 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianyang Han
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Mar 13, 2024
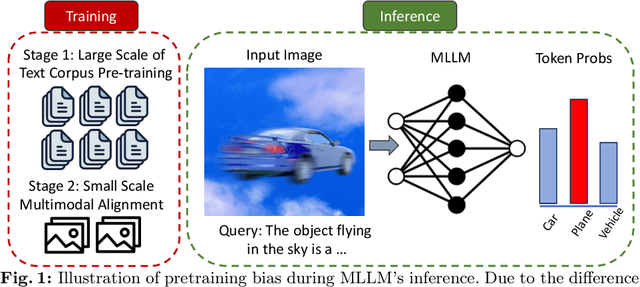


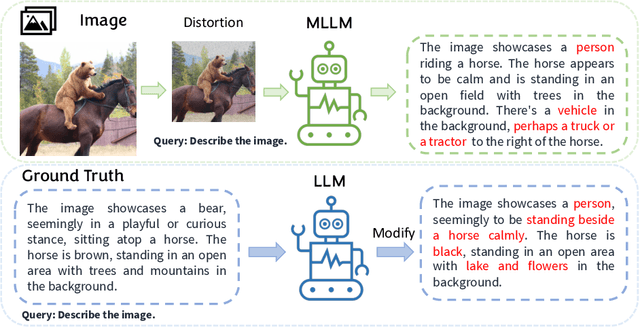
Multimodal Large Language Models (MLLMs) excel in generating responses based on visual inputs. However, they often suffer from a bias towards generating responses similar to their pretraining corpus, overshadowing the importance of visual information. We treat this bias as a "preference" for pretraining statistics, which hinders the model's grounding in visual input. To mitigate this issue, we propose Bootstrapped Preference Optimization (BPO), which conducts preference learning with datasets containing negative responses bootstrapped from the model itself. Specifically, we propose the following two strategies: 1) using distorted image inputs to the MLLM for eliciting responses that contain signified pretraining bias; 2) leveraging text-based LLM to explicitly inject erroneous but common elements into the original response. Those undesirable responses are paired with original annotated responses from the datasets to construct the preference dataset, which is subsequently utilized to perform preference learning. Our approach effectively suppresses pretrained LLM bias, enabling enhanced grounding in visual inputs. Extensive experimentation demonstrates significant performance improvements across multiple benchmarks, advancing the state-of-the-art in multimodal conversational systems.
The Instinctive Bias: Spurious Images lead to Hallucination in MLLMs
Feb 06, 2024Large language models (LLMs) have recently experienced remarkable progress, where the advent of multi-modal large language models (MLLMs) has endowed LLMs with visual capabilities, leading to impressive performances in various multi-modal tasks. However, those powerful MLLMs such as GPT-4V still fail spectacularly when presented with certain image and text inputs. In this paper, we identify a typical class of inputs that baffles MLLMs, which consist of images that are highly relevant but inconsistent with answers, causing MLLMs to suffer from hallucination. To quantify the effect, we propose CorrelationQA, the first benchmark that assesses the hallucination level given spurious images. This benchmark contains 7,308 text-image pairs across 13 categories. Based on the proposed CorrelationQA, we conduct a thorough analysis on 9 mainstream MLLMs, illustrating that they universally suffer from this instinctive bias to varying degrees. We hope that our curated benchmark and evaluation results aid in better assessments of the MLLMs' robustness in the presence of misleading images. The resource is available in https://github.com/MasaiahHan/CorrelationQA.
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Jan 17, 2024The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. We delve into the novel challenge of defending MLLMs against such attacks. We discovered that images act as a "foreign language" that is not considered during alignment, which can make MLLMs prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover the possible scenarios. This vulnerability is exacerbated by the fact that open-source MLLMs are predominantly fine-tuned on limited image-text pairs that is much less than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during explicit alignment tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy combining a lightweight harm detector and a response detoxifier. The harm detector's role is to identify potentially harmful outputs from the MLLM, while the detoxifier corrects these outputs to ensure the response stipulates to the safety standards. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the model's overall performance. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.