 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhichun Guo
You do not have to train Graph Neural Networks at all on text-attributed graphs
Apr 17, 2024
Graph structured data, specifically text-attributed graphs (TAG), effectively represent relationships among varied entities. Such graphs are essential for semi-supervised node classification tasks. Graph Neural Networks (GNNs) have emerged as a powerful tool for handling this graph-structured data. Although gradient descent is commonly utilized for training GNNs for node classification, this study ventures into alternative methods, eliminating the iterative optimization processes. We introduce TrainlessGNN, a linear GNN model capitalizing on the observation that text encodings from the same class often cluster together in a linear subspace. This model constructs a weight matrix to represent each class's node attribute subspace, offering an efficient approach to semi-supervised node classification on TAG. Extensive experiments reveal that our trainless models can either match or even surpass their conventionally trained counterparts, demonstrating the possibility of refraining from gradient descent in certain configurations.
CORE: Data Augmentation for Link Prediction via Information Bottleneck
Apr 17, 2024Link prediction (LP) is a fundamental task in graph representation learning, with numerous applications in diverse domains. However, the generalizability of LP models is often compromised due to the presence of noisy or spurious information in graphs and the inherent incompleteness of graph data. To address these challenges, we draw inspiration from the Information Bottleneck principle and propose a novel data augmentation method, COmplete and REduce (CORE) to learn compact and predictive augmentations for LP models. In particular, CORE aims to recover missing edges in graphs while simultaneously removing noise from the graph structures, thereby enhancing the model's robustness and performance. Extensive experiments on multiple benchmark datasets demonstrate the applicability and superiority of CORE over state-of-the-art methods, showcasing its potential as a leading approach for robust LP in graph representation learning.
Improving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024



Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
Node Duplication Improves Cold-start Link Prediction
Feb 15, 2024Graph Neural Networks (GNNs) are prominent in graph machine learning and have shown state-of-the-art performance in Link Prediction (LP) tasks. Nonetheless, recent studies show that GNNs struggle to produce good results on low-degree nodes despite their overall strong performance. In practical applications of LP, like recommendation systems, improving performance on low-degree nodes is critical, as it amounts to tackling the cold-start problem of improving the experiences of users with few observed interactions. In this paper, we investigate improving GNNs' LP performance on low-degree nodes while preserving their performance on high-degree nodes and propose a simple yet surprisingly effective augmentation technique called NodeDup. Specifically, NodeDup duplicates low-degree nodes and creates links between nodes and their own duplicates before following the standard supervised LP training scheme. By leveraging a ''multi-view'' perspective for low-degree nodes, NodeDup shows significant LP performance improvements on low-degree nodes without compromising any performance on high-degree nodes. Additionally, as a plug-and-play augmentation module, NodeDup can be easily applied to existing GNNs with very light computational cost. Extensive experiments show that NodeDup achieves 38.49%, 13.34%, and 6.76% improvements on isolated, low-degree, and warm nodes, respectively, on average across all datasets compared to GNNs and state-of-the-art cold-start methods.
Universal Link Predictor By In-Context Learning on Graphs
Feb 15, 2024Link prediction is a crucial task in graph machine learning, where the goal is to infer missing or future links within a graph. Traditional approaches leverage heuristic methods based on widely observed connectivity patterns, offering broad applicability and generalizability without the need for model training. Despite their utility, these methods are limited by their reliance on human-derived heuristics and lack the adaptability of data-driven approaches. Conversely, parametric link predictors excel in automatically learning the connectivity patterns from data and achieving state-of-the-art but fail short to directly transfer across different graphs. Instead, it requires the cost of extensive training and hyperparameter optimization to adapt to the target graph. In this work, we introduce the Universal Link Predictor (UniLP), a novel model that combines the generalizability of heuristic approaches with the pattern learning capabilities of parametric models. UniLP is designed to autonomously identify connectivity patterns across diverse graphs, ready for immediate application to any unseen graph dataset without targeted training. We address the challenge of conflicting connectivity patterns-arising from the unique distributions of different graphs-through the implementation of In-context Learning (ICL). This approach allows UniLP to dynamically adjust to various target graphs based on contextual demonstrations, thereby avoiding negative transfer. Through rigorous experimentation, we demonstrate UniLP's effectiveness in adapting to new, unseen graphs at test time, showcasing its ability to perform comparably or even outperform parametric models that have been finetuned for specific datasets. Our findings highlight UniLP's potential to set a new standard in link prediction, combining the strengths of heuristic and parametric methods in a single, versatile framework.
Pure Message Passing Can Estimate Common Neighbor for Link Prediction
Sep 02, 2023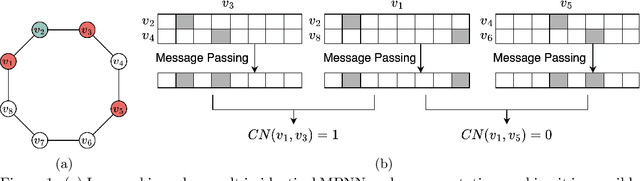
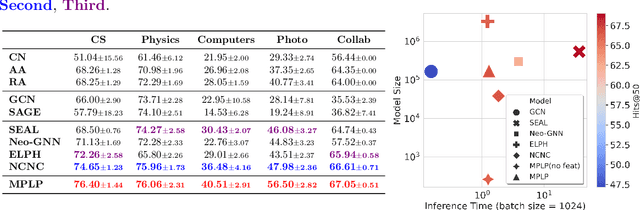
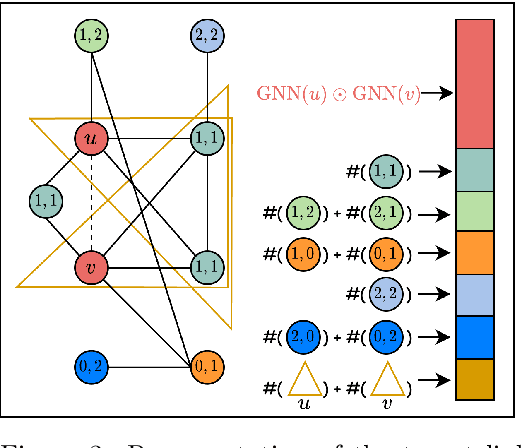
Message Passing Neural Networks (MPNNs) have emerged as the {\em de facto} standard in graph representation learning. However, when it comes to link prediction, they often struggle, surpassed by simple heuristics such as Common Neighbor (CN). This discrepancy stems from a fundamental limitation: while MPNNs excel in node-level representation, they stumble with encoding the joint structural features essential to link prediction, like CN. To bridge this gap, we posit that, by harnessing the orthogonality of input vectors, pure message-passing can indeed capture joint structural features. Specifically, we study the proficiency of MPNNs in approximating CN heuristics. Based on our findings, we introduce the Message Passing Link Predictor (MPLP), a novel link prediction model. MPLP taps into quasi-orthogonal vectors to estimate link-level structural features, all while preserving the node-level complexities. Moreover, our approach demonstrates that leveraging message-passing to capture structural features could offset MPNNs' expressiveness limitations at the expense of estimation variance. We conduct experiments on benchmark datasets from various domains, where our method consistently outperforms the baseline methods.
What indeed can GPT models do in chemistry? A comprehensive benchmark on eight tasks
May 27, 2023
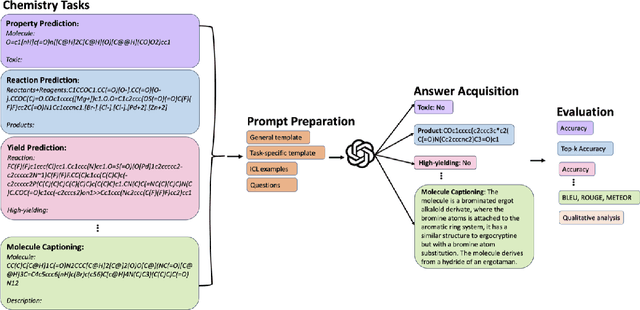
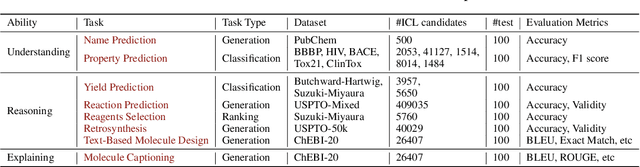

Large Language Models (LLMs) with strong abilities in natural language processing tasks have emerged and have been rapidly applied in various kinds of areas such as science, finance and software engineering. However, the capability of LLMs to advance the field of chemistry remains unclear. In this paper,we establish a comprehensive benchmark containing 8 practical chemistry tasks, including 1) name prediction, 2) property prediction, 3) yield prediction, 4) reaction prediction, 5) retrosynthesis (prediction of reactants from products), 6)text-based molecule design, 7) molecule captioning, and 8) reagent selection. Our analysis draws on widely recognized datasets including BBBP, Tox21, PubChem, USPTO, and ChEBI, facilitating a broad exploration of the capacities of LLMs within the context of practical chemistry. Three GPT models (GPT-4, GPT-3.5,and Davinci-003) are evaluated for each chemistry task in zero-shot and few-shot in-context learning settings with carefully selected demonstration examples and specially crafted prompts. The key results of our investigation are 1) GPT-4 outperforms the other two models among the three evaluated; 2) GPT models exhibit less competitive performance in tasks demanding precise understanding of molecular SMILES representation, such as reaction prediction and retrosynthesis;3) GPT models demonstrate strong capabilities in text-related explanation tasks such as molecule captioning; and 4) GPT models exhibit comparable or better performance to classical machine learning models when applied to chemical problems that can be transformed into classification or ranking tasks, such as property prediction, and yield prediction.
FakeEdge: Alleviate Dataset Shift in Link Prediction
Dec 03, 2022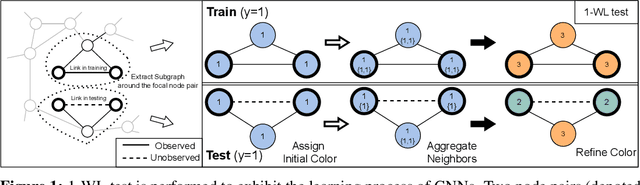
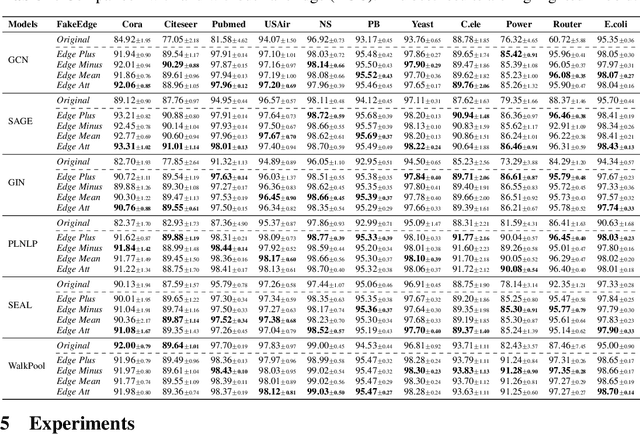
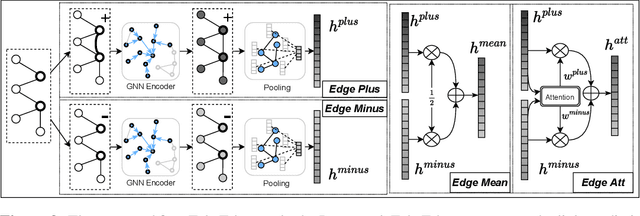

Link prediction is a crucial problem in graph-structured data. Due to the recent success of graph neural networks (GNNs), a variety of GNN-based models were proposed to tackle the link prediction task. Specifically, GNNs leverage the message passing paradigm to obtain node representation, which relies on link connectivity. However, in a link prediction task, links in the training set are always present while ones in the testing set are not yet formed, resulting in a discrepancy of the connectivity pattern and bias of the learned representation. It leads to a problem of dataset shift which degrades the model performance. In this paper, we first identify the dataset shift problem in the link prediction task and provide theoretical analyses on how existing link prediction methods are vulnerable to it. We then propose FakeEdge, a model-agnostic technique, to address the problem by mitigating the graph topological gap between training and testing sets. Extensive experiments demonstrate the applicability and superiority of FakeEdge on multiple datasets across various domains.
Link Prediction with Non-Contrastive Learning
Nov 25, 2022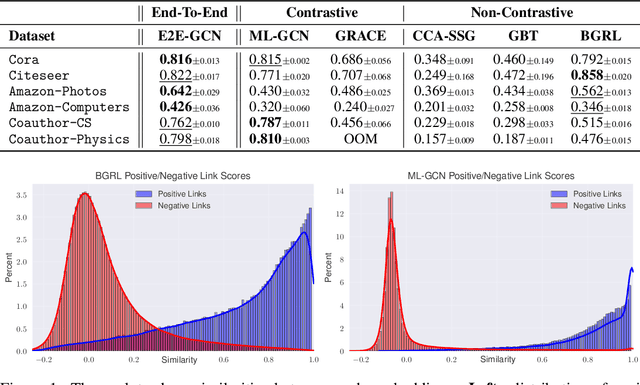

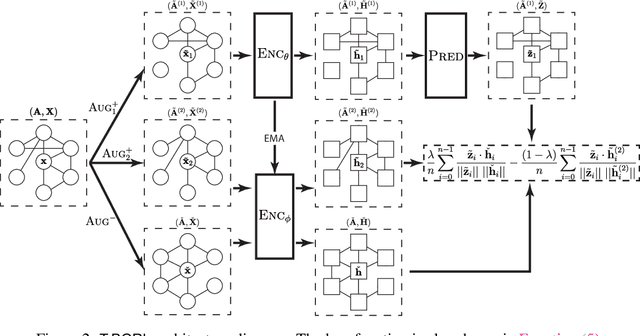

A recent focal area in the space of graph neural networks (GNNs) is graph self-supervised learning (SSL), which aims to derive useful node representations without labeled data. Notably, many state-of-the-art graph SSL methods are contrastive methods, which use a combination of positive and negative samples to learn node representations. Owing to challenges in negative sampling (slowness and model sensitivity), recent literature introduced non-contrastive methods, which instead only use positive samples. Though such methods have shown promising performance in node-level tasks, their suitability for link prediction tasks, which are concerned with predicting link existence between pairs of nodes (and have broad applicability to recommendation systems contexts) is yet unexplored. In this work, we extensively evaluate the performance of existing non-contrastive methods for link prediction in both transductive and inductive settings. While most existing non-contrastive methods perform poorly overall, we find that, surprisingly, BGRL generally performs well in transductive settings. However, it performs poorly in the more realistic inductive settings where the model has to generalize to links to/from unseen nodes. We find that non-contrastive models tend to overfit to the training graph and use this analysis to propose T-BGRL, a novel non-contrastive framework that incorporates cheap corruptions to improve the generalization ability of the model. This simple modification strongly improves inductive performance in 5/6 of our datasets, with up to a 120% improvement in Hits@50--all with comparable speed to other non-contrastive baselines and up to 14x faster than the best-performing contrastive baseline. Our work imparts interesting findings about non-contrastive learning for link prediction and paves the way for future researchers to further expand upon this area.
Linkless Link Prediction via Relational Distillation
Oct 19, 2022
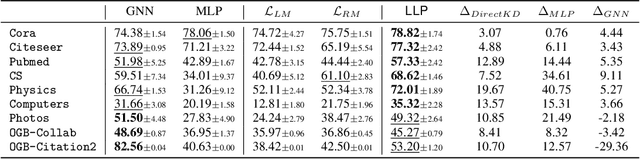

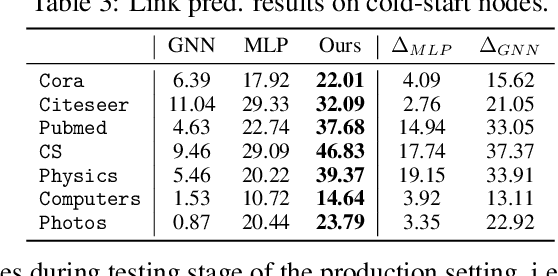
Graph Neural Networks (GNNs) have been widely used on graph data and have shown exceptional performance in the task of link prediction. Despite their effectiveness, GNNs often suffer from high latency due to non-trivial neighborhood data dependency in practical deployments. To address this issue, researchers have proposed methods based on knowledge distillation (KD) to transfer the knowledge from teacher GNNs to student MLPs, which are known to be efficient even with industrial scale data, and have shown promising results on node classification. Nonetheless, using KD to accelerate link prediction is still unexplored. In this work, we start with exploring two direct analogs of traditional KD for link prediction, i.e., predicted logit-based matching and node representation-based matching. Upon observing direct KD analogs do not perform well for link prediction, we propose a relational KD framework, Linkless Link Prediction (LLP). Unlike simple KD methods that match independent link logits or node representations, LLP distills relational knowledge that is centered around each (anchor) node to the student MLP. Specifically, we propose two matching strategies that complement each other: rank-based matching and distribution-based matching. Extensive experiments demonstrate that LLP boosts the link prediction performance of MLPs with significant margins, and even outperforms the teacher GNNs on 6 out of 9 benchmarks. LLP also achieves a 776.37x speedup in link prediction inference compared to GNNs on the large scale OGB-Citation2 dataset.