 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhihan Zhang
Quantum-Classical Separations in Shallow-Circuit-Based Learning with and without Noises
May 01, 2024
We study quantum-classical separations between classical and quantum supervised learning models based on constant depth (i.e., shallow) circuits, in scenarios with and without noises. We construct a classification problem defined by a noiseless shallow quantum circuit and rigorously prove that any classical neural network with bounded connectivity requires logarithmic depth to output correctly with a larger-than-exponentially-small probability. This unconditional near-optimal quantum-classical separation originates from the quantum nonlocality property that distinguishes quantum circuits from their classical counterparts. We further derive the noise thresholds for demonstrating such a separation on near-term quantum devices under the depolarization noise model. We prove that this separation will persist if the noise strength is upper bounded by an inverse polynomial with respect to the system size, and vanish if the noise strength is greater than an inverse polylogarithmic function. In addition, for quantum devices with constant noise strength, we prove that no super-polynomial classical-quantum separation exists for any classification task defined by shallow Clifford circuits, independent of the structures of the circuits that specify the learning models.
Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Comprehension Training
Apr 26, 2024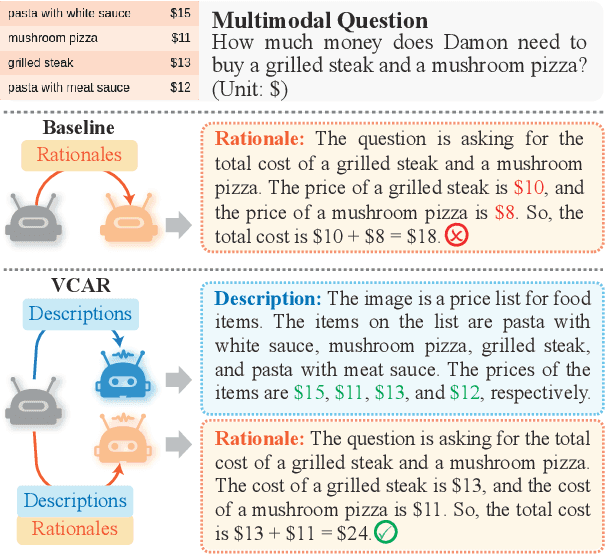
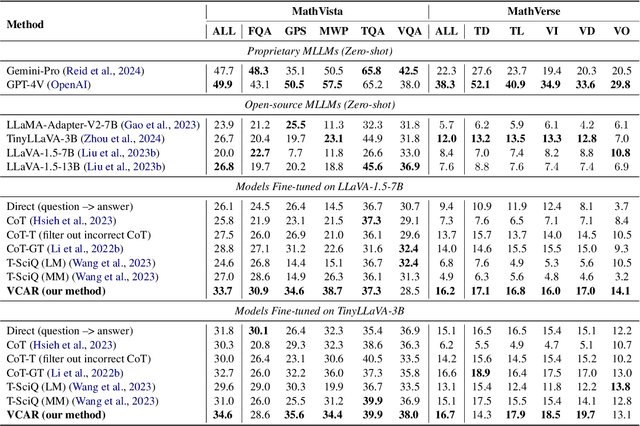

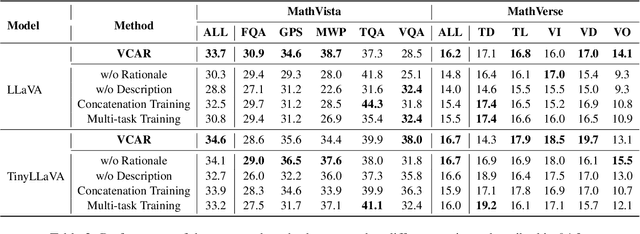
Open-source multimodal large language models (MLLMs) excel in various tasks involving textual and visual inputs but still struggle with complex multimodal mathematical reasoning, lagging behind proprietary models like GPT-4V(ision) and Gemini-Pro. Although fine-tuning with intermediate steps (i.e., rationales) elicits some mathematical reasoning skills, the resulting models still fall short in visual comprehension due to inadequate visual-centric supervision, which leads to inaccurate interpretation of math figures. To address this issue, we propose a two-step training pipeline VCAR, which emphasizes the Visual Comprehension training in Addition to mathematical Reasoning learning. It first improves the visual comprehension ability of MLLMs through the visual description generation task, followed by another training step on generating rationales with the assistance of descriptions. Experimental results on two popular benchmarks demonstrate that VCAR substantially outperforms baseline methods solely relying on rationale supervision, especially on problems with high visual demands.
LabelAId: Just-in-time AI Interventions for Improving Human Labeling Quality and Domain Knowledge in Crowdsourcing Systems
Mar 14, 2024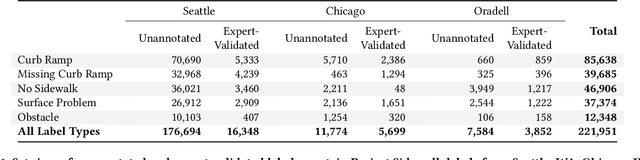
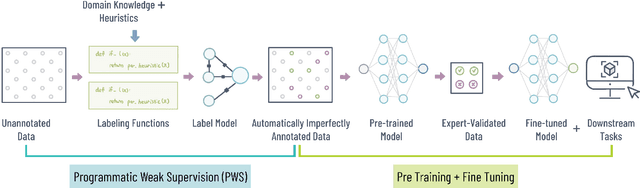

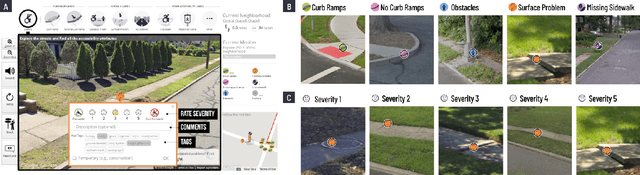
Crowdsourcing platforms have transformed distributed problem-solving, yet quality control remains a persistent challenge. Traditional quality control measures, such as prescreening workers and refining instructions, often focus solely on optimizing economic output. This paper explores just-in-time AI interventions to enhance both labeling quality and domain-specific knowledge among crowdworkers. We introduce LabelAId, an advanced inference model combining Programmatic Weak Supervision (PWS) with FT-Transformers to infer label correctness based on user behavior and domain knowledge. Our technical evaluation shows that our LabelAId pipeline consistently outperforms state-of-the-art ML baselines, improving mistake inference accuracy by 36.7% with 50 downstream samples. We then implemented LabelAId into Project Sidewalk, an open-source crowdsourcing platform for urban accessibility. A between-subjects study with 34 participants demonstrates that LabelAId significantly enhances label precision without compromising efficiency while also increasing labeler confidence. We discuss LabelAId's success factors, limitations, and its generalizability to other crowdsourced science domains.
Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples
Feb 12, 2024Automatic taxonomy induction is crucial for web search, recommendation systems, and question answering. Manual curation of taxonomies is expensive in terms of human effort, making automatic taxonomy construction highly desirable. In this work, we introduce Chain-of-Layer which is an in-context learning framework designed to induct taxonomies from a given set of entities. Chain-of-Layer breaks down the task into selecting relevant candidate entities in each layer and gradually building the taxonomy from top to bottom. To minimize errors, we introduce the Ensemble-based Ranking Filter to reduce the hallucinated content generated at each iteration. Through extensive experiments, we demonstrate that Chain-of-Layer achieves state-of-the-art performance on four real-world benchmarks.
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning
Nov 15, 2023Instruction tuning has remarkably advanced large language models (LLMs) in understanding and responding to diverse human instructions. Despite the success in high-resource languages, its application in lower-resource ones faces challenges due to the imbalanced foundational abilities of LLMs across different languages, stemming from the uneven language distribution in their pre-training data. To tackle this issue, we propose pivot language guided generation (PLUG), an approach that utilizes a high-resource language, primarily English, as the pivot to enhance instruction tuning in lower-resource languages. It trains the model to first process instructions in the pivot language, and then produce responses in the target language. To evaluate our approach, we introduce a benchmark, X-AlpacaEval, of instructions in 4 languages (Chinese, Korean, Italian, and Spanish), each annotated by professional translators. Our approach demonstrates a significant improvement in the instruction-following abilities of LLMs by 29% on average, compared to directly responding in the target language alone. Further experiments validate the versatility of our approach by employing alternative pivot languages beyond English to assist languages where LLMs exhibit lower proficiency.
Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models
Oct 19, 2023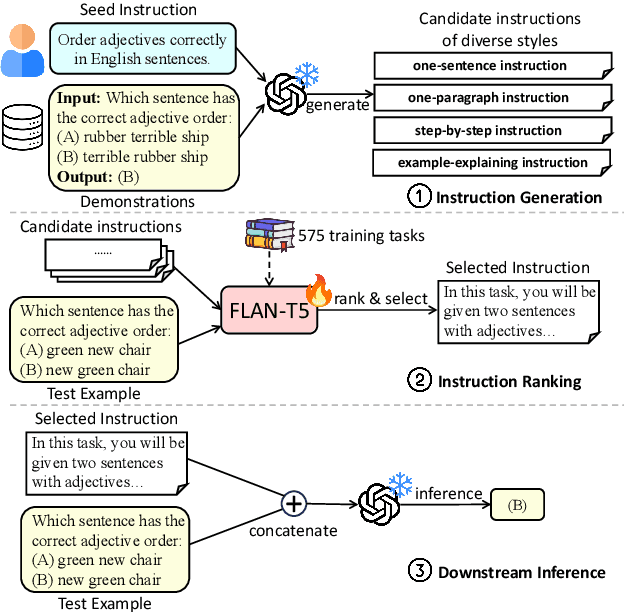
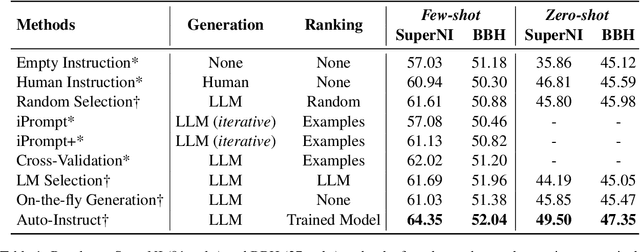

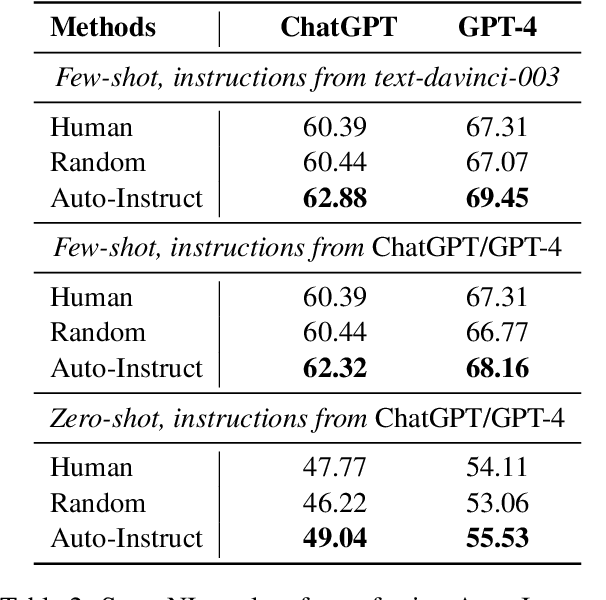
Large language models (LLMs) can perform a wide range of tasks by following natural language instructions, without the necessity of task-specific fine-tuning. Unfortunately, the performance of LLMs is greatly influenced by the quality of these instructions, and manually writing effective instructions for each task is a laborious and subjective process. In this paper, we introduce Auto-Instruct, a novel method to automatically improve the quality of instructions provided to LLMs. Our method leverages the inherent generative ability of LLMs to produce diverse candidate instructions for a given task, and then ranks them using a scoring model trained on a variety of 575 existing NLP tasks. In experiments on 118 out-of-domain tasks, Auto-Instruct surpasses both human-written instructions and existing baselines of LLM-generated instructions. Furthermore, our method exhibits notable generalizability even with other LLMs that are not incorporated into its training process.
Exploring and Characterizing Large Language Models For Embedded System Development and Debugging
Jul 07, 2023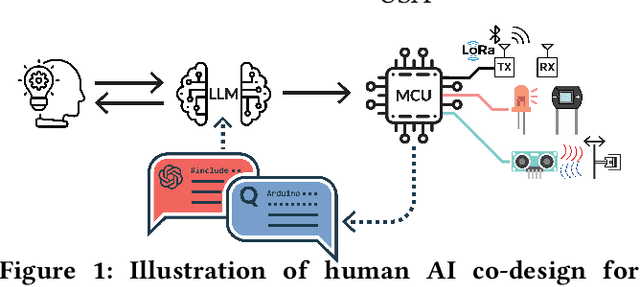
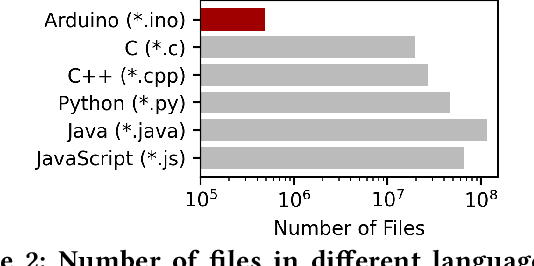
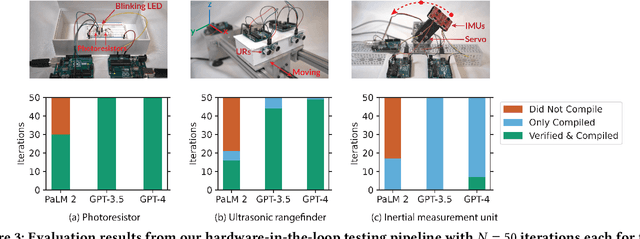
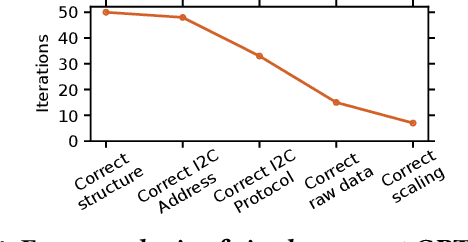
Large language models (LLMs) have shown remarkable abilities to generate code, however their ability to develop software for embedded systems, which requires cross-domain knowledge of hardware and software has not been studied. In this paper we systematically evaluate leading LLMs (GPT-3.5, GPT-4, PaLM 2) to assess their performance for embedded system development, study how human programmers interact with these tools, and develop an AI-based software engineering workflow for building embedded systems. We develop an an end-to-end hardware-in-the-loop evaluation platform for verifying LLM generated programs using sensor actuator pairs. We compare all three models with N=450 experiments and find surprisingly that GPT-4 especially shows an exceptional level of cross-domain understanding and reasoning, in some cases generating fully correct programs from a single prompt. In N=50 trials, GPT-4 produces functional I2C interfaces 66% of the time. GPT-4 also produces register-level drivers, code for LoRa communication, and context-specific power optimizations for an nRF52 program resulting in over 740x current reduction to 12.2 uA. We also characterize the models' limitations to develop a generalizable workflow for using LLMs in embedded system development. We evaluate the workflow with 15 users including novice and expert programmers. We find that our workflow improves productivity for all users and increases the success rate for building a LoRa environmental sensor from 25% to 100%, including for users with zero hardware or C/C++ experience.
Exploring Contrast Consistency of Open-Domain Question Answering Systems on Minimally Edited Questions
May 23, 2023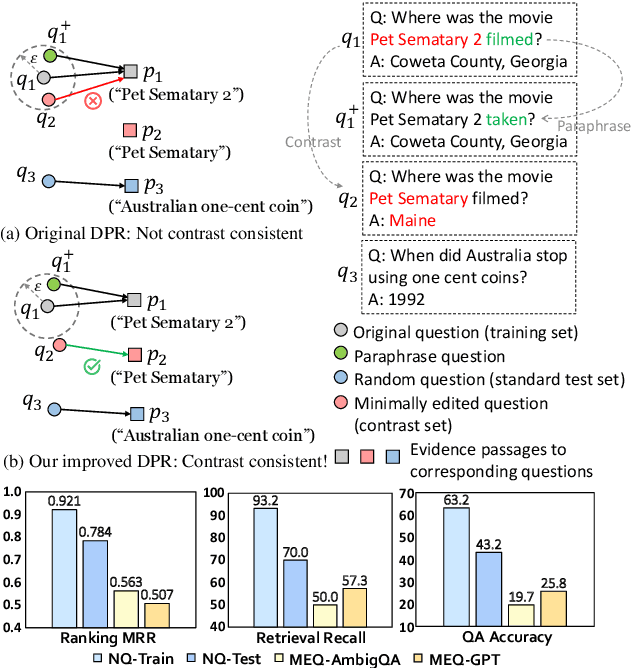
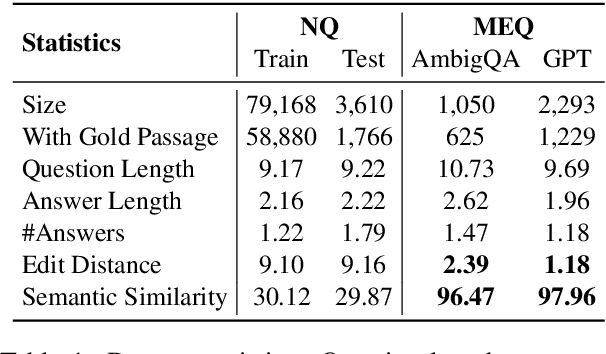


Contrast consistency, the ability of a model to make consistently correct predictions in the presence of perturbations, is an essential aspect in NLP. While studied in tasks such as sentiment analysis and reading comprehension, it remains unexplored in open-domain question answering (OpenQA) due to the difficulty of collecting perturbed questions that satisfy factuality requirements. In this work, we collect minimally edited questions as challenging contrast sets to evaluate OpenQA models. Our collection approach combines both human annotation and large language model generation. We find that the widely used dense passage retriever (DPR) performs poorly on our contrast sets, despite fitting the training set well and performing competitively on standard test sets. To address this issue, we introduce a simple and effective query-side contrastive loss with the aid of data augmentation to improve DPR training. Our experiments on the contrast sets demonstrate that DPR's contrast consistency is improved without sacrificing its accuracy on the standard test sets.
Pre-training Language Models for Comparative Reasoning
May 23, 2023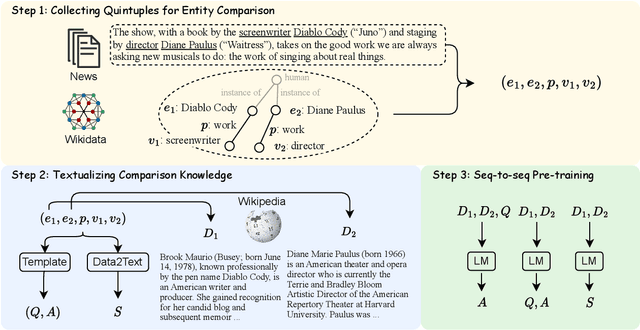


In this paper, we propose a novel framework to pre-train language models for enhancing their abilities of comparative reasoning over texts. While recent research has developed models for NLP tasks that require comparative reasoning, they suffer from costly manual data labeling and limited generalizability to different tasks. Our approach involves a scalable method for collecting data for text-based entity comparison, which leverages both structured and unstructured data, and the design of three novel pre-training tasks. Evaluation on a range of downstream tasks including comparative question answering, question generation, and summarization shows that our pre-training framework significantly improves the comparative reasoning abilities of language models, especially under low-resource conditions. This work also releases the first integrated benchmark for comparative reasoning over texts.
Improving Language Models via Plug-and-Play Retrieval Feedback
May 23, 2023
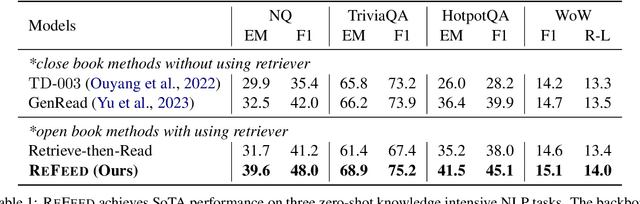


Large language models (LLMs) exhibit remarkable performance across various NLP tasks. However, they often generate incorrect or hallucinated information, which hinders their practical applicability in real-world scenarios. Human feedback has been shown to effectively enhance the factuality and quality of generated content, addressing some of these limitations. However, this approach is resource-intensive, involving manual input and supervision, which can be time-consuming and expensive. Moreover, it cannot be provided during inference, further limiting its practical utility in dynamic and interactive applications. In this paper, we introduce ReFeed, a novel pipeline designed to enhance LLMs by providing automatic retrieval feedback in a plug-and-play framework without the need for expensive fine-tuning. ReFeed first generates initial outputs, then utilizes a retrieval model to acquire relevant information from large document collections, and finally incorporates the retrieved information into the in-context demonstration for output refinement, thereby addressing the limitations of LLMs in a more efficient and cost-effective manner. Experiments on four knowledge-intensive benchmark datasets demonstrate our proposed ReFeed could improve over +6.0% under zero-shot setting and +2.5% under few-shot setting, compared to baselines without using retrieval feedback.