 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuo Shang
DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level
Apr 09, 2024
Recommendation systems play a crucial role in various domains, suggesting items based on user behavior.However, the lack of transparency in presenting recommendations can lead to user confusion. In this paper, we introduce Data-level Recommendation Explanation (DRE), a non-intrusive explanation framework for black-box recommendation models.Different from existing methods, DRE does not require any intermediary representations of the recommendation model or latent alignment training, mitigating potential performance issues.We propose a data-level alignment method, leveraging large language models to reason relationships between user data and recommended items.Additionally, we address the challenge of enriching the details of the explanation by introducing target-aware user preference distillation, utilizing item reviews. Experimental results on benchmark datasets demonstrate the effectiveness of the DRE in providing accurate and user-centric explanations, enhancing user engagement with recommended item.
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
Apr 08, 2024Large language model agents have demonstrated remarkable advancements across various complex tasks. Recent works focus on optimizing the agent team or employing self-reflection to iteratively solve complex tasks. Since these agents are all based on the same LLM, only conducting self-evaluation or removing underperforming agents does not substantively enhance the capability of the agents. We argue that a comprehensive evaluation and accumulating experience from evaluation feedback is an effective approach to improving system performance. In this paper, we propose Reusable Experience Accumulation with 360{\deg} Assessment (360{\deg}REA), a hierarchical multi-agent framework inspired by corporate organizational practices. The framework employs a novel 360{\deg} performance assessment method for multi-perspective performance evaluation with fine-grained assessment. To enhance the capability of agents in addressing complex tasks, we introduce dual-level experience pool for agents to accumulate experience through fine-grained assessment. Extensive experiments on complex task datasets demonstrate the effectiveness of 360{\deg}REA.
"In Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
Mar 12, 2024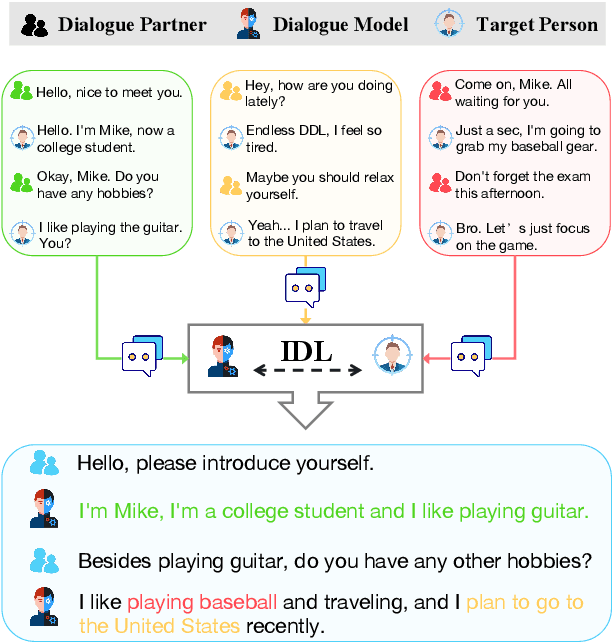
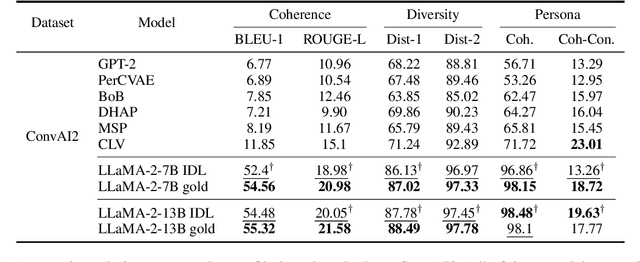
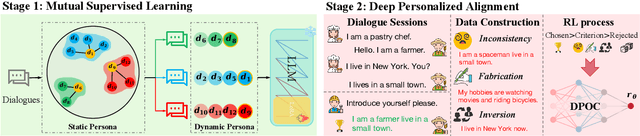
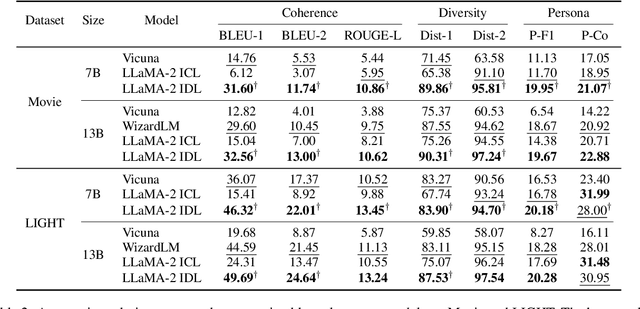
Personalized dialogue systems have gained significant attention in recent years for their ability to generate responses in alignment with different personas. However, most existing approaches rely on pre-defined personal profiles, which are not only time-consuming and labor-intensive to create but also lack flexibility. We propose In-Dialogue Learning (IDL), a fine-tuning framework that enhances the ability of pre-trained large language models to leverage dialogue history to characterize persona for completing personalized dialogue generation tasks without pre-defined profiles. Our experiments on three datasets demonstrate that IDL brings substantial improvements, with BLEU and ROUGE scores increasing by up to 200% and 247%, respectively. Additionally, the results of human evaluations further validate the efficacy of our proposed method.
Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering
Mar 08, 2024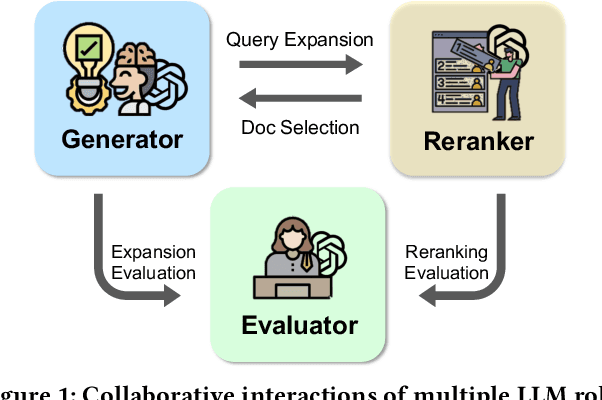
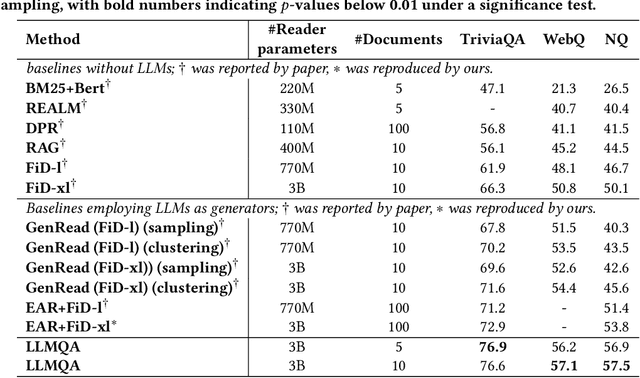
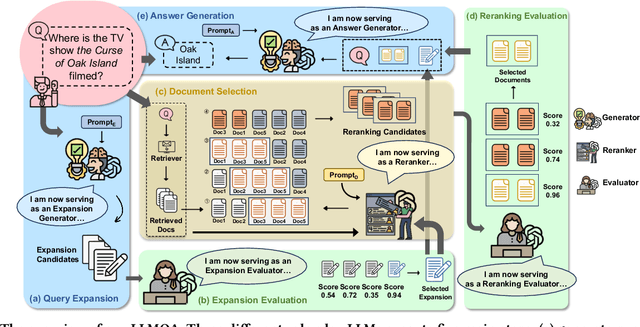

Open-domain question answering (ODQA) has emerged as a pivotal research spotlight in information systems. Existing methods follow two main paradigms to collect evidence: (1) The \textit{retrieve-then-read} paradigm retrieves pertinent documents from an external corpus; and (2) the \textit{generate-then-read} paradigm employs large language models (LLMs) to generate relevant documents. However, neither can fully address multifaceted requirements for evidence. To this end, we propose LLMQA, a generalized framework that formulates the ODQA process into three basic steps: query expansion, document selection, and answer generation, combining the superiority of both retrieval-based and generation-based evidence. Since LLMs exhibit their excellent capabilities to accomplish various tasks, we instruct LLMs to play multiple roles as generators, rerankers, and evaluators within our framework, integrating them to collaborate in the ODQA process. Furthermore, we introduce a novel prompt optimization algorithm to refine role-playing prompts and steer LLMs to produce higher-quality evidence and answers. Extensive experimental results on widely used benchmarks (NQ, WebQ, and TriviaQA) demonstrate that LLMQA achieves the best performance in terms of both answer accuracy and evidence quality, showcasing its potential for advancing ODQA research and applications.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024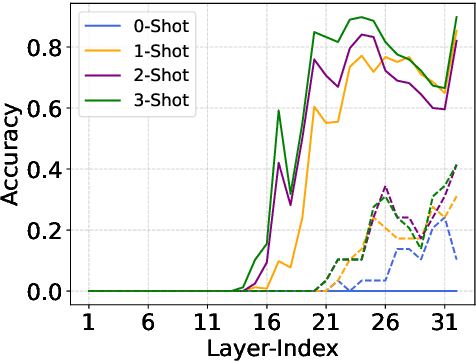
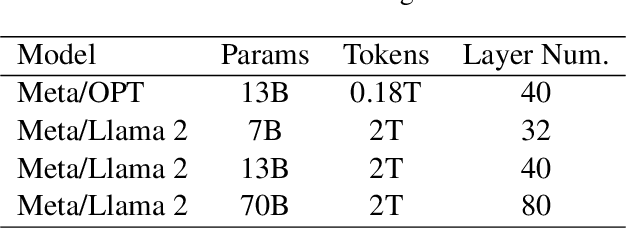
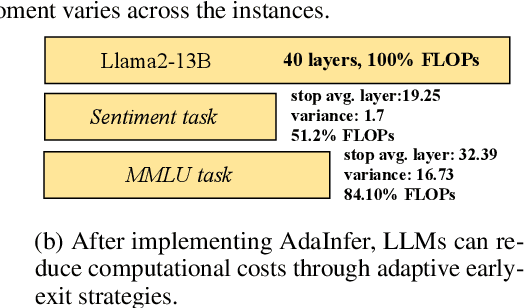

The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
Explainable Session-based Recommendation via Path Reasoning
Feb 28, 2024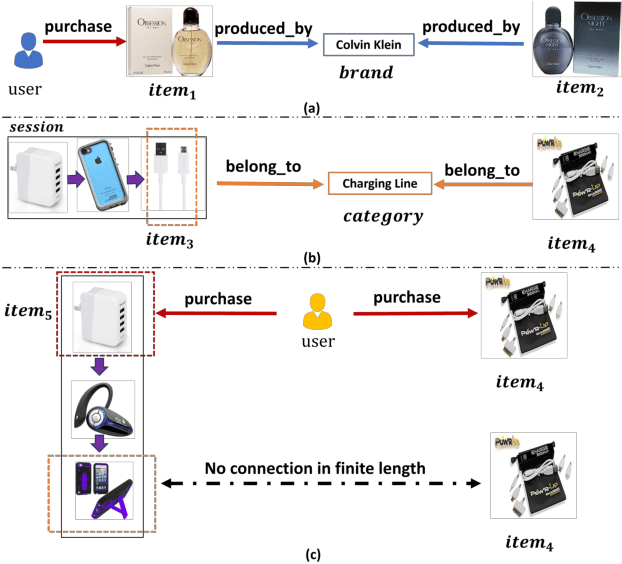
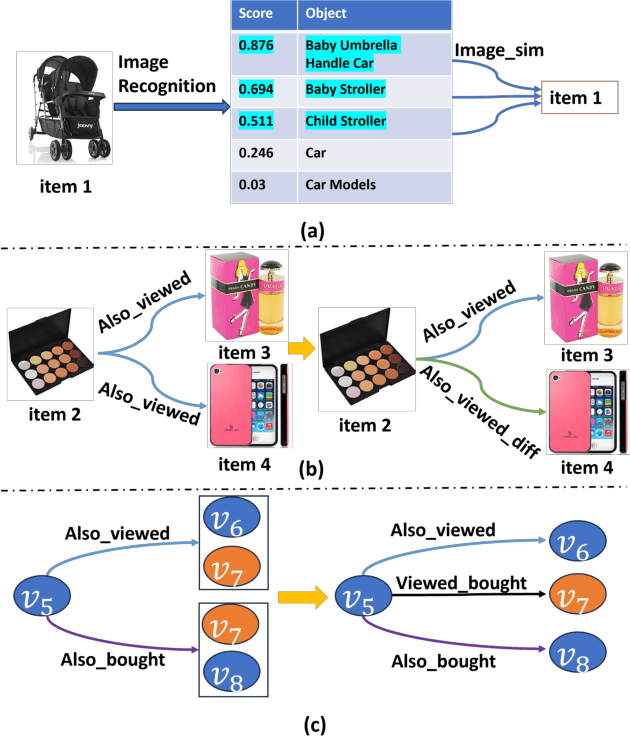

This paper explores providing explainability for session-based recommendation (SR) by path reasoning. Current SR models emphasize accuracy but lack explainability, while traditional path reasoning prioritizes knowledge graph exploration, ignoring sequential patterns present in the session history. Therefore, we propose a generalized hierarchical reinforcement learning framework for SR, which improves the explainability of existing SR models via Path Reasoning, namely PR4SR. Considering the different importance of items to the session, we design the session-level agent to select the items in the session as the starting point for path reasoning and the path-level agent to perform path reasoning. In particular, we design a multi-target reward mechanism to adapt to the skip behaviors of sequential patterns in SR, and introduce path midpoint reward to enhance the exploration efficiency in knowledge graphs. To improve the completeness of the knowledge graph and to diversify the paths of explanation, we incorporate extracted feature information from images into the knowledge graph. We instantiate PR4SR in five state-of-the-art SR models (i.e., GRU4REC, NARM, GCSAN, SR-GNN, SASRec) and compare it with other explainable SR frameworks, to demonstrate the effectiveness of PR4SR for recommendation and explanation tasks through extensive experiments with these approaches on four datasets.
From Indeterminacy to Determinacy: Augmenting Logical Reasoning Capabilities with Large Language Models
Oct 28, 2023Recent advances in LLMs have revolutionized the landscape of reasoning tasks. To enhance the capabilities of LLMs to emulate human reasoning, prior works focus on modeling reasoning steps using specific thought structures like chains, trees, or graphs. However, LLM-based reasoning continues to encounter three challenges: 1) Selecting appropriate reasoning structures for various tasks; 2) Exploiting known conditions sufficiently and efficiently to deduce new insights; 3) Considering the impact of historical reasoning experience. To address these challenges, we propose DetermLR, a novel reasoning framework that formulates the reasoning process as a transformational journey from indeterminate premises to determinate ones. This process is marked by the incremental accumulation of determinate premises, making the conclusion progressively closer to clarity. DetermLR includes three essential components: 1) Premise identification: We categorize premises into two distinct types: determinate and indeterminate. This empowers LLMs to customize reasoning structures to match the specific task complexities. 2) Premise prioritization and exploration: We leverage quantitative measurements to assess the relevance of each premise to the target, prioritizing more relevant premises for exploring new insights. 3) Iterative process with reasoning memory: We introduce a reasoning memory module to automate storage and extraction of available premises and reasoning paths, preserving historical reasoning details for more accurate premise prioritization. Comprehensive experimental results show that DetermLR outperforms all baselines on four challenging logical reasoning tasks: LogiQA, ProofWriter, FOLIO, and LogicalDeduction. DetermLR can achieve better reasoning performance while requiring fewer visited states, highlighting its superior efficiency and effectiveness in tackling logical reasoning tasks.
Generative and Contrastive Paradigms Are Complementary for Graph Self-Supervised Learning
Oct 24, 2023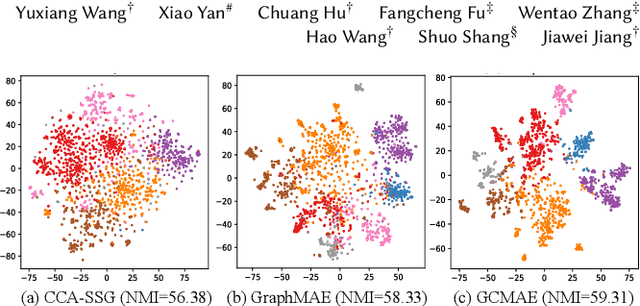
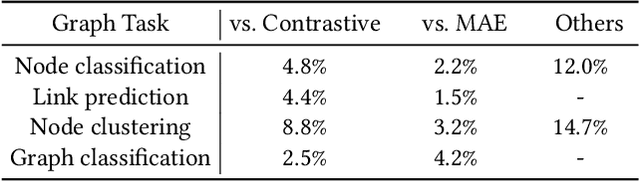
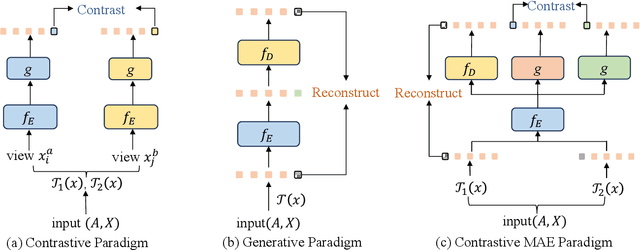
For graph self-supervised learning (GSSL), masked autoencoder (MAE) follows the generative paradigm and learns to reconstruct masked graph edges or node features. Contrastive Learning (CL) maximizes the similarity between augmented views of the same graph and is widely used for GSSL. However, MAE and CL are considered separately in existing works for GSSL. We observe that the MAE and CL paradigms are complementary and propose the graph contrastive masked autoencoder (GCMAE) framework to unify them. Specifically, by focusing on local edges or node features, MAE cannot capture global information of the graph and is sensitive to particular edges and features. On the contrary, CL excels in extracting global information because it considers the relation between graphs. As such, we equip GCMAE with an MAE branch and a CL branch, and the two branches share a common encoder, which allows the MAE branch to exploit the global information extracted by the CL branch. To force GCMAE to capture global graph structures, we train it to reconstruct the entire adjacency matrix instead of only the masked edges as in existing works. Moreover, a discrimination loss is proposed for feature reconstruction, which improves the disparity between node embeddings rather than reducing the reconstruction error to tackle the feature smoothing problem of MAE. We evaluate GCMAE on four popular graph tasks (i.e., node classification, node clustering, link prediction, and graph classification) and compare with 14 state-of-the-art baselines. The results show that GCMAE consistently provides good accuracy across these tasks, and the maximum accuracy improvement is up to 3.2% compared with the best-performing baseline.
BenchTemp: A General Benchmark for Evaluating Temporal Graph Neural Networks
Aug 31, 2023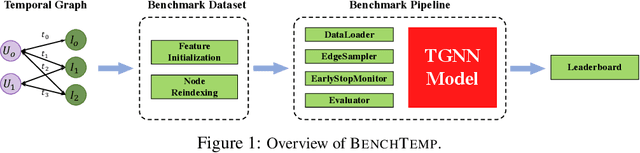

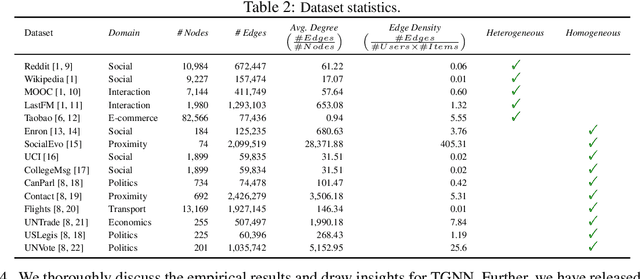
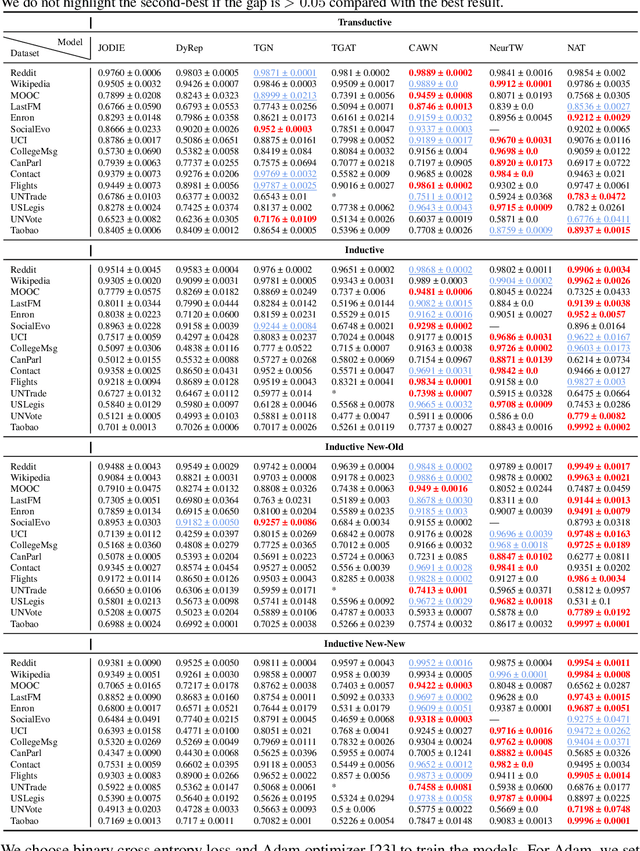
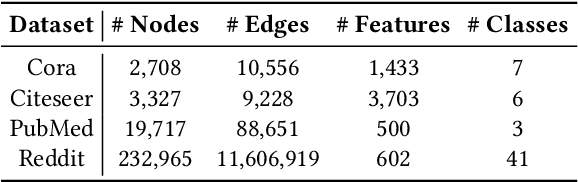
To handle graphs in which features or connectivities are evolving over time, a series of temporal graph neural networks (TGNNs) have been proposed. Despite the success of these TGNNs, the previous TGNN evaluations reveal several limitations regarding four critical issues: 1) inconsistent datasets, 2) inconsistent evaluation pipelines, 3) lacking workload diversity, and 4) lacking efficient comparison. Overall, there lacks an empirical study that puts TGNN models onto the same ground and compares them comprehensively. To this end, we propose BenchTemp, a general benchmark for evaluating TGNN models on various workloads. BenchTemp provides a set of benchmark datasets so that different TGNN models can be fairly compared. Further, BenchTemp engineers a standard pipeline that unifies the TGNN evaluation. With BenchTemp, we extensively compare the representative TGNN models on different tasks (e.g., link prediction and node classification) and settings (transductive and inductive), w.r.t. both effectiveness and efficiency metrics. We have made BenchTemp publicly available at https://github.com/qianghuangwhu/benchtemp.
CharacterChat: Learning towards Conversational AI with Personalized Social Support
Aug 20, 2023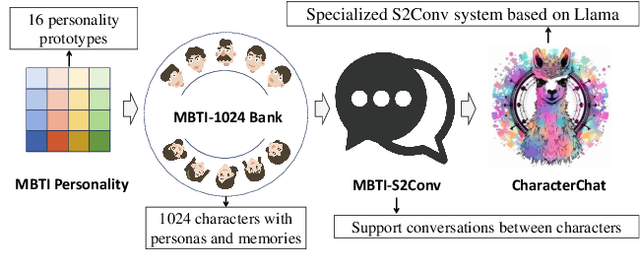

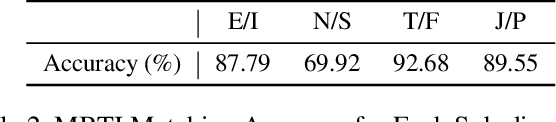

In our modern, fast-paced, and interconnected world, the importance of mental well-being has grown into a matter of great urgency. However, traditional methods such as Emotional Support Conversations (ESC) face challenges in effectively addressing a diverse range of individual personalities. In response, we introduce the Social Support Conversation (S2Conv) framework. It comprises a series of support agents and the interpersonal matching mechanism, linking individuals with persona-compatible virtual supporters. Utilizing persona decomposition based on the MBTI (Myers-Briggs Type Indicator), we have created the MBTI-1024 Bank, a group that of virtual characters with distinct profiles. Through improved role-playing prompts with behavior preset and dynamic memory, we facilitate the development of the MBTI-S2Conv dataset, which contains conversations between the characters in the MBTI-1024 Bank. Building upon these foundations, we present CharacterChat, a comprehensive S2Conv system, which includes a conversational model driven by personas and memories, along with an interpersonal matching plugin model that dispatches the optimal supporters from the MBTI-1024 Bank for individuals with specific personas. Empirical results indicate the remarkable efficacy of CharacterChat in providing personalized social support and highlight the substantial advantages derived from interpersonal matching. The source code is available in \url{https://github.com/morecry/CharacterChat}.