 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePing Luo
Adapting LLaMA Decoder to Vision Transformer
Apr 13, 2024
This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
DiffAgent: Fast and Accurate Text-to-Image API Selection with Large Language Model
Mar 31, 2024Text-to-image (T2I) generative models have attracted significant attention and found extensive applications within and beyond academic research. For example, the Civitai community, a platform for T2I innovation, currently hosts an impressive array of 74,492 distinct models. However, this diversity presents a formidable challenge in selecting the most appropriate model and parameters, a process that typically requires numerous trials. Drawing inspiration from the tool usage research of large language models (LLMs), we introduce DiffAgent, an LLM agent designed to screen the accurate selection in seconds via API calls. DiffAgent leverages a novel two-stage training framework, SFTA, enabling it to accurately align T2I API responses with user input in accordance with human preferences. To train and evaluate DiffAgent's capabilities, we present DABench, a comprehensive dataset encompassing an extensive range of T2I APIs from the community. Our evaluations reveal that DiffAgent not only excels in identifying the appropriate T2I API but also underscores the effectiveness of the SFTA training framework. Codes are available at https://github.com/OpenGVLab/DiffAgent.
FlashFace: Human Image Personalization with High-fidelity Identity Preservation
Mar 25, 2024This work presents FlashFace, a practical tool with which users can easily personalize their own photos on the fly by providing one or a few reference face images and a text prompt. Our approach is distinguishable from existing human photo customization methods by higher-fidelity identity preservation and better instruction following, benefiting from two subtle designs. First, we encode the face identity into a series of feature maps instead of one image token as in prior arts, allowing the model to retain more details of the reference faces (e.g., scars, tattoos, and face shape ). Second, we introduce a disentangled integration strategy to balance the text and image guidance during the text-to-image generation process, alleviating the conflict between the reference faces and the text prompts (e.g., personalizing an adult into a "child" or an "elder"). Extensive experimental results demonstrate the effectiveness of our method on various applications, including human image personalization, face swapping under language prompts, making virtual characters into real people, etc. Project Page: https://jshilong.github.io/flashface-page.
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Mar 25, 2024End-to-end driving has made significant progress in recent years, demonstrating benefits such as system simplicity and competitive driving performance under both open-loop and closed-loop settings. Nevertheless, the lack of interpretability and controllability in its driving decisions hinders real-world deployment for end-to-end driving systems. In this paper, we collect a comprehensive end-to-end driving dataset named DriveCoT, leveraging the CARLA simulator. It contains sensor data, control decisions, and chain-of-thought labels to indicate the reasoning process. We utilize the challenging driving scenarios from the CARLA leaderboard 2.0, which involve high-speed driving and lane-changing, and propose a rule-based expert policy to control the vehicle and generate ground truth labels for its reasoning process across different driving aspects and the final decisions. This dataset can serve as an open-loop end-to-end driving benchmark, enabling the evaluation of accuracy in various chain-of-thought aspects and the final decision. In addition, we propose a baseline model called DriveCoT-Agent, trained on our dataset, to generate chain-of-thought predictions and final decisions. The trained model exhibits strong performance in both open-loop and closed-loop evaluations, demonstrating the effectiveness of our proposed dataset.
Accelerating Federated Learning by Selecting Beneficial Herd of Local Gradients
Mar 25, 2024Federated Learning (FL) is a distributed machine learning framework in communication network systems. However, the systems' Non-Independent and Identically Distributed (Non-IID) data negatively affect the convergence efficiency of the global model, since only a subset of these data samples are beneficial for model convergence. In pursuit of this subset, a reliable approach involves determining a measure of validity to rank the samples within the dataset. In this paper, We propose the BHerd strategy which selects a beneficial herd of local gradients to accelerate the convergence of the FL model. Specifically, we map the distribution of the local dataset to the local gradients and use the Herding strategy to obtain a permutation of the set of gradients, where the more advanced gradients in the permutation are closer to the average of the set of gradients. These top portion of the gradients will be selected and sent to the server for global aggregation. We conduct experiments on different datasets, models and scenarios by building a prototype system, and experimental results demonstrate that our BHerd strategy is effective in selecting beneficial local gradients to mitigate the effects brought by the Non-IID dataset, thus accelerating model convergence.
Zero-shot Generative Linguistic Steganography
Mar 16, 2024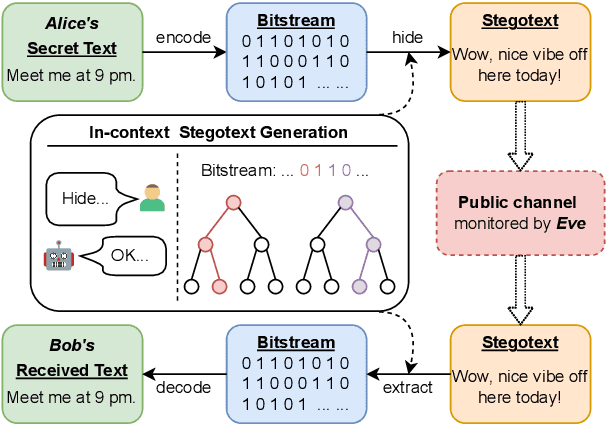
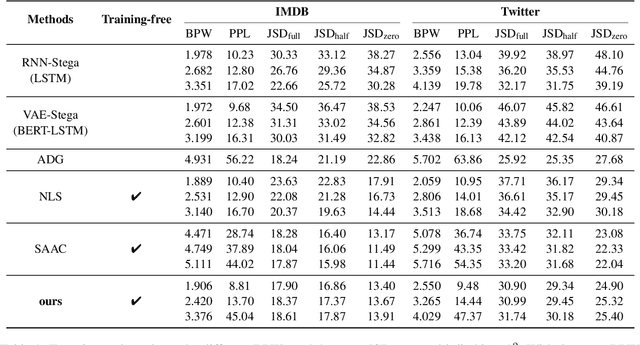
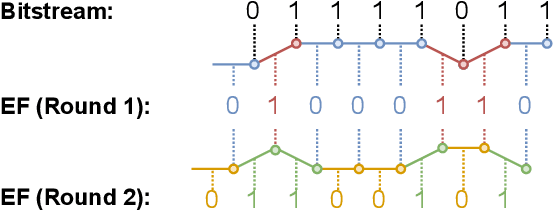
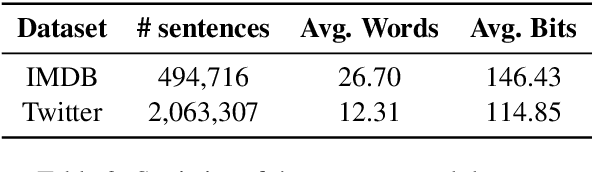
Generative linguistic steganography attempts to hide secret messages into covertext. Previous studies have generally focused on the statistical differences between the covertext and stegotext, however, ill-formed stegotext can readily be identified by humans. In this paper, we propose a novel zero-shot approach based on in-context learning for linguistic steganography to achieve better perceptual and statistical imperceptibility. We also design several new metrics and reproducible language evaluations to measure the imperceptibility of the stegotext. Our experimental results indicate that our method produces $1.926\times$ more innocent and intelligible stegotext than any other method.
Generalized Predictive Model for Autonomous Driving
Mar 14, 2024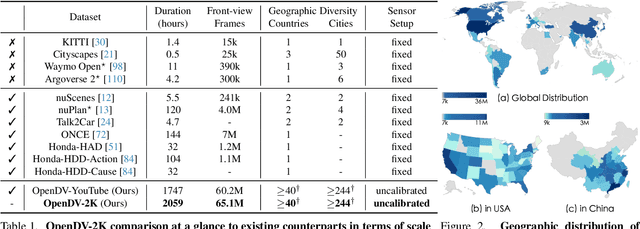
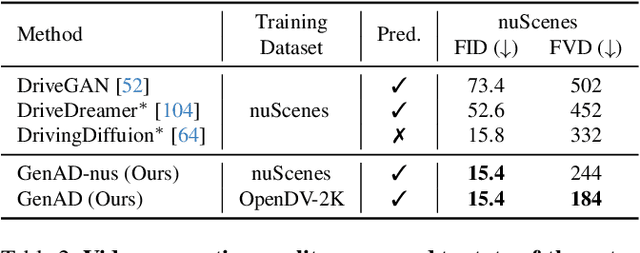
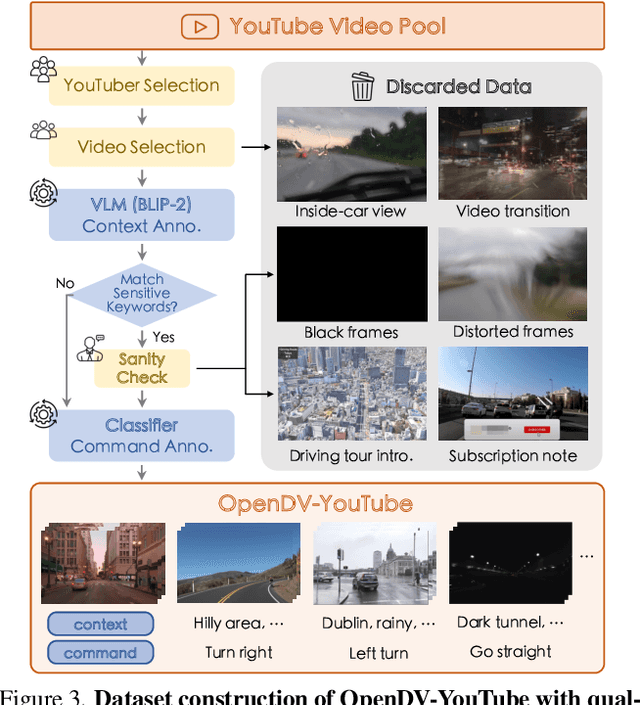
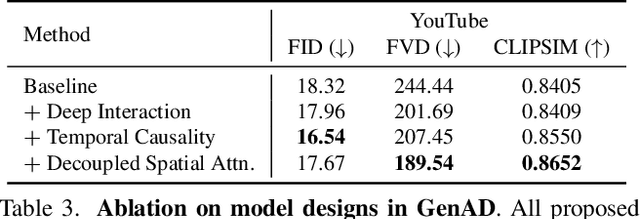
In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.
AVIBench: Towards Evaluating the Robustness of Large Vision-Language Model on Adversarial Visual-Instructions
Mar 14, 2024

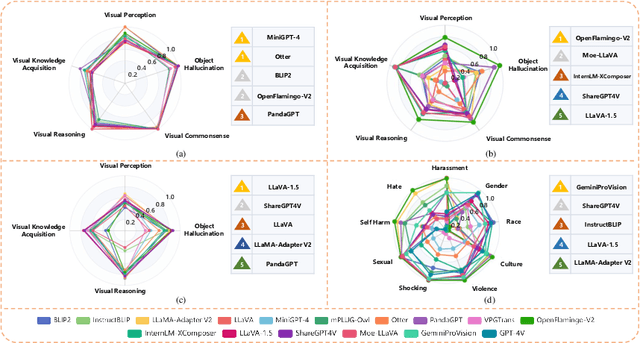
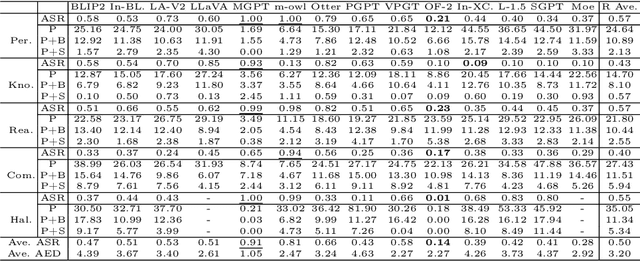
Large Vision-Language Models (LVLMs) have shown significant progress in well responding to visual-instructions from users. However, these instructions, encompassing images and text, are susceptible to both intentional and inadvertent attacks. Despite the critical importance of LVLMs' robustness against such threats, current research in this area remains limited. To bridge this gap, we introduce AVIBench, a framework designed to analyze the robustness of LVLMs when facing various adversarial visual-instructions (AVIs), including four types of image-based AVIs, ten types of text-based AVIs, and nine types of content bias AVIs (such as gender, violence, cultural, and racial biases, among others). We generate 260K AVIs encompassing five categories of multimodal capabilities (nine tasks) and content bias. We then conduct a comprehensive evaluation involving 14 open-source LVLMs to assess their performance. AVIBench also serves as a convenient tool for practitioners to evaluate the robustness of LVLMs against AVIs. Our findings and extensive experimental results shed light on the vulnerabilities of LVLMs, and highlight that inherent biases exist even in advanced closed-source LVLMs like GeminiProVision and GPT-4V. This underscores the importance of enhancing the robustness, security, and fairness of LVLMs. The source code and benchmark will be made publicly available.