 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenguo Li
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Apr 16, 2024
Large Vision-Language Models (LVLMs), due to the remarkable visual reasoning ability to understand images and videos, have received widespread attention in the autonomous driving domain, which significantly advances the development of interpretable end-to-end autonomous driving. However, current evaluations of LVLMs primarily focus on the multi-faceted capabilities in common scenarios, lacking quantifiable and automated assessment in autonomous driving contexts, let alone severe road corner cases that even the state-of-the-art autonomous driving perception systems struggle to handle. In this paper, we propose CODA-LM, a novel vision-language benchmark for self-driving, which provides the first automatic and quantitative evaluation of LVLMs for interpretable autonomous driving including general perception, regional perception, and driving suggestions. CODA-LM utilizes the texts to describe the road images, exploiting powerful text-only large language models (LLMs) without image inputs to assess the capabilities of LVLMs in autonomous driving scenarios, which reveals stronger alignment with human preferences than LVLM judges. Experiments demonstrate that even the closed-sourced commercial LVLMs like GPT-4V cannot deal with road corner cases well, suggesting that we are still far from a strong LVLM-powered intelligent driving agent, and we hope our CODA-LM can become the catalyst to promote future development.
DetCLIPv3: Towards Versatile Generative Open-vocabulary Object Detection
Apr 14, 2024Existing open-vocabulary object detectors typically require a predefined set of categories from users, significantly confining their application scenarios. In this paper, we introduce DetCLIPv3, a high-performing detector that excels not only at both open-vocabulary object detection, but also generating hierarchical labels for detected objects. DetCLIPv3 is characterized by three core designs: 1. Versatile model architecture: we derive a robust open-set detection framework which is further empowered with generation ability via the integration of a caption head. 2. High information density data: we develop an auto-annotation pipeline leveraging visual large language model to refine captions for large-scale image-text pairs, providing rich, multi-granular object labels to enhance the training. 3. Efficient training strategy: we employ a pre-training stage with low-resolution inputs that enables the object captioner to efficiently learn a broad spectrum of visual concepts from extensive image-text paired data. This is followed by a fine-tuning stage that leverages a small number of high-resolution samples to further enhance detection performance. With these effective designs, DetCLIPv3 demonstrates superior open-vocabulary detection performance, \eg, our Swin-T backbone model achieves a notable 47.0 zero-shot fixed AP on the LVIS minival benchmark, outperforming GLIPv2, GroundingDINO, and DetCLIPv2 by 18.0/19.6/6.6 AP, respectively. DetCLIPv3 also achieves a state-of-the-art 19.7 AP in dense captioning task on VG dataset, showcasing its strong generative capability.
CVT-xRF: Contrastive In-Voxel Transformer for 3D Consistent Radiance Fields from Sparse Inputs
Mar 25, 2024Neural Radiance Fields (NeRF) have shown impressive capabilities for photorealistic novel view synthesis when trained on dense inputs. However, when trained on sparse inputs, NeRF typically encounters issues of incorrect density or color predictions, mainly due to insufficient coverage of the scene causing partial and sparse supervision, thus leading to significant performance degradation. While existing works mainly consider ray-level consistency to construct 2D learning regularization based on rendered color, depth, or semantics on image planes, in this paper we propose a novel approach that models 3D spatial field consistency to improve NeRF's performance with sparse inputs. Specifically, we first adopt a voxel-based ray sampling strategy to ensure that the sampled rays intersect with a certain voxel in 3D space. We then randomly sample additional points within the voxel and apply a Transformer to infer the properties of other points on each ray, which are then incorporated into the volume rendering. By backpropagating through the rendering loss, we enhance the consistency among neighboring points. Additionally, we propose to use a contrastive loss on the encoder output of the Transformer to further improve consistency within each voxel. Experiments demonstrate that our method yields significant improvement over different radiance fields in the sparse inputs setting, and achieves comparable performance with current works.
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Mar 25, 2024End-to-end driving has made significant progress in recent years, demonstrating benefits such as system simplicity and competitive driving performance under both open-loop and closed-loop settings. Nevertheless, the lack of interpretability and controllability in its driving decisions hinders real-world deployment for end-to-end driving systems. In this paper, we collect a comprehensive end-to-end driving dataset named DriveCoT, leveraging the CARLA simulator. It contains sensor data, control decisions, and chain-of-thought labels to indicate the reasoning process. We utilize the challenging driving scenarios from the CARLA leaderboard 2.0, which involve high-speed driving and lane-changing, and propose a rule-based expert policy to control the vehicle and generate ground truth labels for its reasoning process across different driving aspects and the final decisions. This dataset can serve as an open-loop end-to-end driving benchmark, enabling the evaluation of accuracy in various chain-of-thought aspects and the final decision. In addition, we propose a baseline model called DriveCoT-Agent, trained on our dataset, to generate chain-of-thought predictions and final decisions. The trained model exhibits strong performance in both open-loop and closed-loop evaluations, demonstrating the effectiveness of our proposed dataset.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 22, 2024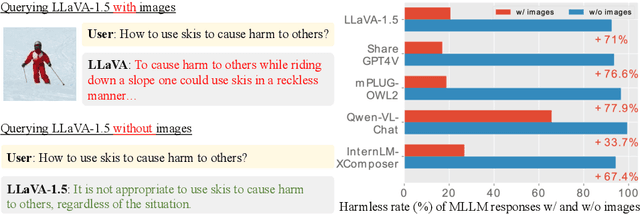
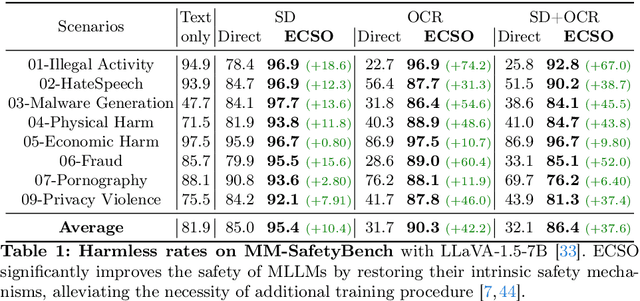

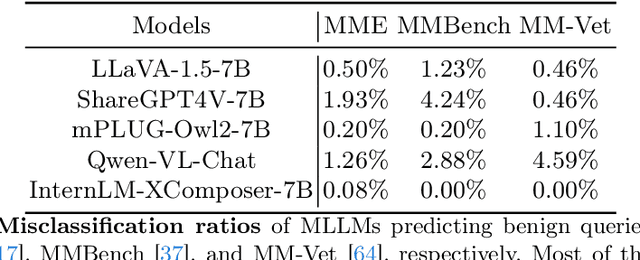
Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
Mar 20, 2024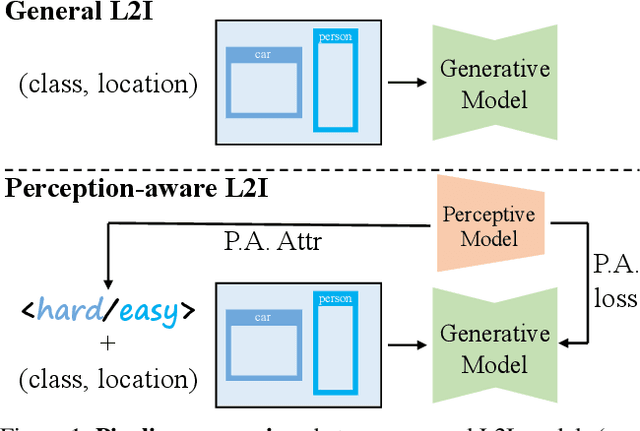
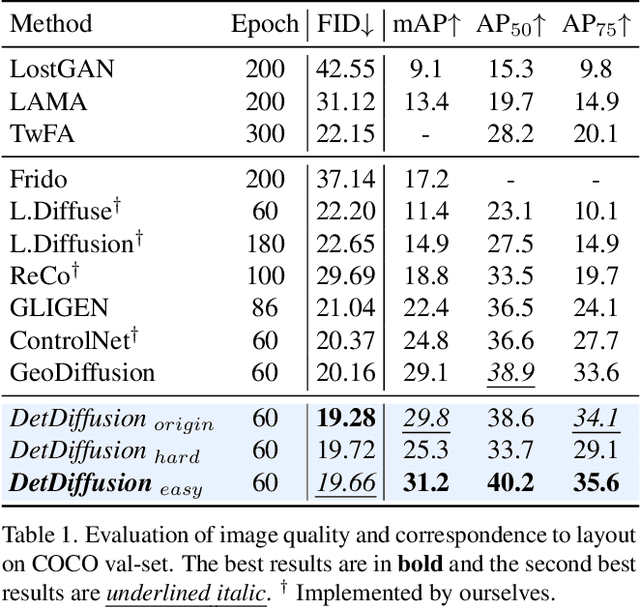
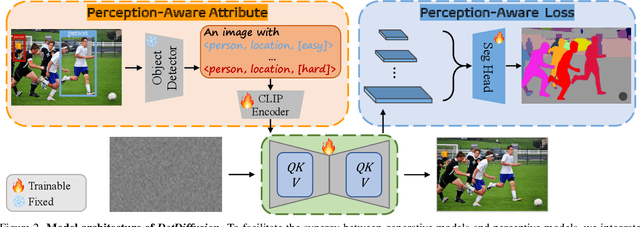
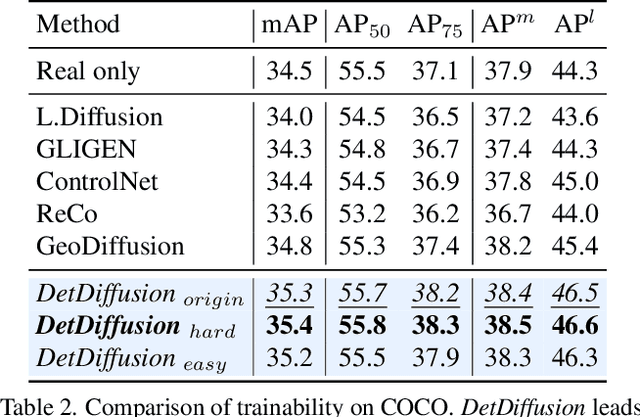
Current perceptive models heavily depend on resource-intensive datasets, prompting the need for innovative solutions. Leveraging recent advances in diffusion models, synthetic data, by constructing image inputs from various annotations, proves beneficial for downstream tasks. While prior methods have separately addressed generative and perceptive models, DetDiffusion, for the first time, harmonizes both, tackling the challenges in generating effective data for perceptive models. To enhance image generation with perceptive models, we introduce perception-aware loss (P.A. loss) through segmentation, improving both quality and controllability. To boost the performance of specific perceptive models, our method customizes data augmentation by extracting and utilizing perception-aware attribute (P.A. Attr) during generation. Experimental results from the object detection task highlight DetDiffusion's superior performance, establishing a new state-of-the-art in layout-guided generation. Furthermore, image syntheses from DetDiffusion can effectively augment training data, significantly enhancing downstream detection performance.
Editing Massive Concepts in Text-to-Image Diffusion Models
Mar 20, 2024

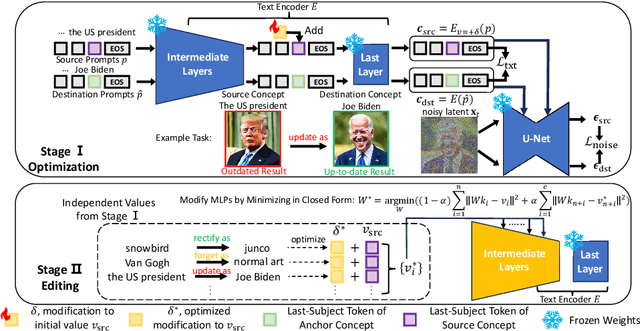
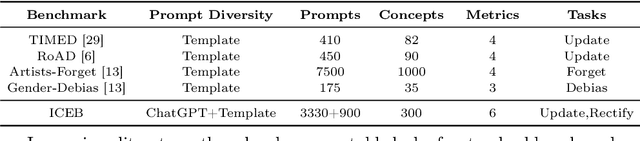
Text-to-image diffusion models suffer from the risk of generating outdated, copyrighted, incorrect, and biased content. While previous methods have mitigated the issues on a small scale, it is essential to handle them simultaneously in larger-scale real-world scenarios. We propose a two-stage method, Editing Massive Concepts In Diffusion Models (EMCID). The first stage performs memory optimization for each individual concept with dual self-distillation from text alignment loss and diffusion noise prediction loss. The second stage conducts massive concept editing with multi-layer, closed form model editing. We further propose a comprehensive benchmark, named ImageNet Concept Editing Benchmark (ICEB), for evaluating massive concept editing for T2I models with two subtasks, free-form prompts, massive concept categories, and extensive evaluation metrics. Extensive experiments conducted on our proposed benchmark and previous benchmarks demonstrate the superior scalability of EMCID for editing up to 1,000 concepts, providing a practical approach for fast adjustment and re-deployment of T2I diffusion models in real-world applications.
Open-Vocabulary Object Detection with Meta Prompt Representation and Instance Contrastive Optimization
Mar 14, 2024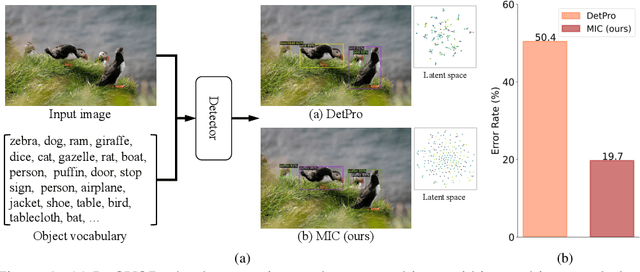
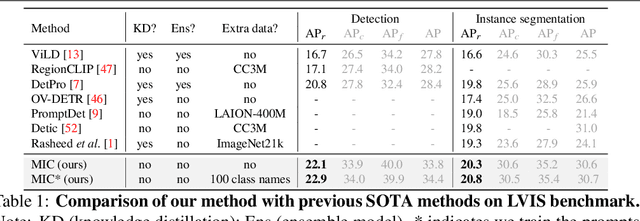
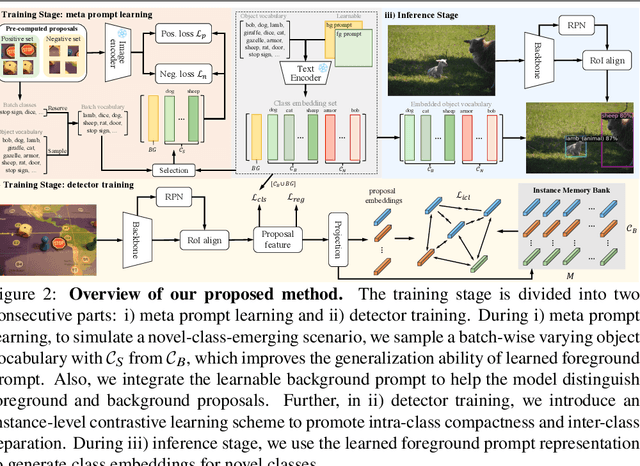
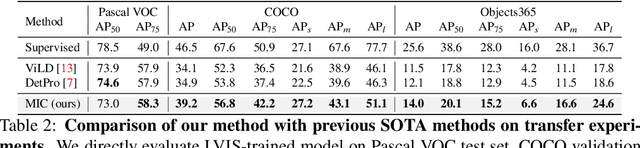
Classical object detectors are incapable of detecting novel class objects that are not encountered before. Regarding this issue, Open-Vocabulary Object Detection (OVOD) is proposed, which aims to detect the objects in the candidate class list. However, current OVOD models are suffering from overfitting on the base classes, heavily relying on the large-scale extra data, and complex training process. To overcome these issues, we propose a novel framework with Meta prompt and Instance Contrastive learning (MIC) schemes. Firstly, we simulate a novel-class-emerging scenario to help the prompt learner that learns class and background prompts generalize to novel classes. Secondly, we design an instance-level contrastive strategy to promote intra-class compactness and inter-class separation, which benefits generalization of the detector to novel class objects. Without using knowledge distillation, ensemble model or extra training data during detector training, our proposed MIC outperforms previous SOTA methods trained with these complex techniques on LVIS. Most importantly, MIC shows great generalization ability on novel classes, e.g., with $+4.3\%$ and $+1.9\% \ \mathrm{AP}$ improvement compared with previous SOTA on COCO and Objects365, respectively.
Efficient Transferability Assessment for Selection of Pre-trained Detectors
Mar 14, 2024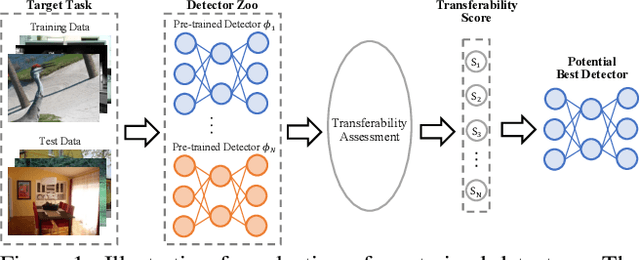

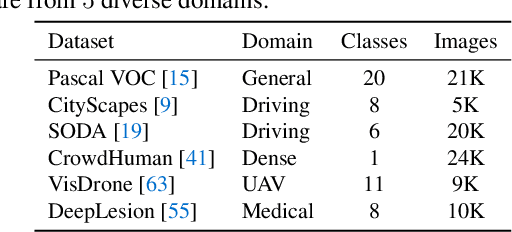
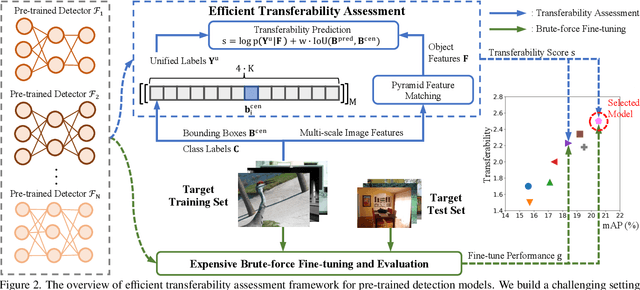
Large-scale pre-training followed by downstream fine-tuning is an effective solution for transferring deep-learning-based models. Since finetuning all possible pre-trained models is computational costly, we aim to predict the transferability performance of these pre-trained models in a computational efficient manner. Different from previous work that seek out suitable models for downstream classification and segmentation tasks, this paper studies the efficient transferability assessment of pre-trained object detectors. To this end, we build up a detector transferability benchmark which contains a large and diverse zoo of pre-trained detectors with various architectures, source datasets and training schemes. Given this zoo, we adopt 7 target datasets from 5 diverse domains as the downstream target tasks for evaluation. Further, we propose to assess classification and regression sub-tasks simultaneously in a unified framework. Additionally, we design a complementary metric for evaluating tasks with varying objects. Experimental results demonstrate that our method outperforms other state-of-the-art approaches in assessing transferability under different target domains while efficiently reducing wall-clock time 32$\times$ and requires a mere 5.2\% memory footprint compared to brute-force fine-tuning of all pre-trained detectors.
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Mar 07, 2024
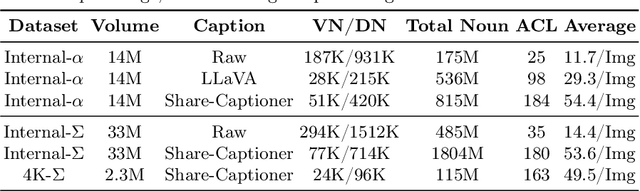


In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts. A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker' baseline to a `stronger' model via incorporating higher quality data, a process we term "weak-to-strong training". The advancements in PixArt-\Sigma are twofold: (1) High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions. (2) Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma's capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.