 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenwen Liang
Defending Jailbreak Prompts via In-Context Adversarial Game
Feb 20, 2024
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.
Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples
Feb 12, 2024Automatic taxonomy induction is crucial for web search, recommendation systems, and question answering. Manual curation of taxonomies is expensive in terms of human effort, making automatic taxonomy construction highly desirable. In this work, we introduce Chain-of-Layer which is an in-context learning framework designed to induct taxonomies from a given set of entities. Chain-of-Layer breaks down the task into selecting relevant candidate entities in each layer and gradually building the taxonomy from top to bottom. To minimize errors, we introduce the Ensemble-based Ranking Filter to reduce the hallucinated content generated at each iteration. Through extensive experiments, we demonstrate that Chain-of-Layer achieves state-of-the-art performance on four real-world benchmarks.
SceMQA: A Scientific College Entrance Level Multimodal Question Answering Benchmark
Feb 06, 2024The paper introduces SceMQA, a novel benchmark for scientific multimodal question answering at the college entrance level. It addresses a critical educational phase often overlooked in existing benchmarks, spanning high school to pre-college levels. SceMQA focuses on core science subjects including Mathematics, Physics, Chemistry, and Biology. It features a blend of multiple-choice and free-response formats, ensuring a comprehensive evaluation of AI models' abilities. Additionally, our benchmark provides specific knowledge points for each problem and detailed explanations for each answer. SceMQA also uniquely presents problems with identical contexts but varied questions to facilitate a more thorough and accurate assessment of reasoning capabilities. In the experiment, we evaluate both open-source and close-source state-of-the-art Multimodal Large Language Models (MLLMs), across various experimental settings. The results show that further research and development are needed in developing more capable MLLM, as highlighted by only 50% to 60% accuracy achieved by the strongest models. Our benchmark and analysis will be available at https://scemqa.github.io/
Manipulating Predictions over Discrete Inputs in Machine Teaching
Jan 31, 2024Machine teaching often involves the creation of an optimal (typically minimal) dataset to help a model (referred to as the `student') achieve specific goals given by a teacher. While abundant in the continuous domain, the studies on the effectiveness of machine teaching in the discrete domain are relatively limited. This paper focuses on machine teaching in the discrete domain, specifically on manipulating student models' predictions based on the goals of teachers via changing the training data efficiently. We formulate this task as a combinatorial optimization problem and solve it by proposing an iterative searching algorithm. Our algorithm demonstrates significant numerical merit in the scenarios where a teacher attempts at correcting erroneous predictions to improve the student's models, or maliciously manipulating the model to misclassify some specific samples to the target class aligned with his personal profits. Experimental results show that our proposed algorithm can have superior performance in effectively and efficiently manipulating the predictions of the model, surpassing conventional baselines.
MinT: Boosting Generalization in Mathematical Reasoning via Multi-View Fine-Tuning
Jul 16, 2023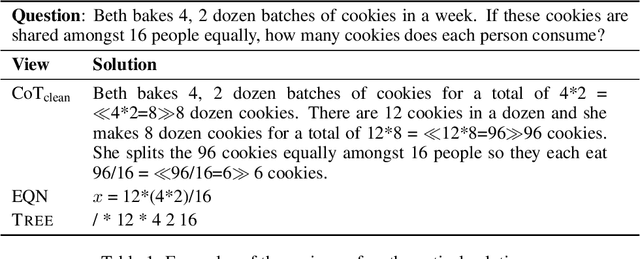
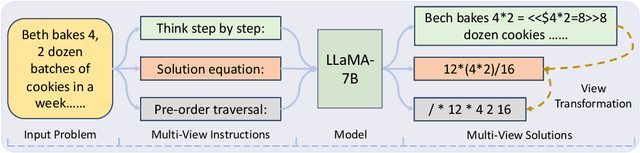
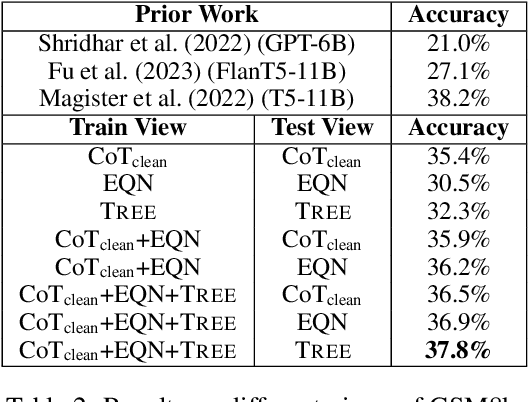
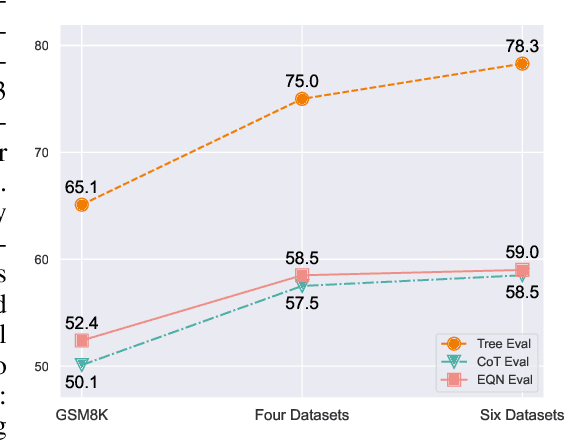
Reasoning in mathematical domains remains a significant challenge for relatively small language models (LMs). Many current methods focus on specializing LMs in mathematical reasoning and rely heavily on knowledge distillation from powerful but inefficient large LMs (LLMs). In this work, we explore a new direction that avoids over-reliance on LLM teachers, introducing a multi-view fine-tuning method that efficiently exploits existing mathematical problem datasets with diverse annotation styles. Our approach uniquely considers the various annotation formats as different "views" and leverages them in training the model. By postpending distinct instructions to input questions, models can learn to generate solutions in diverse formats in a flexible manner. Experimental results show that our strategy enables a LLaMA-7B model to outperform prior approaches that utilize knowledge distillation, as well as carefully established baselines. Additionally, the proposed method grants the models promising generalization ability across various views and datasets, and the capability to learn from inaccurate or incomplete noisy data. We hope our multi-view training paradigm could inspire future studies in other machine reasoning domains.
What indeed can GPT models do in chemistry? A comprehensive benchmark on eight tasks
May 27, 2023
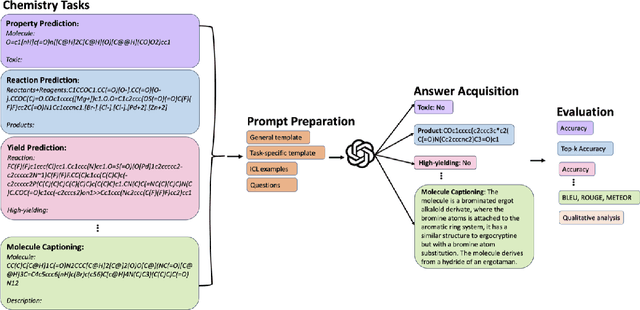
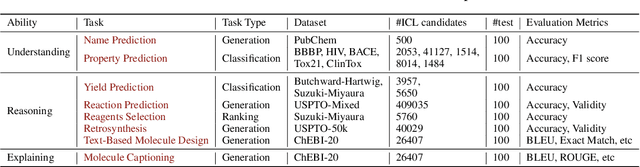

Large Language Models (LLMs) with strong abilities in natural language processing tasks have emerged and have been rapidly applied in various kinds of areas such as science, finance and software engineering. However, the capability of LLMs to advance the field of chemistry remains unclear. In this paper,we establish a comprehensive benchmark containing 8 practical chemistry tasks, including 1) name prediction, 2) property prediction, 3) yield prediction, 4) reaction prediction, 5) retrosynthesis (prediction of reactants from products), 6)text-based molecule design, 7) molecule captioning, and 8) reagent selection. Our analysis draws on widely recognized datasets including BBBP, Tox21, PubChem, USPTO, and ChEBI, facilitating a broad exploration of the capacities of LLMs within the context of practical chemistry. Three GPT models (GPT-4, GPT-3.5,and Davinci-003) are evaluated for each chemistry task in zero-shot and few-shot in-context learning settings with carefully selected demonstration examples and specially crafted prompts. The key results of our investigation are 1) GPT-4 outperforms the other two models among the three evaluated; 2) GPT models exhibit less competitive performance in tasks demanding precise understanding of molecular SMILES representation, such as reaction prediction and retrosynthesis;3) GPT models demonstrate strong capabilities in text-related explanation tasks such as molecule captioning; and 4) GPT models exhibit comparable or better performance to classical machine learning models when applied to chemical problems that can be transformed into classification or ranking tasks, such as property prediction, and yield prediction.
Improving Language Models via Plug-and-Play Retrieval Feedback
May 23, 2023
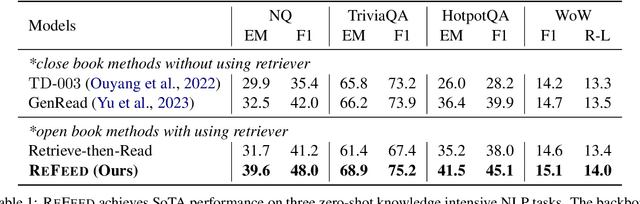


Large language models (LLMs) exhibit remarkable performance across various NLP tasks. However, they often generate incorrect or hallucinated information, which hinders their practical applicability in real-world scenarios. Human feedback has been shown to effectively enhance the factuality and quality of generated content, addressing some of these limitations. However, this approach is resource-intensive, involving manual input and supervision, which can be time-consuming and expensive. Moreover, it cannot be provided during inference, further limiting its practical utility in dynamic and interactive applications. In this paper, we introduce ReFeed, a novel pipeline designed to enhance LLMs by providing automatic retrieval feedback in a plug-and-play framework without the need for expensive fine-tuning. ReFeed first generates initial outputs, then utilizes a retrieval model to acquire relevant information from large document collections, and finally incorporates the retrieved information into the in-context demonstration for output refinement, thereby addressing the limitations of LLMs in a more efficient and cost-effective manner. Experiments on four knowledge-intensive benchmark datasets demonstrate our proposed ReFeed could improve over +6.0% under zero-shot setting and +2.5% under few-shot setting, compared to baselines without using retrieval feedback.
Let GPT be a Math Tutor: Teaching Math Word Problem Solvers with Customized Exercise Generation
May 22, 2023



In this paper, we present a novel approach for distilling math word problem solving capabilities from large language models (LLMs) into smaller, more efficient student models. Our approach is designed to consider the student model's weaknesses and foster a tailored learning experience by generating targeted exercises aligned with educational science principles, such as knowledge tracing and personalized learning. Concretely, we let GPT-3 be a math tutor and run two steps iteratively: 1) assessing the student model's current learning status on a GPT-generated exercise book, and 2) improving the student model by training it with tailored exercise samples generated by GPT-3. Experimental results reveal that our approach outperforms LLMs (e.g., GPT-3 and PaLM) in accuracy across three distinct benchmarks while employing significantly fewer parameters. Furthermore, we provide a comprehensive analysis of the various components within our methodology to substantiate their efficacy.
Analogical Math Word Problems Solving with Enhanced Problem-Solution Association
Dec 01, 2022



Math word problem (MWP) solving is an important task in question answering which requires human-like reasoning ability. Analogical reasoning has long been used in mathematical education, as it enables students to apply common relational structures of mathematical situations to solve new problems. In this paper, we propose to build a novel MWP solver by leveraging analogical MWPs, which advance the solver's generalization ability across different kinds of MWPs. The key idea, named analogy identification, is to associate the analogical MWP pairs in a latent space, i.e., encoding an MWP close to another analogical MWP, while moving away from the non-analogical ones. Moreover, a solution discriminator is integrated into the MWP solver to enhance the association between the representations of MWPs and their true solutions. The evaluation results verify that our proposed analogical learning strategy promotes the performance of MWP-BERT on Math23k over the state-of-the-art model Generate2Rank, with 5 times fewer parameters in the encoder. We also find that our model has a stronger generalization ability in solving difficult MWPs due to the analogical learning from easy MWPs.
Generalizing Math Word Problem Solvers via Solution Diversification
Dec 01, 2022



Current math word problem (MWP) solvers are usually Seq2Seq models trained by the (one-problem; one-solution) pairs, each of which is made of a problem description and a solution showing reasoning flow to get the correct answer. However, one MWP problem naturally has multiple solution equations. The training of an MWP solver with (one-problem; one-solution) pairs excludes other correct solutions, and thus limits the generalizability of the MWP solver. One feasible solution to this limitation is to augment multiple solutions to a given problem. However, it is difficult to collect diverse and accurate augment solutions through human efforts. In this paper, we design a new training framework for an MWP solver by introducing a solution buffer and a solution discriminator. The buffer includes solutions generated by an MWP solver to encourage the training data diversity. The discriminator controls the quality of buffered solutions to participate in training. Our framework is flexibly applicable to a wide setting of fully, semi-weakly and weakly supervised training for all Seq2Seq MWP solvers. We conduct extensive experiments on a benchmark dataset Math23k and a new dataset named Weak12k, and show that our framework improves the performance of various MWP solvers under different settings by generating correct and diverse solutions.