 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiqi Fan
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024
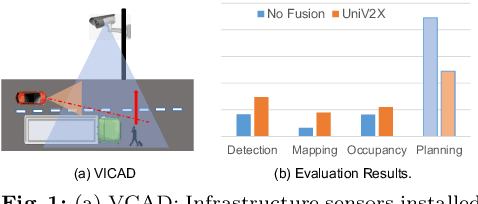
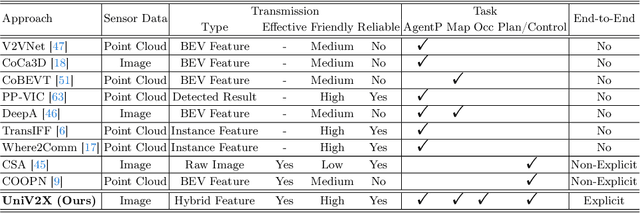
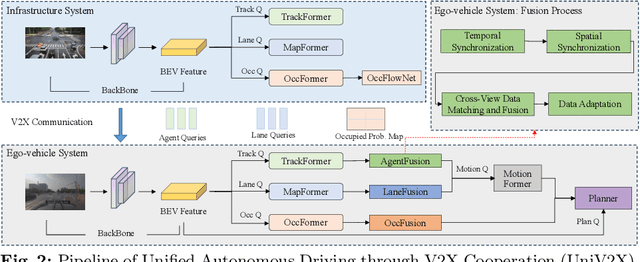

Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024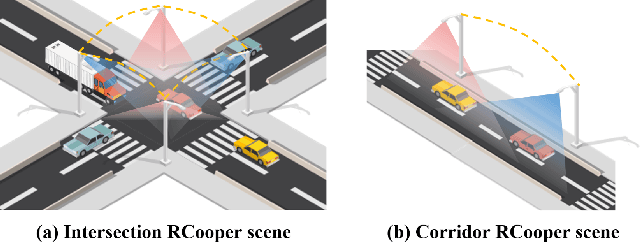
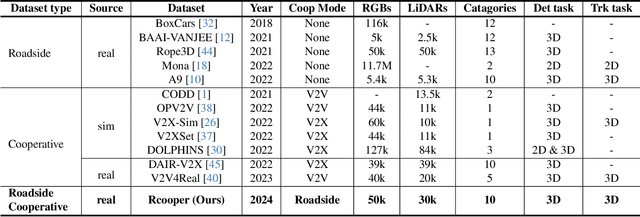
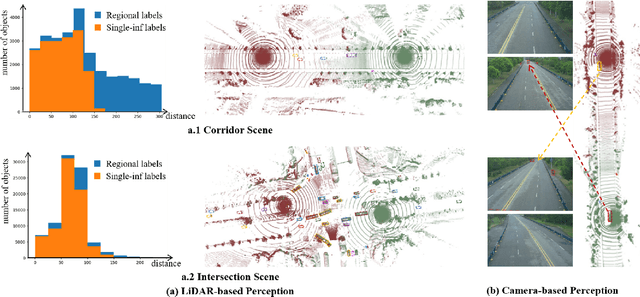

The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024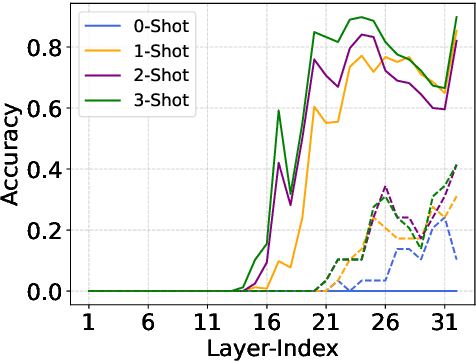
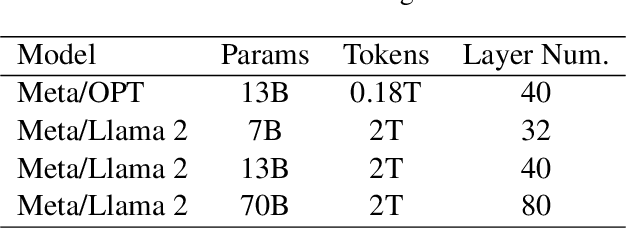
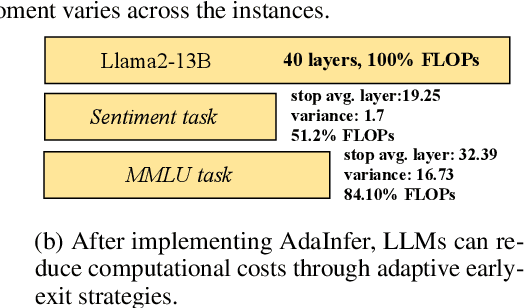

The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Feb 23, 2024In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
Learning Cooperative Trajectory Representations for Motion Forecasting
Nov 01, 2023Motion forecasting is an essential task for autonomous driving, and the effective information utilization from infrastructure and other vehicles can enhance motion forecasting capabilities. Existing research have primarily focused on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction information of traffic participants observed from cooperative devices. In this paper, we first propose the cooperative trajectory representations learning paradigm. Specifically, we present V2X-Graph, the first interpretable and end-to-end learning framework for cooperative motion forecasting. V2X-Graph employs an interpretable graph to fully leverage the cooperative motion and interaction contexts. Experimental results on the vehicle-to-infrastructure (V2I) motion forecasting dataset, V2X-Seq, demonstrate the effectiveness of V2X-Graph. To further evaluate on V2X scenario, we construct the first real-world vehicle-to-everything (V2X) motion forecasting dataset V2X-Traj, and the performance shows the advantage of our method. We hope both V2X-Graph and V2X-Traj can facilitate the further development of cooperative motion forecasting. Find project at https://github.com/AIR-THU/V2X-Graph, find data at https://github.com/AIR-THU/DAIR-V2X-Seq.
FLM-101B: An Open LLM and How to Train It with $100K Budget
Sep 17, 2023

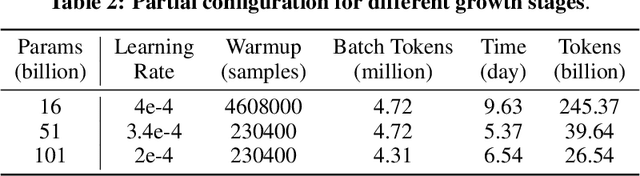
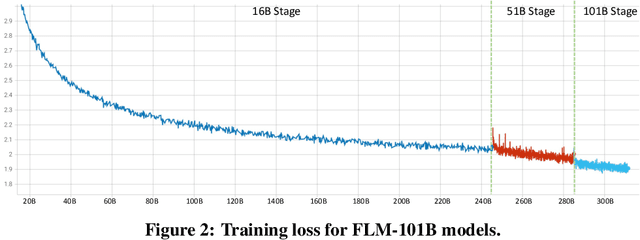
Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational cost, and (ii) fair and objective evaluations. In this paper, we report a solution to significantly reduce LLM training cost through a growth strategy. We demonstrate that a 101B-parameter LLM with 0.31T tokens can be trained with a budget of 100K US dollars. Inspired by IQ tests, we also consolidate an additional range of evaluations on top of existing evaluations that focus on knowledge-oriented abilities. These IQ evaluations include symbolic mapping, rule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model, named FLM-101B, trained with a budget of 100K US dollars, achieves performance comparable to powerful and well-known models, e.g., GPT-3 and GLM-130B, especially on the additional range of IQ evaluations. The checkpoint of FLM-101B is released at https://huggingface.co/CofeAI/FLM-101B.
QUEST: Query Stream for Vehicle-Infrastructure Cooperative Perception
Aug 03, 2023
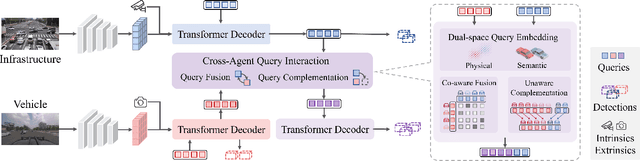
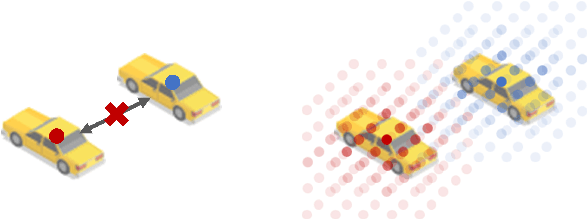
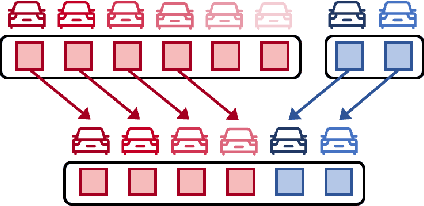
Cooperative perception can effectively enhance individual perception performance by providing additional viewpoint and expanding the sensing field. Existing cooperation paradigms are either interpretable (result cooperation) or flexible (feature cooperation). In this paper, we propose the concept of query cooperation to enable interpretable instance-level flexible feature interaction. To specifically explain the concept, we propose a cooperative perception framework, termed QUEST, which let query stream flow among agents. The cross-agent queries are interacted via fusion for co-aware instances and complementation for individual unaware instances. Taking camera-based vehicle-infrastructure perception as a typical practical application scene, the experimental results on the real-world dataset, DAIR-V2X-Seq, demonstrate the effectiveness of QUEST and further reveal the advantage of the query cooperation paradigm on transmission flexibility and robustness to packet dropout. We hope our work can further facilitate the cross-agent representation interaction for better cooperative perception in practice.
VIMI: Vehicle-Infrastructure Multi-view Intermediate Fusion for Camera-based 3D Object Detection
Mar 20, 2023
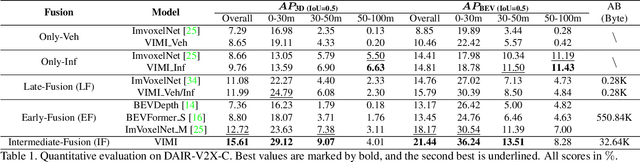
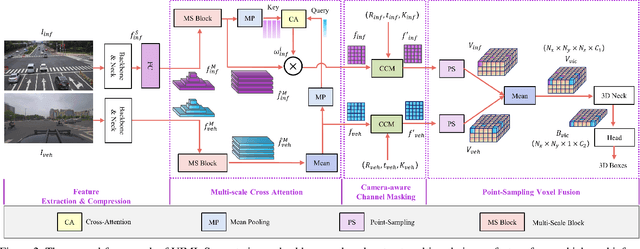
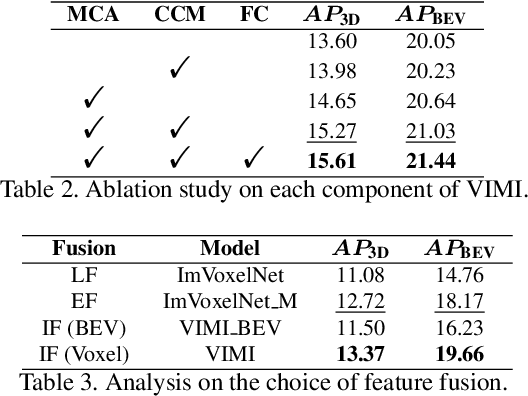
In autonomous driving, Vehicle-Infrastructure Cooperative 3D Object Detection (VIC3D) makes use of multi-view cameras from both vehicles and traffic infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Two major challenges prevail in VIC3D: 1) inherent calibration noise when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss when projecting 2D features into 3D space. To address these issues, We propose a novel 3D object detection framework, Vehicles-Infrastructure Multi-view Intermediate fusion (VIMI). First, to fully exploit the holistic perspectives from both vehicles and infrastructure, we propose a Multi-scale Cross Attention (MCA) module that fuses infrastructure and vehicle features on selective multi-scales to correct the calibration noise introduced by camera asynchrony. Then, we design a Camera-aware Channel Masking (CCM) module that uses camera parameters as priors to augment the fused features. We further introduce a Feature Compression (FC) module with channel and spatial compression blocks to reduce the size of transmitted features for enhanced efficiency. Experiments show that VIMI achieves 15.61% overall AP_3D and 21.44% AP_BEV on the new VIC3D dataset, DAIR-V2X-C, significantly outperforming state-of-the-art early fusion and late fusion methods with comparable transmission cost.
SpiderMesh: Spatial-aware Demand-guided Recursive Meshing for RGB-T Semantic Segmentation
Mar 15, 2023


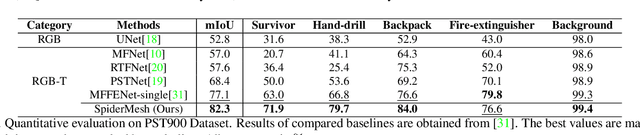
For semantic segmentation in urban scene understanding, RGB cameras alone often fail to capture a clear holistic topology, especially in challenging lighting conditions. Thermal signal is an informative additional channel that can bring to light the contour and fine-grained texture of blurred regions in low-quality RGB image. Aiming at RGB-T (thermal) segmentation, existing methods either use simple passive channel/spatial-wise fusion for cross-modal interaction, or rely on heavy labeling of ambiguous boundaries for fine-grained supervision. We propose a Spatial-aware Demand-guided Recursive Meshing (SpiderMesh) framework that: 1) proactively compensates inadequate contextual semantics in optically-impaired regions via a demand-guided target masking algorithm; 2) refines multimodal semantic features with recursive meshing to improve pixel-level semantic analysis performance. We further introduce an asymmetric data augmentation technique M-CutOut, and enable semi-supervised learning to fully utilize RGB-T labels only sparsely available in practical use. Extensive experiments on MFNet and PST900 datasets demonstrate that SpiderMesh achieves new state-of-the-art performance on standard RGB-T segmentation benchmarks.
Calibration-free BEV Representation for Infrastructure Perception
Mar 07, 2023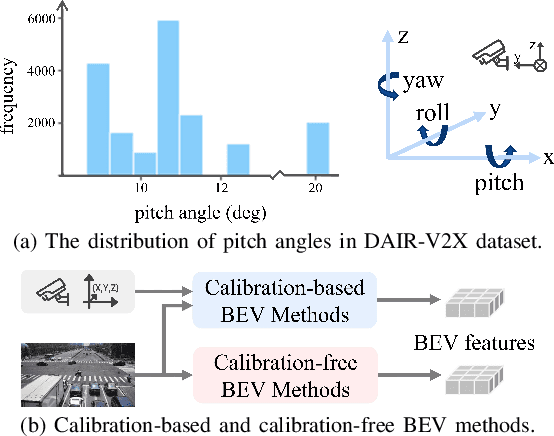
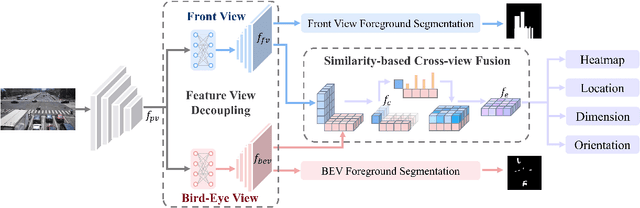
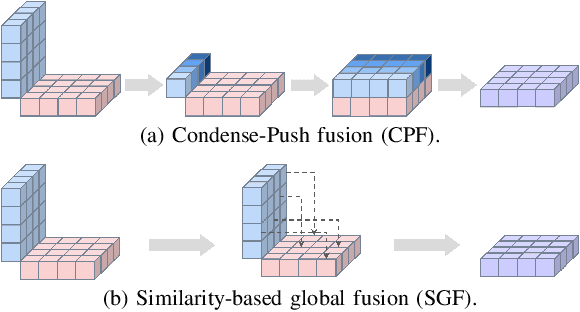

Effective BEV object detection on infrastructure can greatly improve traffic scenes understanding and vehicle-toinfrastructure (V2I) cooperative perception. However, cameras installed on infrastructure have various postures, and previous BEV detection methods rely on accurate calibration, which is difficult for practical applications due to inevitable natural factors (e.g., wind and snow). In this paper, we propose a Calibration-free BEV Representation (CBR) network, which achieves 3D detection based on BEV representation without calibration parameters and additional depth supervision. Specifically, we utilize two multi-layer perceptrons for decoupling the features from perspective view to front view and birdeye view under boxes-induced foreground supervision. Then, a cross-view feature fusion module matches features from orthogonal views according to similarity and conducts BEV feature enhancement with front view features. Experimental results on DAIR-V2X demonstrate that CBR achieves acceptable performance without any camera parameters and is naturally not affected by calibration noises. We hope CBR can serve as a baseline for future research addressing practical challenges of infrastructure perception.