respectively, where $T$ refers to the iteration number and $n$ is the amount of training data. Our theoretical results indicate that asynchronous delays reduce the generalization error of the delayed SGD algorithm. Analogous analysis can be generalized to the random delay setting, and the experimental results validate our theoretical findings.
S2 Reducer: High-Performance Sparse Communication to Accelerate Distributed Deep Learning
Oct 05, 2021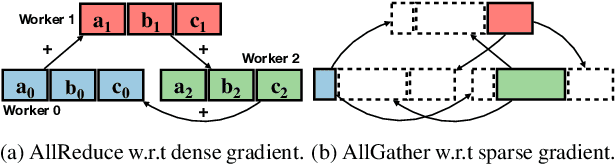

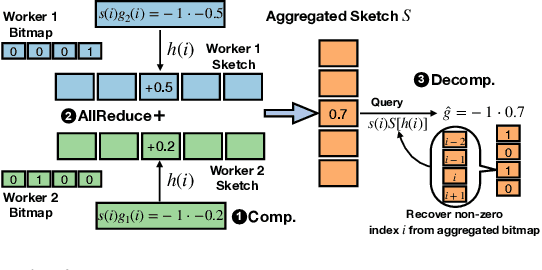

Distributed stochastic gradient descent (SGD) approach has been widely used in large-scale deep learning, and the gradient collective method is vital to ensure the training scalability of the distributed deep learning system. Collective communication such as AllReduce has been widely adopted for the distributed SGD process to reduce the communication time. However, AllReduce incurs large bandwidth resources while most gradients are sparse in many cases since many gradient values are zeros and should be efficiently compressed for bandwidth saving. To reduce the sparse gradient communication overhead, we propose Sparse-Sketch Reducer (S2 Reducer), a novel sketch-based sparse gradient aggregation method with convergence guarantees. S2 Reducer reduces the communication cost by only compressing the non-zero gradients with count-sketch and bitmap, and enables the efficient AllReduce operators for parallel SGD training. We perform extensive evaluation against four state-of-the-art methods over five training models. Our results show that S2 Reducer converges to the same accuracy, reduces 81\% sparse communication overhead, and achieves 1.8$ \times $ speedup compared to state-of-the-art approaches.