 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongliang Shi
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
May 05, 2024
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
An Onboard Framework for Staircases Modeling Based on Point Clouds
May 03, 2024The detection of traversable regions on staircases and the physical modeling constitutes pivotal aspects of the mobility of legged robots. This paper presents an onboard framework tailored to the detection of traversable regions and the modeling of physical attributes of staircases by point cloud data. To mitigate the influence of illumination variations and the overfitting due to the dataset diversity, a series of data augmentations are introduced to enhance the training of the fundamental network. A curvature suppression cross-entropy(CSCE) loss is proposed to reduce the ambiguity of prediction on the boundary between traversable and non-traversable regions. Moreover, a measurement correction based on the pose estimation of stairs is introduced to calibrate the output of raw modeling that is influenced by tilted perspectives. Lastly, we collect a dataset pertaining to staircases and introduce new evaluation criteria. Through a series of rigorous experiments conducted on this dataset, we substantiate the superior accuracy and generalization capabilities of our proposed method. Codes, models, and datasets will be available at https://github.com/szturobotics/Stair-detection-and-modeling-project.
LIKO: LiDAR, Inertial, and Kinematic Odometry for Bipedal Robots
Apr 28, 2024High-frequency and accurate state estimation is crucial for biped robots. This paper presents a tightly-coupled LiDAR-Inertial-Kinematic Odometry (LIKO) for biped robot state estimation based on an iterated extended Kalman filter. Beyond state estimation, the foot contact position is also modeled and estimated. This allows for both position and velocity updates from kinematic measurement. Additionally, the use of kinematic measurement results in an increased output state frequency of about 1kHz. This ensures temporal continuity of the estimated state and makes it practical for control purposes of biped robots. We also announce a biped robot dataset consisting of LiDAR, inertial measurement unit (IMU), joint encoders, force/torque (F/T) sensors, and motion capture ground truth to evaluate the proposed method. The dataset is collected during robot locomotion, and our approach reached the best quantitative result among other LIO-based methods and biped robot state estimation algorithms. The dataset and source code will be available at https://github.com/Mr-Zqr/LIKO.
Block-Map-Based Localization in Large-Scale Environment
Apr 28, 2024Accurate localization is an essential technology for the flexible navigation of robots in large-scale environments. Both SLAM-based and map-based localization will increase the computing load due to the increase in map size, which will affect downstream tasks such as robot navigation and services. To this end, we propose a localization system based on Block Maps (BMs) to reduce the computational load caused by maintaining large-scale maps. Firstly, we introduce a method for generating block maps and the corresponding switching strategies, ensuring that the robot can estimate the state in large-scale environments by loading local map information. Secondly, global localization according to Branch-and-Bound Search (BBS) in the 3D map is introduced to provide the initial pose. Finally, a graph-based optimization method is adopted with a dynamic sliding window that determines what factors are being marginalized whether a robot is exposed to a BM or switching to another one, which maintains the accuracy and efficiency of pose tracking. Comparison experiments are performed on publicly available large-scale datasets. Results show that the proposed method can track the robot pose even though the map scale reaches more than 6 kilometers, while efficient and accurate localization is still guaranteed on NCLT and M2DGR.
P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
Mar 29, 2024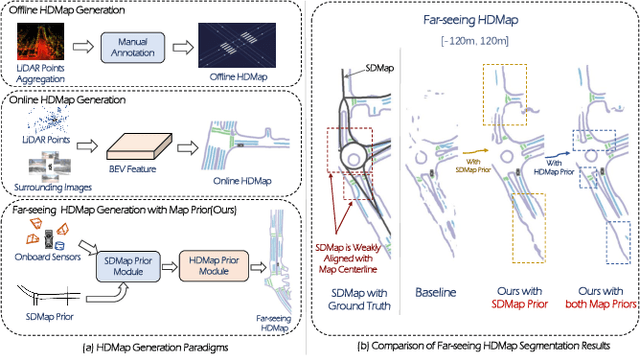
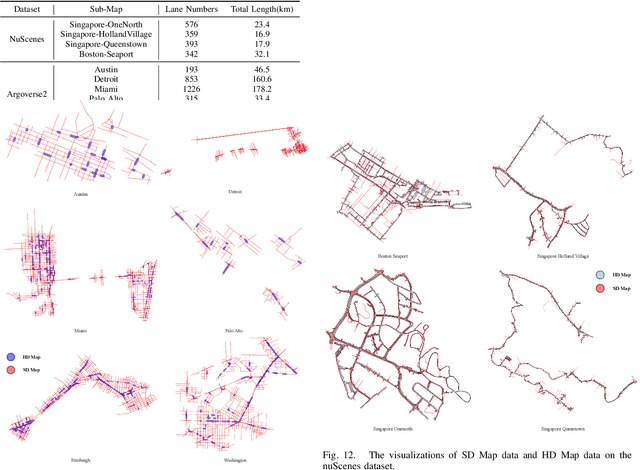
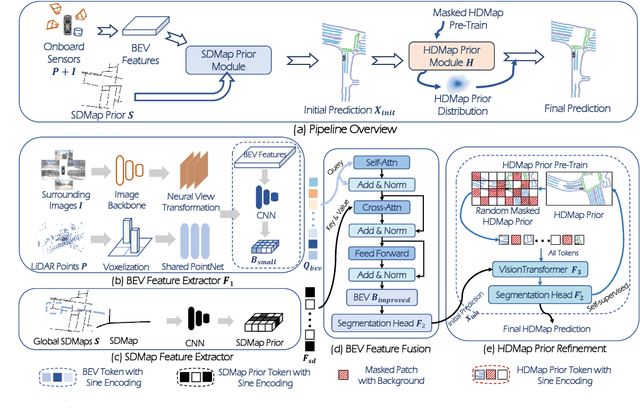
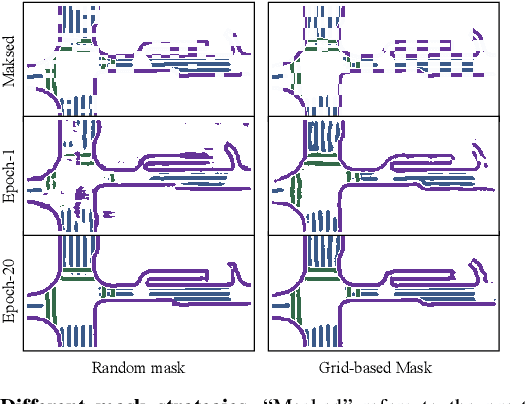
Autonomous vehicles are gradually entering city roads today, with the help of high-definition maps (HDMaps). However, the reliance on HDMaps prevents autonomous vehicles from stepping into regions without this expensive digital infrastructure. This fact drives many researchers to study online HDMap generation algorithms, but the performance of these algorithms at far regions is still unsatisfying. We present P-MapNet, in which the letter P highlights the fact that we focus on incorporating map priors to improve model performance. Specifically, we exploit priors in both SDMap and HDMap. On one hand, we extract weakly aligned SDMap from OpenStreetMap, and encode it as an additional conditioning branch. Despite the misalignment challenge, our attention-based architecture adaptively attends to relevant SDMap skeletons and significantly improves performance. On the other hand, we exploit a masked autoencoder to capture the prior distribution of HDMap, which can serve as a refinement module to mitigate occlusions and artifacts. We benchmark on the nuScenes and Argoverse2 datasets. Through comprehensive experiments, we show that: (1) our SDMap prior can improve online map generation performance, using both rasterized (by up to $+18.73$ $\rm mIoU$) and vectorized (by up to $+8.50$ $\rm mAP$) output representations. (2) our HDMap prior can improve map perceptual metrics by up to $6.34\%$. (3) P-MapNet can be switched into different inference modes that covers different regions of the accuracy-efficiency trade-off landscape. (4) P-MapNet is a far-seeing solution that brings larger improvements on longer ranges. Codes and models are publicly available at https://jike5.github.io/P-MapNet.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023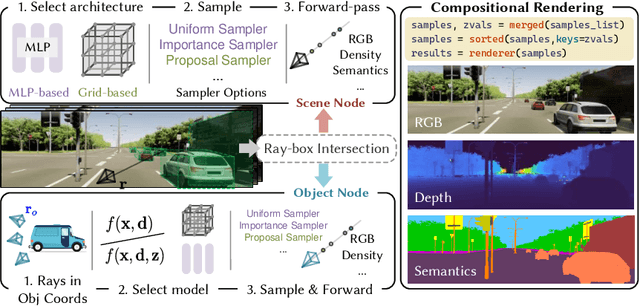

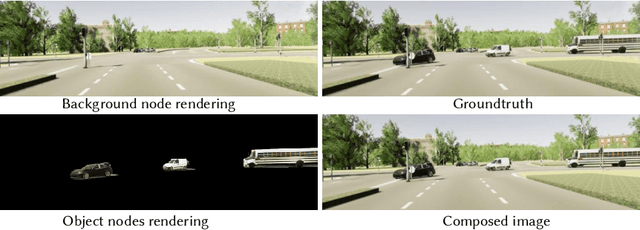
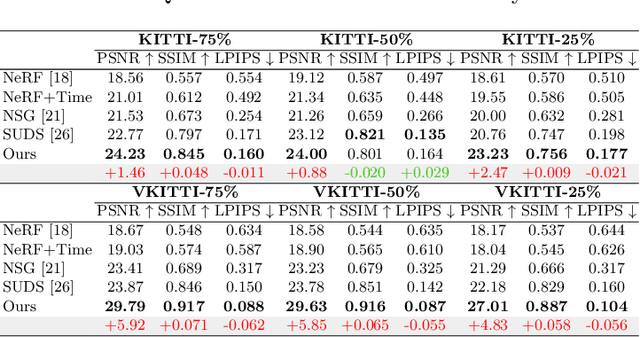
Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.
LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
Feb 27, 2023
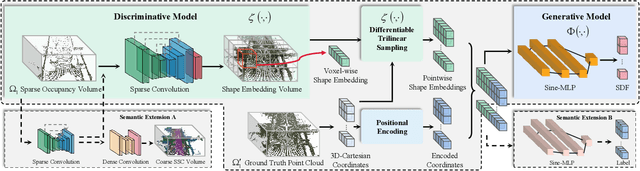
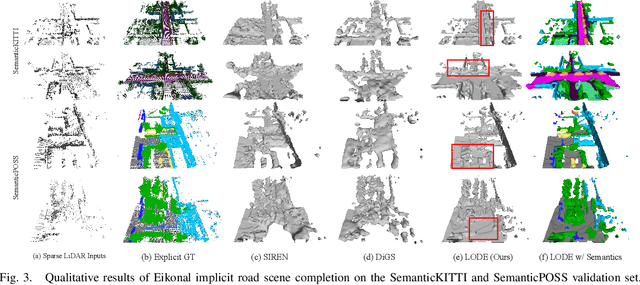
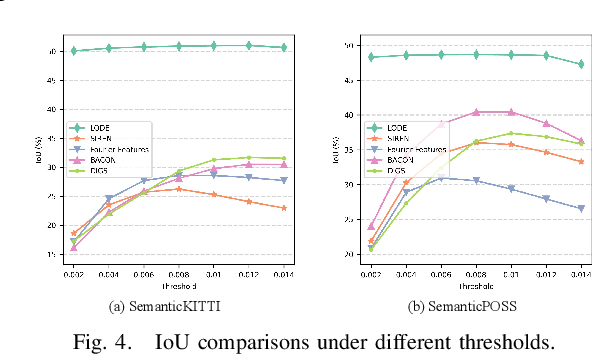
Scene completion refers to obtaining dense scene representation from an incomplete perception of complex 3D scenes. This helps robots detect multi-scale obstacles and analyse object occlusions in scenarios such as autonomous driving. Recent advances show that implicit representation learning can be leveraged for continuous scene completion and achieved through physical constraints like Eikonal equations. However, former Eikonal completion methods only demonstrate results on watertight meshes at a scale of tens of meshes. None of them are successfully done for non-watertight LiDAR point clouds of open large scenes at a scale of thousands of scenes. In this paper, we propose a novel Eikonal formulation that conditions the implicit representation on localized shape priors which function as dense boundary value constraints, and demonstrate it works on SemanticKITTI and SemanticPOSS. It can also be extended to semantic Eikonal scene completion with only small modifications to the network architecture. With extensive quantitative and qualitative results, we demonstrate the benefits and drawbacks of existing Eikonal methods, which naturally leads to the new locally conditioned formulation. Notably, we improve IoU from 31.7% to 51.2% on SemanticKITTI and from 40.5% to 48.7% on SemanticPOSS. We extensively ablate our methods and demonstrate that the proposed formulation is robust to a wide spectrum of implementation hyper-parameters. Codes and models are publicly available at https://github.com/AIR-DISCOVER/LODE.
AsyncNeRF: Learning Large-scale Radiance Fields from Asynchronous RGB-D Sequences with Time-Pose Function
Nov 14, 2022



Large-scale radiance fields are promising mapping tools for smart transportation applications like autonomous driving or drone delivery. But for large-scale scenes, compact synchronized RGB-D cameras are not applicable due to limited sensing range, and using separate RGB and depth sensors inevitably leads to unsynchronized sequences. Inspired by the recent success of self-calibrating radiance field training methods that do not require known intrinsic or extrinsic parameters, we propose the first solution that self-calibrates the mismatch between RGB and depth frames. We leverage the important domain-specific fact that RGB and depth frames are actually sampled from the same trajectory and develop a novel implicit network called the time-pose function. Combining it with a large-scale radiance field leads to an architecture that cascades two implicit representation networks. To validate its effectiveness, we construct a diverse and photorealistic dataset that covers various RGB-D mismatch scenarios. Through a comprehensive benchmarking on this dataset, we demonstrate the flexibility of our method in different scenarios and superior performance over applicable prior counterparts. Codes, data, and models will be made publicly available.
TOIST: Task Oriented Instance Segmentation Transformer with Noun-Pronoun Distillation
Oct 19, 2022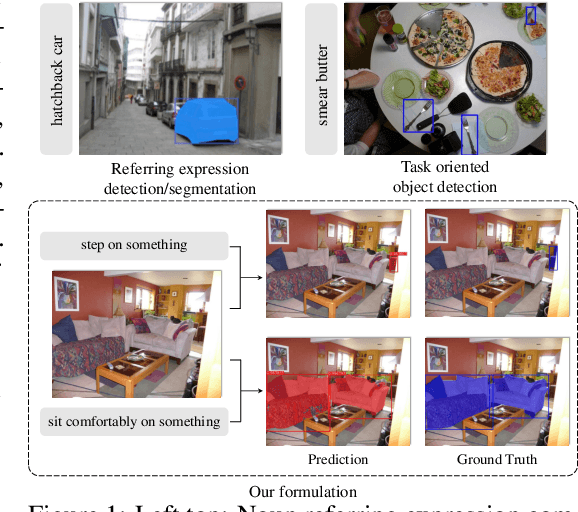

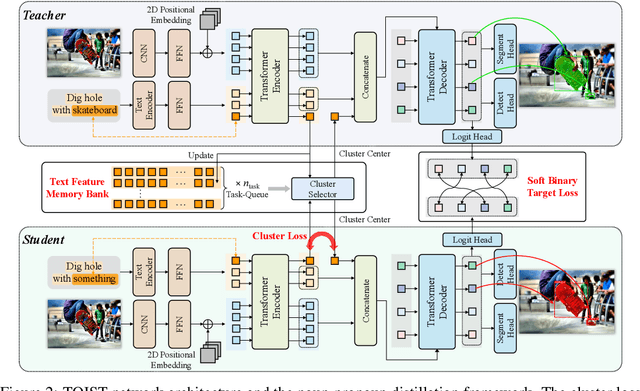
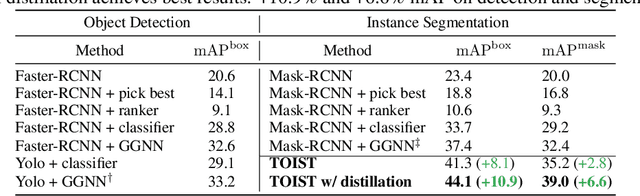
Current referring expression comprehension algorithms can effectively detect or segment objects indicated by nouns, but how to understand verb reference is still under-explored. As such, we study the challenging problem of task oriented detection, which aims to find objects that best afford an action indicated by verbs like sit comfortably on. Towards a finer localization that better serves downstream applications like robot interaction, we extend the problem into task oriented instance segmentation. A unique requirement of this task is to select preferred candidates among possible alternatives. Thus we resort to the transformer architecture which naturally models pair-wise query relationships with attention, leading to the TOIST method. In order to leverage pre-trained noun referring expression comprehension models and the fact that we can access privileged noun ground truth during training, a novel noun-pronoun distillation framework is proposed. Noun prototypes are generated in an unsupervised manner and contextual pronoun features are trained to select prototypes. As such, the network remains noun-agnostic during inference. We evaluate TOIST on the large-scale task oriented dataset COCO-Tasks and achieve +10.9% higher $\rm{mAP^{box}}$ than the best-reported results. The proposed noun-pronoun distillation can boost $\rm{mAP^{box}}$ and $\rm{mAP^{mask}}$ by +2.8% and +3.8%. Codes and models are publicly available at https://github.com/AIR-DISCOVER/TOIST.
City-scale Incremental Neural Mapping with Three-layer Sampling and Panoptic Representation
Sep 28, 2022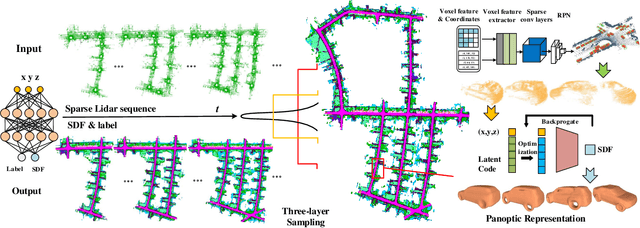

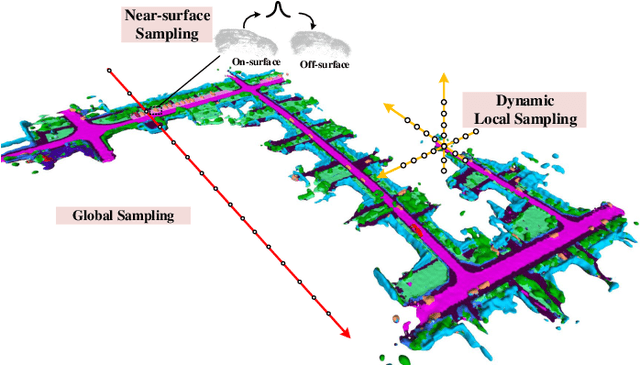

Neural implicit representations are drawing a lot of attention from the robotics community recently, as they are expressive, continuous and compact. However, city-scale incremental implicit dense mapping based on sparse LiDAR input is still an under-explored challenge. To this end,we successfully build the first city-scale incremental neural mapping system with a panoptic representation that consists of both environment-level and instance-level modelling. Given a stream of sparse LiDAR point cloud, it maintains a dynamic generative model that maps 3D coordinates to signed distance field (SDF) values. To address the difficulty of representing geometric information at different levels in city-scale space, we propose a tailored three-layer sampling strategy to dynamically sample the global, local and near-surface domains. Meanwhile, to realize high fidelity mapping, category-specific prior is introduced to better model the geometric details, leading to a panoptic representation. We evaluate on the public SemanticKITTI dataset and demonstrate the significance of the newly proposed three-layer sampling strategy and panoptic representation, using both quantitative and qualitative results. Codes and data will be publicly available.