 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengzhao Jia
Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Comprehension Training
Apr 26, 2024
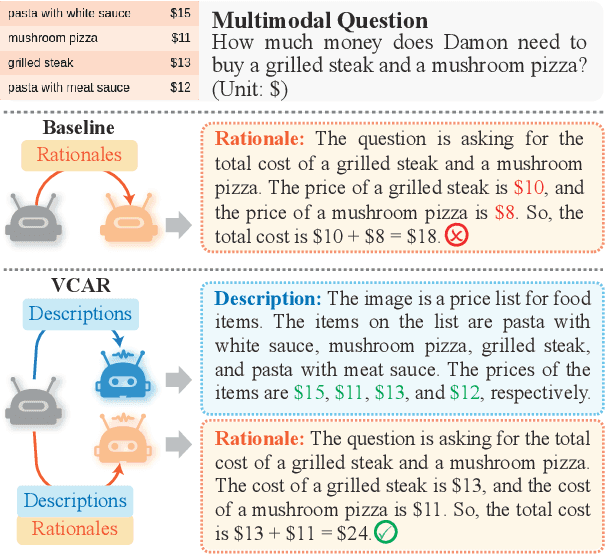
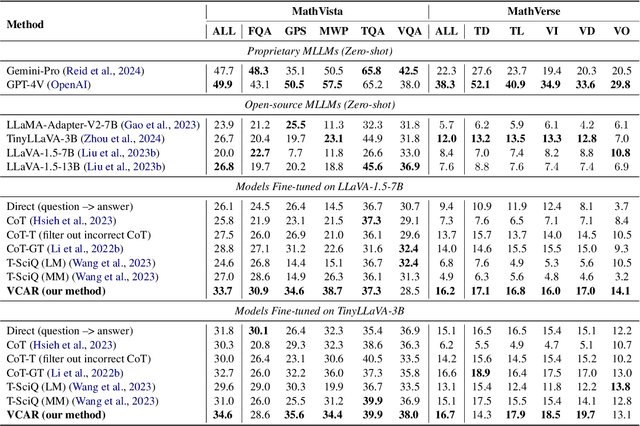

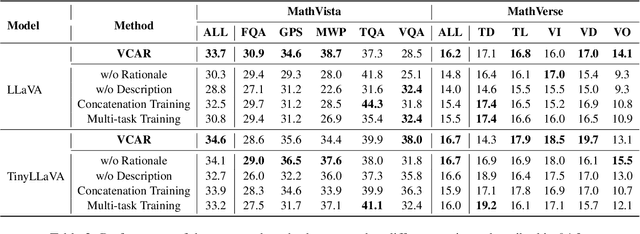
Open-source multimodal large language models (MLLMs) excel in various tasks involving textual and visual inputs but still struggle with complex multimodal mathematical reasoning, lagging behind proprietary models like GPT-4V(ision) and Gemini-Pro. Although fine-tuning with intermediate steps (i.e., rationales) elicits some mathematical reasoning skills, the resulting models still fall short in visual comprehension due to inadequate visual-centric supervision, which leads to inaccurate interpretation of math figures. To address this issue, we propose a two-step training pipeline VCAR, which emphasizes the Visual Comprehension training in Addition to mathematical Reasoning learning. It first improves the visual comprehension ability of MLLMs through the visual description generation task, followed by another training step on generating rationales with the assistance of descriptions. Experimental results on two popular benchmarks demonstrate that VCAR substantially outperforms baseline methods solely relying on rationale supervision, especially on problems with high visual demands.
Debiasing Multimodal Sarcasm Detection with Contrastive Learning
Dec 19, 2023



Despite commendable achievements made by existing work, prevailing multimodal sarcasm detection studies rely more on textual content over visual information. It unavoidably induces spurious correlations between textual words and labels, thereby significantly hindering the models' generalization capability. To address this problem, we define the task of out-of-distribution (OOD) multimodal sarcasm detection, which aims to evaluate models' generalizability when the word distribution is different in training and testing settings. Moreover, we propose a novel debiasing multimodal sarcasm detection framework with contrastive learning, which aims to mitigate the harmful effect of biased textual factors for robust OOD generalization. In particular, we first design counterfactual data augmentation to construct the positive samples with dissimilar word biases and negative samples with similar word biases. Subsequently, we devise an adapted debiasing contrastive learning mechanism to empower the model to learn robust task-relevant features and alleviate the adverse effect of biased words. Extensive experiments show the superiority of the proposed framework.
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning
Nov 15, 2023Instruction tuning has remarkably advanced large language models (LLMs) in understanding and responding to diverse human instructions. Despite the success in high-resource languages, its application in lower-resource ones faces challenges due to the imbalanced foundational abilities of LLMs across different languages, stemming from the uneven language distribution in their pre-training data. To tackle this issue, we propose pivot language guided generation (PLUG), an approach that utilizes a high-resource language, primarily English, as the pivot to enhance instruction tuning in lower-resource languages. It trains the model to first process instructions in the pivot language, and then produce responses in the target language. To evaluate our approach, we introduce a benchmark, X-AlpacaEval, of instructions in 4 languages (Chinese, Korean, Italian, and Spanish), each annotated by professional translators. Our approach demonstrates a significant improvement in the instruction-following abilities of LLMs by 29% on average, compared to directly responding in the target language alone. Further experiments validate the versatility of our approach by employing alternative pivot languages beyond English to assist languages where LLMs exhibit lower proficiency.
FAITHSCORE: Evaluating Hallucinations in Large Vision-Language Models
Nov 02, 2023We introduce FAITHSCORE (Faithfulness to Atomic Image Facts Score), a reference-free and fine-grained evaluation metric that measures the faithfulness of the generated free-form answers from large vision-language models (LVLMs). The FAITHSCORE evaluation first identifies sub-sentences containing descriptive statements that need to be verified, then extracts a comprehensive list of atomic facts from these sub-sentences, and finally conducts consistency verification between fine-grained atomic facts and the input image. Meta-evaluation demonstrates that our metric highly correlates with human judgments of faithfulness. We collect two benchmark datasets (i.e. LLaVA-1k and MSCOCO-Cap) for evaluating LVLMs instruction-following hallucinations. We measure hallucinations in state-of-the-art LVLMs with FAITHSCORE on the datasets. Results reveal that current systems are prone to generate hallucinated content unfaithful to the image, which leaves room for future improvements. Further, we find that current LVLMs despite doing well on color and counting, still struggle with long answers, relations, and multiple objects.
Knowledge-enhanced Memory Model for Emotional Support Conversation
Oct 11, 2023The prevalence of mental disorders has become a significant issue, leading to the increased focus on Emotional Support Conversation as an effective supplement for mental health support. Existing methods have achieved compelling results, however, they still face three challenges: 1) variability of emotions, 2) practicality of the response, and 3) intricate strategy modeling. To address these challenges, we propose a novel knowledge-enhanced Memory mODEl for emotional suppoRt coNversation (MODERN). Specifically, we first devise a knowledge-enriched dialogue context encoding to perceive the dynamic emotion change of different periods of the conversation for coherent user state modeling and select context-related concepts from ConceptNet for practical response generation. Thereafter, we implement a novel memory-enhanced strategy modeling module to model the semantic patterns behind the strategy categories. Extensive experiments on a widely used large-scale dataset verify the superiority of our model over cutting-edge baselines.
Multi-source Semantic Graph-based Multimodal Sarcasm Explanation Generation
Jun 29, 2023



Multimodal Sarcasm Explanation (MuSE) is a new yet challenging task, which aims to generate a natural language sentence for a multimodal social post (an image as well as its caption) to explain why it contains sarcasm. Although the existing pioneer study has achieved great success with the BART backbone, it overlooks the gap between the visual feature space and the decoder semantic space, the object-level metadata of the image, as well as the potential external knowledge. To solve these limitations, in this work, we propose a novel mulTi-source sEmantic grAph-based Multimodal sarcasm explanation scheme, named TEAM. In particular, TEAM extracts the object-level semantic meta-data instead of the traditional global visual features from the input image. Meanwhile, TEAM resorts to ConceptNet to obtain the external related knowledge concepts for the input text and the extracted object meta-data. Thereafter, TEAM introduces a multi-source semantic graph that comprehensively characterize the multi-source (i.e., caption, object meta-data, external knowledge) semantic relations to facilitate the sarcasm reasoning. Extensive experiments on a public released dataset MORE verify the superiority of our model over cutting-edge methods.
* Accepted by ACL 2023 main conference