 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenjie Pi
DetCLIPv3: Towards Versatile Generative Open-vocabulary Object Detection
Apr 14, 2024
Existing open-vocabulary object detectors typically require a predefined set of categories from users, significantly confining their application scenarios. In this paper, we introduce DetCLIPv3, a high-performing detector that excels not only at both open-vocabulary object detection, but also generating hierarchical labels for detected objects. DetCLIPv3 is characterized by three core designs: 1. Versatile model architecture: we derive a robust open-set detection framework which is further empowered with generation ability via the integration of a caption head. 2. High information density data: we develop an auto-annotation pipeline leveraging visual large language model to refine captions for large-scale image-text pairs, providing rich, multi-granular object labels to enhance the training. 3. Efficient training strategy: we employ a pre-training stage with low-resolution inputs that enables the object captioner to efficiently learn a broad spectrum of visual concepts from extensive image-text paired data. This is followed by a fine-tuning stage that leverages a small number of high-resolution samples to further enhance detection performance. With these effective designs, DetCLIPv3 demonstrates superior open-vocabulary detection performance, \eg, our Swin-T backbone model achieves a notable 47.0 zero-shot fixed AP on the LVIS minival benchmark, outperforming GLIPv2, GroundingDINO, and DetCLIPv2 by 18.0/19.6/6.6 AP, respectively. DetCLIPv3 also achieves a state-of-the-art 19.7 AP in dense captioning task on VG dataset, showcasing its strong generative capability.
LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
Mar 28, 2024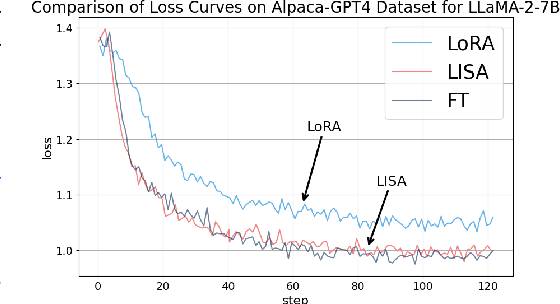
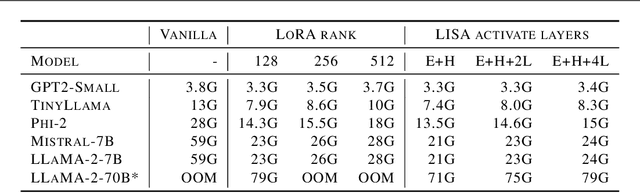

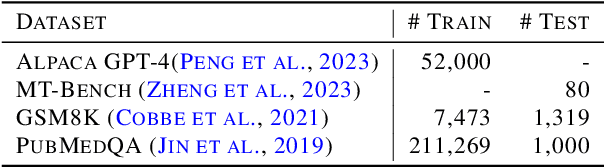
The machine learning community has witnessed impressive advancements since the first appearance of large language models (LLMs), yet their huge memory consumption has become a major roadblock to large-scale training. Parameter Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA) have been proposed to alleviate this problem, but their performance still fails to match full parameter training in most large-scale fine-tuning settings. Attempting to complement this deficiency, we investigate layerwise properties of LoRA on fine-tuning tasks and observe an uncommon skewness of weight norms across different layers. Utilizing this key observation, a surprisingly simple training strategy is discovered, which outperforms both LoRA and full parameter training in a wide range of settings with memory costs as low as LoRA. We name it Layerwise Importance Sampled AdamW (LISA), a promising alternative for LoRA, which applies the idea of importance sampling to different layers in LLMs and randomly freeze most middle layers during optimization. Experimental results show that with similar or less GPU memory consumption, LISA surpasses LoRA or even full parameter tuning in downstream fine-tuning tasks, where LISA consistently outperforms LoRA by over $11\%$-$37\%$ in terms of MT-Bench scores. On large models, specifically LLaMA-2-70B, LISA achieves on-par or better performance than LoRA on MT-Bench, GSM8K, and PubMedQA, demonstrating its effectiveness across different domains.
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Mar 13, 2024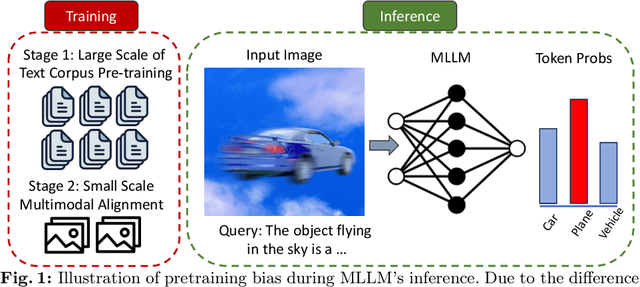


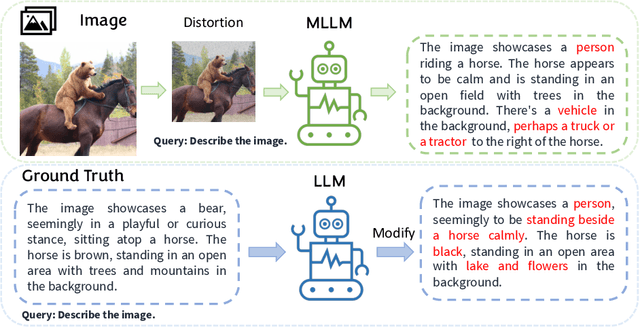
Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a "preference" for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
GradSafe: Detecting Unsafe Prompts for LLMs via Safety-Critical Gradient Analysis
Feb 21, 2024Large Language Models (LLMs) face threats from unsafe prompts. Existing methods for detecting unsafe prompts are primarily online moderation APIs or finetuned LLMs. These strategies, however, often require extensive and resource-intensive data collection and training processes. In this study, we propose GradSafe, which effectively detects unsafe prompts by scrutinizing the gradients of safety-critical parameters in LLMs. Our methodology is grounded in a pivotal observation: the gradients of an LLM's loss for unsafe prompts paired with compliance response exhibit similar patterns on certain safety-critical parameters. In contrast, safe prompts lead to markedly different gradient patterns. Building on this observation, GradSafe analyzes the gradients from prompts (paired with compliance responses) to accurately detect unsafe prompts. We show that GradSafe, applied to Llama-2 without further training, outperforms Llama Guard, despite its extensive finetuning with a large dataset, in detecting unsafe prompts. This superior performance is consistent across both zero-shot and adaptation scenarios, as evidenced by our evaluations on the ToxicChat and XSTest. The source code is available at https://github.com/xyq7/GradSafe.
The Instinctive Bias: Spurious Images lead to Hallucination in MLLMs
Feb 06, 2024Large language models (LLMs) have recently experienced remarkable progress, where the advent of multi-modal large language models (MLLMs) has endowed LLMs with visual capabilities, leading to impressive performances in various multi-modal tasks. However, those powerful MLLMs such as GPT-4V still fail spectacularly when presented with certain image and text inputs. In this paper, we identify a typical class of inputs that baffles MLLMs, which consist of images that are highly relevant but inconsistent with answers, causing MLLMs to suffer from hallucination. To quantify the effect, we propose CorrelationQA, the first benchmark that assesses the hallucination level given spurious images. This benchmark contains 7,308 text-image pairs across 13 categories. Based on the proposed CorrelationQA, we conduct a thorough analysis on 9 mainstream MLLMs, illustrating that they universally suffer from this instinctive bias to varying degrees. We hope that our curated benchmark and evaluation results aid in better assessments of the MLLMs' robustness in the presence of misleading images. The resource is available in https://github.com/MasaiahHan/CorrelationQA.
SceMQA: A Scientific College Entrance Level Multimodal Question Answering Benchmark
Feb 06, 2024The paper introduces SceMQA, a novel benchmark for scientific multimodal question answering at the college entrance level. It addresses a critical educational phase often overlooked in existing benchmarks, spanning high school to pre-college levels. SceMQA focuses on core science subjects including Mathematics, Physics, Chemistry, and Biology. It features a blend of multiple-choice and free-response formats, ensuring a comprehensive evaluation of AI models' abilities. Additionally, our benchmark provides specific knowledge points for each problem and detailed explanations for each answer. SceMQA also uniquely presents problems with identical contexts but varied questions to facilitate a more thorough and accurate assessment of reasoning capabilities. In the experiment, we evaluate both open-source and close-source state-of-the-art Multimodal Large Language Models (MLLMs), across various experimental settings. The results show that further research and development are needed in developing more capable MLLM, as highlighted by only 50% to 60% accuracy achieved by the strongest models. Our benchmark and analysis will be available at https://scemqa.github.io/
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Jan 17, 2024The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. We delve into the novel challenge of defending MLLMs against such attacks. We discovered that images act as a "foreign language" that is not considered during alignment, which can make MLLMs prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover the possible scenarios. This vulnerability is exacerbated by the fact that open-source MLLMs are predominantly fine-tuned on limited image-text pairs that is much less than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during explicit alignment tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy combining a lightweight harm detector and a response detoxifier. The harm detector's role is to identify potentially harmful outputs from the MLLM, while the detoxifier corrects these outputs to ensure the response stipulates to the safety standards. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the model's overall performance. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.
G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model
Dec 18, 2023Large language models (LLMs) have shown remarkable proficiency in human-level reasoning and generation capabilities, which encourages extensive research on their application in mathematical problem solving. However, current work has been largely focused on text-based mathematical problems, with limited investigation in problems involving geometric information. Addressing this gap, we aim to enable LLMs to solve geometric problems by understanding image input. We first analyze the limitations of current Multimodal Large Language Models (MLLMs) in this area: they struggle to accurately comprehending basic geometric elements and their relationships. To overcome these challenges, we take advantage of the unique characteristics of geometric problems (such as unique geometric logical form, and geometric scalability) and the capacity of the textual LLMs to build an enriched multimodal geometry dataset based on existing data. The augmented dataset, Geo170K, contains more than 170K geometric image-caption and question-answer pairs. Utilizing our constructed Geo170K dataset, we develop G-LLaVA, which demonstrates exceptional performance in solving geometric problems, significantly outperforming GPT-4-V on the MathVista benchmark with only 7B parameters.
PerceptionGPT: Effectively Fusing Visual Perception into LLM
Nov 11, 2023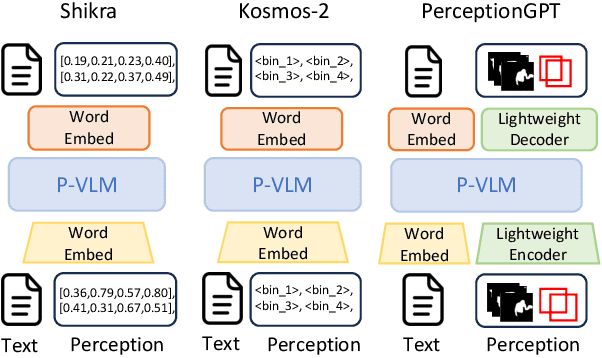
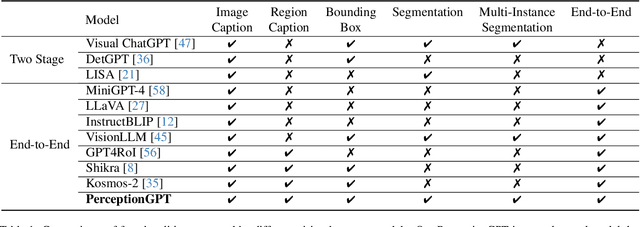
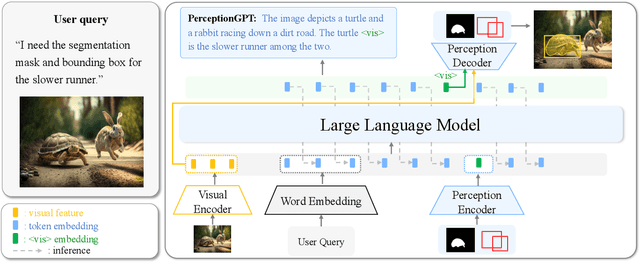
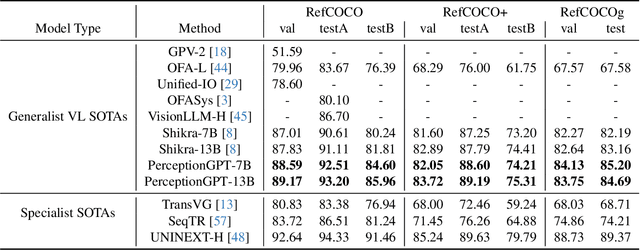
The integration of visual inputs with large language models (LLMs) has led to remarkable advancements in multi-modal capabilities, giving rise to visual large language models (VLLMs). However, effectively harnessing VLLMs for intricate visual perception tasks remains a challenge. In this paper, we present a novel end-to-end framework named PerceptionGPT, which efficiently and effectively equips the VLLMs with visual perception abilities by leveraging the representation power of LLMs' token embedding. Our proposed method treats the token embedding of the LLM as the carrier of spatial information, then leverage lightweight visual task encoders and decoders to perform visual perception tasks (e.g., detection, segmentation). Our approach significantly alleviates the training difficulty suffered by previous approaches that formulate the visual outputs as discrete tokens, and enables achieving superior performance with fewer trainable parameters, less training data and shorted training time. Moreover, as only one token embedding is required to decode the visual outputs, the resulting sequence length during inference is significantly reduced. Consequently, our approach enables accurate and flexible representations, seamless integration of visual perception tasks, and efficient handling of a multiple of visual outputs. We validate the effectiveness and efficiency of our approach through extensive experiments. The results demonstrate significant improvements over previous methods with much fewer trainable parameters and GPU hours, which facilitates future research in enabling LLMs with visual perception abilities.
Speciality vs Generality: An Empirical Study on Catastrophic Forgetting in Fine-tuning Foundation Models
Sep 12, 2023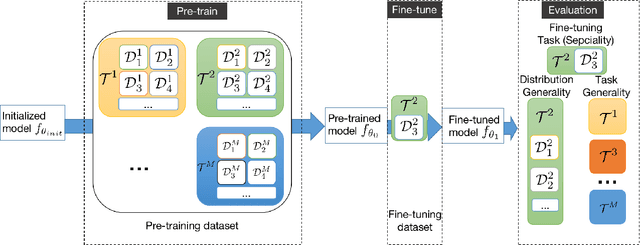
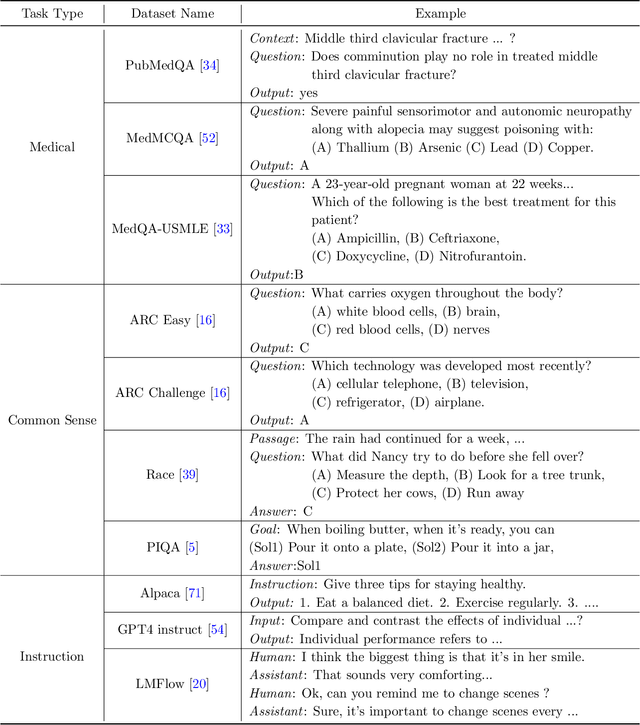


Foundation models, including Vision Language Models (VLMs) and Large Language Models (LLMs), possess the $generality$ to handle diverse distributions and tasks, which stems from their extensive pre-training datasets. The fine-tuning of foundation models is a common practice to enhance task performance or align the model's behavior with human expectations, allowing them to gain $speciality$. However, the small datasets used for fine-tuning may not adequately cover the diverse distributions and tasks encountered during pre-training. Consequently, the pursuit of speciality during fine-tuning can lead to a loss of {generality} in the model, which is related to catastrophic forgetting (CF) in deep learning. In this study, we demonstrate this phenomenon in both VLMs and LLMs. For instance, fine-tuning VLMs like CLIP on ImageNet results in a loss of generality in handling diverse distributions, and fine-tuning LLMs like Galactica in the medical domain leads to a loss in following instructions and common sense. To address the trade-off between the speciality and generality, we investigate multiple regularization methods from continual learning, the weight averaging method (Wise-FT) from out-of-distributional (OOD) generalization, which interpolates parameters between pre-trained and fine-tuned models, and parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA). Our findings show that both continual learning and Wise-ft methods effectively mitigate the loss of generality, with Wise-FT exhibiting the strongest performance in balancing speciality and generality.