 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiang Huang
Who is Authentic Speaker
Apr 30, 2024
Voice conversion (VC) using deep learning technologies can now generate high quality one-to-many voices and thus has been used in some practical application fields, such as entertainment and healthcare. However, voice conversion can pose potential social issues when manipulated voices are employed for deceptive purposes. Moreover, it is a big challenge to find who are real speakers from the converted voices as the acoustic characteristics of source speakers are changed greatly. In this paper we attempt to explore the feasibility of identifying authentic speakers from converted voices. This study is conducted with the assumption that certain information from the source speakers persists, even when their voices undergo conversion into different target voices. Therefore our experiments are geared towards recognising the source speakers given the converted voices, which are generated by using FragmentVC on the randomly paired utterances from source and target speakers. To improve the robustness against converted voices, our recognition model is constructed by using hierarchical vector of locally aggregated descriptors (VLAD) in deep neural networks. The authentic speaker recognition system is mainly tested in two aspects, including the impact of quality of converted voices and the variations of VLAD. The dataset used in this work is VCTK corpus, where source and target speakers are randomly paired. The results obtained on the converted utterances show promising performances in recognising authentic speakers from converted voices.
LIKO: LiDAR, Inertial, and Kinematic Odometry for Bipedal Robots
Apr 28, 2024High-frequency and accurate state estimation is crucial for biped robots. This paper presents a tightly-coupled LiDAR-Inertial-Kinematic Odometry (LIKO) for biped robot state estimation based on an iterated extended Kalman filter. Beyond state estimation, the foot contact position is also modeled and estimated. This allows for both position and velocity updates from kinematic measurement. Additionally, the use of kinematic measurement results in an increased output state frequency of about 1kHz. This ensures temporal continuity of the estimated state and makes it practical for control purposes of biped robots. We also announce a biped robot dataset consisting of LiDAR, inertial measurement unit (IMU), joint encoders, force/torque (F/T) sensors, and motion capture ground truth to evaluate the proposed method. The dataset is collected during robot locomotion, and our approach reached the best quantitative result among other LIO-based methods and biped robot state estimation algorithms. The dataset and source code will be available at https://github.com/Mr-Zqr/LIKO.
Towards Controllable Time Series Generation
Mar 06, 2024



Time Series Generation (TSG) has emerged as a pivotal technique in synthesizing data that accurately mirrors real-world time series, becoming indispensable in numerous applications. Despite significant advancements in TSG, its efficacy frequently hinges on having large training datasets. This dependency presents a substantial challenge in data-scarce scenarios, especially when dealing with rare or unique conditions. To confront these challenges, we explore a new problem of Controllable Time Series Generation (CTSG), aiming to produce synthetic time series that can adapt to various external conditions, thereby tackling the data scarcity issue. In this paper, we propose \textbf{C}ontrollable \textbf{T}ime \textbf{S}eries (\textsf{CTS}), an innovative VAE-agnostic framework tailored for CTSG. A key feature of \textsf{CTS} is that it decouples the mapping process from standard VAE training, enabling precise learning of a complex interplay between latent features and external conditions. Moreover, we develop a comprehensive evaluation scheme for CTSG. Extensive experiments across three real-world time series datasets showcase \textsf{CTS}'s exceptional capabilities in generating high-quality, controllable outputs. This underscores its adeptness in seamlessly integrating latent features with external conditions. Extending \textsf{CTS} to the image domain highlights its remarkable potential for explainability and further reinforces its versatility across different modalities.
Diversity-Aware $k$-Maximum Inner Product Search Revisited
Feb 21, 2024The $k$-Maximum Inner Product Search ($k$MIPS) serves as a foundational component in recommender systems and various data mining tasks. However, while most existing $k$MIPS approaches prioritize the efficient retrieval of highly relevant items for users, they often neglect an equally pivotal facet of search results: \emph{diversity}. To bridge this gap, we revisit and refine the diversity-aware $k$MIPS (D$k$MIPS) problem by incorporating two well-known diversity objectives -- minimizing the average and maximum pairwise item similarities within the results -- into the original relevance objective. This enhancement, inspired by Maximal Marginal Relevance (MMR), offers users a controllable trade-off between relevance and diversity. We introduce \textsc{Greedy} and \textsc{DualGreedy}, two linear scan-based algorithms tailored for D$k$MIPS. They both achieve data-dependent approximations and, when aiming to minimize the average pairwise similarity, \textsc{DualGreedy} attains an approximation ratio of $1/4$ with an additive term for regularization. To further improve query efficiency, we integrate a lightweight Ball-Cone Tree (BC-Tree) index with the two algorithms. Finally, comprehensive experiments on ten real-world data sets demonstrate the efficacy of our proposed methods, showcasing their capability to efficiently deliver diverse and relevant search results to users.
From Zero to Hero: Detecting Leaked Data through Synthetic Data Injection and Model Querying
Oct 06, 2023



Safeguarding the Intellectual Property (IP) of data has become critically important as machine learning applications continue to proliferate, and their success heavily relies on the quality of training data. While various mechanisms exist to secure data during storage, transmission, and consumption, fewer studies have been developed to detect whether they are already leaked for model training without authorization. This issue is particularly challenging due to the absence of information and control over the training process conducted by potential attackers. In this paper, we concentrate on the domain of tabular data and introduce a novel methodology, Local Distribution Shifting Synthesis (\textsc{LDSS}), to detect leaked data that are used to train classification models. The core concept behind \textsc{LDSS} involves injecting a small volume of synthetic data--characterized by local shifts in class distribution--into the owner's dataset. This enables the effective identification of models trained on leaked data through model querying alone, as the synthetic data injection results in a pronounced disparity in the predictions of models trained on leaked and modified datasets. \textsc{LDSS} is \emph{model-oblivious} and hence compatible with a diverse range of classification models, such as Naive Bayes, Decision Tree, and Random Forest. We have conducted extensive experiments on seven types of classification models across five real-world datasets. The comprehensive results affirm the reliability, robustness, fidelity, security, and efficiency of \textsc{LDSS}.
TSGBench: Time Series Generation Benchmark
Sep 07, 2023Synthetic Time Series Generation (TSG) is crucial in a range of applications, including data augmentation, anomaly detection, and privacy preservation. Although significant strides have been made in this field, existing methods exhibit three key limitations: (1) They often benchmark against similar model types, constraining a holistic view of performance capabilities. (2) The use of specialized synthetic and private datasets introduces biases and hampers generalizability. (3) Ambiguous evaluation measures, often tied to custom networks or downstream tasks, hinder consistent and fair comparison. To overcome these limitations, we introduce \textsf{TSGBench}, the inaugural TSG Benchmark, designed for a unified and comprehensive assessment of TSG methods. It comprises three modules: (1) a curated collection of publicly available, real-world datasets tailored for TSG, together with a standardized preprocessing pipeline; (2) a comprehensive evaluation measures suite including vanilla measures, new distance-based assessments, and visualization tools; (3) a pioneering generalization test rooted in Domain Adaptation (DA), compatible with all methods. We have conducted extensive experiments across ten real-world datasets from diverse domains, utilizing ten advanced TSG methods and twelve evaluation measures, all gauged through \textsf{TSGBench}. The results highlight its remarkable efficacy and consistency. More importantly, \textsf{TSGBench} delivers a statistical breakdown of method rankings, illuminating performance variations across different datasets and measures, and offering nuanced insights into the effectiveness of each method.
Does Misclassifying Non-confounding Covariates as Confounders Affect the Causal Inference within the Potential Outcomes Framework?
Sep 05, 2023


The Potential Outcome Framework (POF) plays a prominent role in the field of causal inference. Most causal inference models based on the POF (CIMs-POF) are designed for eliminating confounding bias and default to an underlying assumption of Confounding Covariates. This assumption posits that the covariates consist solely of confounders. However, the assumption of Confounding Covariates is challenging to maintain in practice, particularly when dealing with high-dimensional covariates. While certain methods have been proposed to differentiate the distinct components of covariates prior to conducting causal inference, the consequences of treating non-confounding covariates as confounders remain unclear. This ambiguity poses a potential risk when conducting causal inference in practical scenarios. In this paper, we present a unified graphical framework for the CIMs-POF, which greatly enhances the comprehension of these models' underlying principles. Using this graphical framework, we quantitatively analyze the extent to which the inference performance of CIMs-POF is influenced when incorporating various types of non-confounding covariates, such as instrumental variables, mediators, colliders, and adjustment variables. The key findings are: in the task of eliminating confounding bias, the optimal scenario is for the covariates to exclusively encompass confounders; in the subsequent task of inferring counterfactual outcomes, the adjustment variables contribute to more accurate inferences. Furthermore, extensive experiments conducted on synthetic datasets consistently validate these theoretical conclusions.
BenchTemp: A General Benchmark for Evaluating Temporal Graph Neural Networks
Aug 31, 2023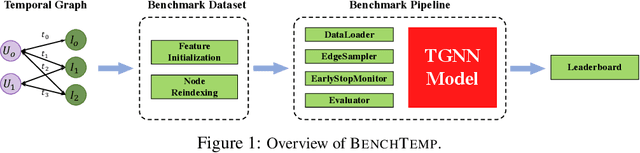

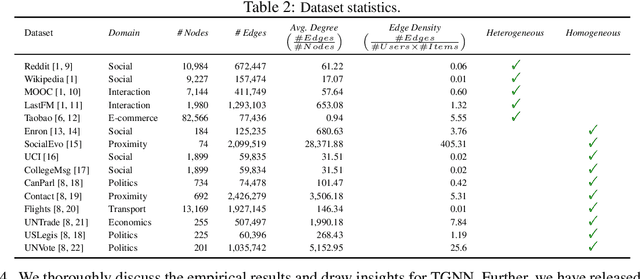
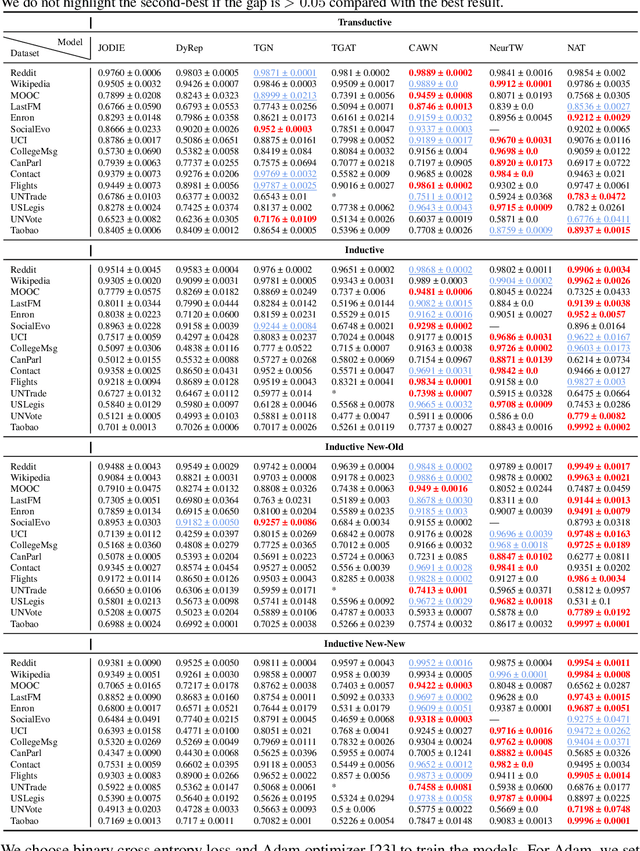
To handle graphs in which features or connectivities are evolving over time, a series of temporal graph neural networks (TGNNs) have been proposed. Despite the success of these TGNNs, the previous TGNN evaluations reveal several limitations regarding four critical issues: 1) inconsistent datasets, 2) inconsistent evaluation pipelines, 3) lacking workload diversity, and 4) lacking efficient comparison. Overall, there lacks an empirical study that puts TGNN models onto the same ground and compares them comprehensively. To this end, we propose BenchTemp, a general benchmark for evaluating TGNN models on various workloads. BenchTemp provides a set of benchmark datasets so that different TGNN models can be fairly compared. Further, BenchTemp engineers a standard pipeline that unifies the TGNN evaluation. With BenchTemp, we extensively compare the representative TGNN models on different tasks (e.g., link prediction and node classification) and settings (transductive and inductive), w.r.t. both effectiveness and efficiency metrics. We have made BenchTemp publicly available at https://github.com/qianghuangwhu/benchtemp.
VLUCI: Variational Learning of Unobserved Confounders for Counterfactual Inference
Aug 02, 2023



Causal inference plays a vital role in diverse domains like epidemiology, healthcare, and economics. De-confounding and counterfactual prediction in observational data has emerged as a prominent concern in causal inference research. While existing models tackle observed confounders, the presence of unobserved confounders remains a significant challenge, distorting causal inference and impacting counterfactual outcome accuracy. To address this, we propose a novel variational learning model of unobserved confounders for counterfactual inference (VLUCI), which generates the posterior distribution of unobserved confounders. VLUCI relaxes the unconfoundedness assumption often overlooked by most causal inference methods. By disentangling observed and unobserved confounders, VLUCI constructs a doubly variational inference model to approximate the distribution of unobserved confounders, which are used for inferring more accurate counterfactual outcomes. Extensive experiments on synthetic and semi-synthetic datasets demonstrate VLUCI's superior performance in inferring unobserved confounders. It is compatible with state-of-the-art counterfactual inference models, significantly improving inference accuracy at both group and individual levels. Additionally, VLUCI provides confidence intervals for counterfactual outcomes, aiding decision-making in risk-sensitive domains. We further clarify the considerations when applying VLUCI to cases where unobserved confounders don't strictly conform to our model assumptions using the public IHDP dataset as an example, highlighting the practical advantages of VLUCI.
De-confounding Representation Learning for Counterfactual Inference on Continuous Treatment via Generative Adversarial Network
Jul 24, 2023



Counterfactual inference for continuous rather than binary treatment variables is more common in real-world causal inference tasks. While there are already some sample reweighting methods based on Marginal Structural Model for eliminating the confounding bias, they generally focus on removing the treatment's linear dependence on confounders and rely on the accuracy of the assumed parametric models, which are usually unverifiable. In this paper, we propose a de-confounding representation learning (DRL) framework for counterfactual outcome estimation of continuous treatment by generating the representations of covariates disentangled with the treatment variables. The DRL is a non-parametric model that eliminates both linear and nonlinear dependence between treatment and covariates. Specifically, we train the correlations between the de-confounded representations and the treatment variables against the correlations between the covariate representations and the treatment variables to eliminate confounding bias. Further, a counterfactual inference network is embedded into the framework to make the learned representations serve both de-confounding and trusted inference. Extensive experiments on synthetic datasets show that the DRL model performs superiorly in learning de-confounding representations and outperforms state-of-the-art counterfactual inference models for continuous treatment variables. In addition, we apply the DRL model to a real-world medical dataset MIMIC and demonstrate a detailed causal relationship between red cell width distribution and mortality.