 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHang Zhao
Generating Comprehensive Lithium Battery Charging Data with Generative AI
Apr 11, 2024
In optimizing performance and extending the lifespan of lithium batteries, accurate state prediction is pivotal. Traditional regression and classification methods have achieved some success in battery state prediction. However, the efficacy of these data-driven approaches heavily relies on the availability and quality of public datasets. Additionally, generating electrochemical data predominantly through battery experiments is a lengthy and costly process, making it challenging to acquire high-quality electrochemical data. This difficulty, coupled with data incompleteness, significantly impacts prediction accuracy. Addressing these challenges, this study introduces the End of Life (EOL) and Equivalent Cycle Life (ECL) as conditions for generative AI models. By integrating an embedding layer into the CVAE model, we developed the Refined Conditional Variational Autoencoder (RCVAE). Through preprocessing data into a quasi-video format, our study achieves an integrated synthesis of electrochemical data, including voltage, current, temperature, and charging capacity, which is then processed by the RCVAE model. Coupled with customized training and inference algorithms, this model can generate specific electrochemical data for EOL and ECL under supervised conditions. This method provides users with a comprehensive electrochemical dataset, pioneering a new research domain for the artificial synthesis of lithium battery data. Furthermore, based on the detailed synthetic data, various battery state indicators can be calculated, offering new perspectives and possibilities for lithium battery performance prediction.
P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
Mar 29, 2024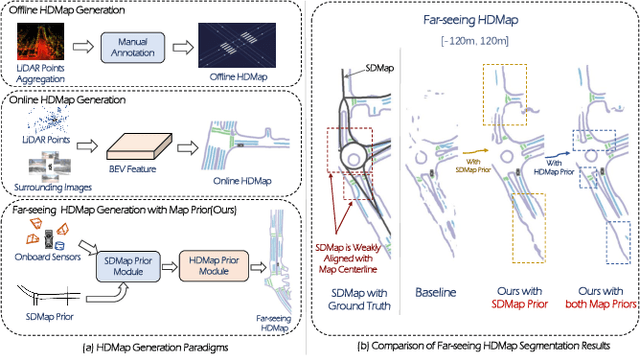
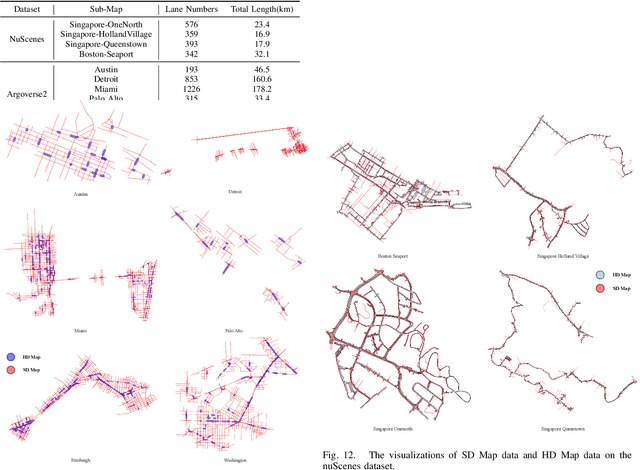
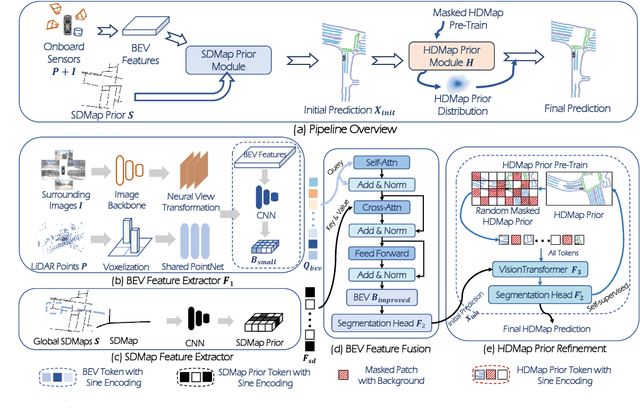
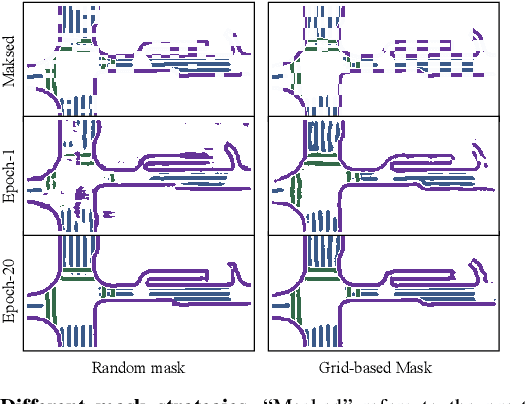
Autonomous vehicles are gradually entering city roads today, with the help of high-definition maps (HDMaps). However, the reliance on HDMaps prevents autonomous vehicles from stepping into regions without this expensive digital infrastructure. This fact drives many researchers to study online HDMap generation algorithms, but the performance of these algorithms at far regions is still unsatisfying. We present P-MapNet, in which the letter P highlights the fact that we focus on incorporating map priors to improve model performance. Specifically, we exploit priors in both SDMap and HDMap. On one hand, we extract weakly aligned SDMap from OpenStreetMap, and encode it as an additional conditioning branch. Despite the misalignment challenge, our attention-based architecture adaptively attends to relevant SDMap skeletons and significantly improves performance. On the other hand, we exploit a masked autoencoder to capture the prior distribution of HDMap, which can serve as a refinement module to mitigate occlusions and artifacts. We benchmark on the nuScenes and Argoverse2 datasets. Through comprehensive experiments, we show that: (1) our SDMap prior can improve online map generation performance, using both rasterized (by up to $+18.73$ $\rm mIoU$) and vectorized (by up to $+8.50$ $\rm mAP$) output representations. (2) our HDMap prior can improve map perceptual metrics by up to $6.34\%$. (3) P-MapNet can be switched into different inference modes that covers different regions of the accuracy-efficiency trade-off landscape. (4) P-MapNet is a far-seeing solution that brings larger improvements on longer ranges. Codes and models are publicly available at https://jike5.github.io/P-MapNet.
PreSight: Enhancing Autonomous Vehicle Perception with City-Scale NeRF Priors
Mar 14, 2024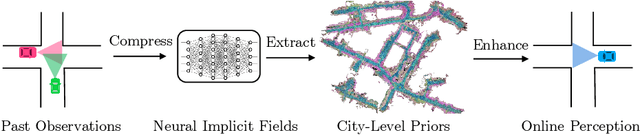
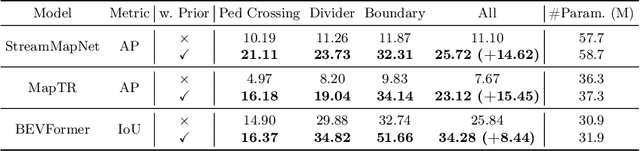
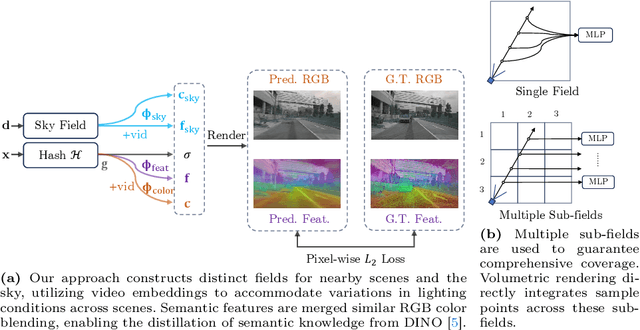
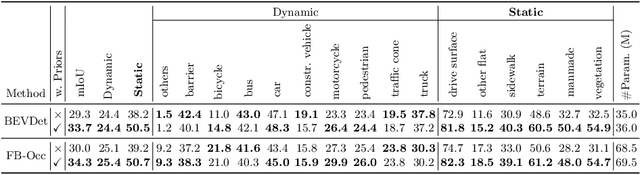
Autonomous vehicles rely extensively on perception systems to navigate and interpret their surroundings. Despite significant advancements in these systems recently, challenges persist under conditions like occlusion, extreme lighting, or in unfamiliar urban areas. Unlike these systems, humans do not solely depend on immediate observations to perceive the environment. In navigating new cities, humans gradually develop a preliminary mental map to supplement real-time perception during subsequent visits. Inspired by this human approach, we introduce a novel framework, Pre-Sight, that leverages past traversals to construct static prior memories, enhancing online perception in later navigations. Our method involves optimizing a city-scale neural radiance field with data from previous journeys to generate neural priors. These priors, rich in semantic and geometric details, are derived without manual annotations and can seamlessly augment various state-of-the-art perception models, improving their efficacy with minimal additional computational cost. Experimental results on the nuScenes dataset demonstrate the framework's high compatibility with diverse online perception models. Specifically, it shows remarkable improvements in HD-map construction and occupancy prediction tasks, highlighting its potential as a new perception framework for autonomous driving systems. Our code will be released at https://github.com/yuantianyuan01/PreSight.
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Feb 25, 2024A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of chain-of-thought (CoT) modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. DriveVLM-Dual achieves robust spatial understanding and real-time inference speed. Extensive experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the effectiveness of DriveVLM and the enhanced performance of DriveVLM-Dual, surpassing existing methods in complex and unpredictable driving conditions.
SLIT: Boosting Audio-Text Pre-Training via Multi-Stage Learning and Instruction Tuning
Feb 20, 2024Audio-text pre-training (ATP) has witnessed remarkable strides across a variety of downstream tasks. Yet, most existing pretrained audio models only specialize in either discriminative tasks or generative tasks. In this study, we develop SLIT, a novel ATP framework which transfers flexibly to both audio-text understanding and generation tasks, bootstrapping audio-text pre-training from frozen pretrained audio encoders and large language models. To bridge the modality gap during pre-training, we leverage Q-Former, which undergoes a multi-stage pre-training process. The first stage enhances audio-text representation learning from a frozen audio encoder, while the second stage boosts audio-to-text generative learning with a frozen language model. Furthermore, we introduce an ATP instruction tuning strategy, which enables flexible and informative feature extraction tailered to the given instructions for different tasks. Experiments show that SLIT achieves superior performances on a variety of audio-text understanding and generation tasks, and even demonstrates strong generalization capabilities when directly applied to zero-shot scenarios.
PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models
Jan 10, 2024This technical report introduces PIXART-{\delta}, a text-to-image synthesis framework that integrates the Latent Consistency Model (LCM) and ControlNet into the advanced PIXART-{\alpha} model. PIXART-{\alpha} is recognized for its ability to generate high-quality images of 1024px resolution through a remarkably efficient training process. The integration of LCM in PIXART-{\delta} significantly accelerates the inference speed, enabling the production of high-quality images in just 2-4 steps. Notably, PIXART-{\delta} achieves a breakthrough 0.5 seconds for generating 1024x1024 pixel images, marking a 7x improvement over the PIXART-{\alpha}. Additionally, PIXART-{\delta} is designed to be efficiently trainable on 32GB V100 GPUs within a single day. With its 8-bit inference capability (von Platen et al., 2023), PIXART-{\delta} can synthesize 1024px images within 8GB GPU memory constraints, greatly enhancing its usability and accessibility. Furthermore, incorporating a ControlNet-like module enables fine-grained control over text-to-image diffusion models. We introduce a novel ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation. As a state-of-the-art, open-source image generation model, PIXART-{\delta} offers a promising alternative to the Stable Diffusion family of models, contributing significantly to text-to-image synthesis.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.