 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Liu
An Analysis of Driver-Initiated Takeovers during Assisted Driving and their Effect on Driver Satisfaction
Apr 19, 2024
During the use of Advanced Driver Assistance Systems (ADAS), drivers can intervene in the active function and take back control due to various reasons. However, the specific reasons for driver-initiated takeovers in naturalistic driving are still not well understood. In order to get more information on the reasons behind these takeovers, a test group study was conducted. There, 17 participants used a predictive longitudinal driving function for their daily commutes and annotated the reasons for their takeovers during active function use. In this paper, the recorded takeovers are analyzed and the different reasons for them are highlighted. The results show that the reasons can be divided into three main categories. The most common category consists of takeovers which aim to adjust the behavior of the ADAS within its Operational Design Domain (ODD) in order to better match the drivers' personal preferences. Other reasons include takeovers due to leaving the ADAS's ODD and corrections of incorrect sensing state information. Using the questionnaire results of the test group study, it was found that the number and frequency of takeovers especially within the ADAS's ODD have a significant negative impact on driver satisfaction. Therefore, the driver satisfaction with the ADAS could be increased by adapting its behavior to the drivers' wishes and thereby lowering the number of takeovers within the ODD. The information contained in the takeover behavior of the drivers could be used as feedback for the ADAS. Finally, it is shown that there are considerable differences in the takeover behavior of different drivers, which shows a need for ADAS individualization.
RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
Apr 18, 2024Retrieval-Augmented Generation (RAG) has shown significant improvements in various natural language processing tasks by integrating the strengths of large language models (LLMs) and external knowledge databases. However, RAG introduces long sequence generation and leads to high computation and memory costs. We propose Thoth, a novel multilevel dynamic caching system tailored for RAG. Our analysis benchmarks current RAG systems, pinpointing the performance bottleneck (i.e., long sequence due to knowledge injection) and optimization opportunities (i.e., caching knowledge's intermediate states). Based on these insights, we design Thoth, which organizes the intermediate states of retrieved knowledge in a knowledge tree and caches them in the GPU and host memory hierarchy. Thoth proposes a replacement policy that is aware of LLM inference characteristics and RAG retrieval patterns. It also dynamically overlaps the retrieval and inference steps to minimize the end-to-end latency. We implement Thoth and evaluate it on vLLM, a state-of-the-art LLM inference system and Faiss, a state-of-the-art vector database. The experimental results show that Thoth reduces the time to first token (TTFT) by up to 4x and improves the throughput by up to 2.1x compared to vLLM integrated with Faiss.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
DEGNN: Dual Experts Graph Neural Network Handling Both Edge and Node Feature Noise
Apr 14, 2024Graph Neural Networks (GNNs) have achieved notable success in various applications over graph data. However, recent research has revealed that real-world graphs often contain noise, and GNNs are susceptible to noise in the graph. To address this issue, several Graph Structure Learning (GSL) models have been introduced. While GSL models are tailored to enhance robustness against edge noise through edge reconstruction, a significant limitation surfaces: their high reliance on node features. This inherent dependence amplifies their susceptibility to noise within node features. Recognizing this vulnerability, we present DEGNN, a novel GNN model designed to adeptly mitigate noise in both edges and node features. The core idea of DEGNN is to design two separate experts: an edge expert and a node feature expert. These experts utilize self-supervised learning techniques to produce modified edges and node features. Leveraging these modified representations, DEGNN subsequently addresses downstream tasks, ensuring robustness against noise present in both edges and node features of real-world graphs. Notably, the modification process can be trained end-to-end, empowering DEGNN to adjust dynamically and achieves optimal edge and node representations for specific tasks. Comprehensive experiments demonstrate DEGNN's efficacy in managing noise, both in original real-world graphs and in graphs with synthetic noise.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
EventGround: Narrative Reasoning by Grounding to Eventuality-centric Knowledge Graphs
Mar 30, 2024Narrative reasoning relies on the understanding of eventualities in story contexts, which requires a wealth of background world knowledge. To help machines leverage such knowledge, existing solutions can be categorized into two groups. Some focus on implicitly modeling eventuality knowledge by pretraining language models (LMs) with eventuality-aware objectives. However, this approach breaks down knowledge structures and lacks interpretability. Others explicitly collect world knowledge of eventualities into structured eventuality-centric knowledge graphs (KGs). However, existing research on leveraging these knowledge sources for free-texts is limited. In this work, we propose an initial comprehensive framework called EventGround, which aims to tackle the problem of grounding free-texts to eventuality-centric KGs for contextualized narrative reasoning. We identify two critical problems in this direction: the event representation and sparsity problems. We provide simple yet effective parsing and partial information extraction methods to tackle these problems. Experimental results demonstrate that our approach consistently outperforms baseline models when combined with graph neural network (GNN) or large language model (LLM) based graph reasoning models. Our framework, incorporating grounded knowledge, achieves state-of-the-art performance while providing interpretable evidence.
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Mar 18, 2024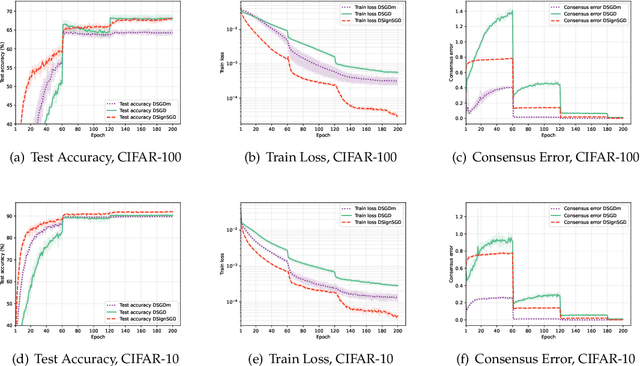
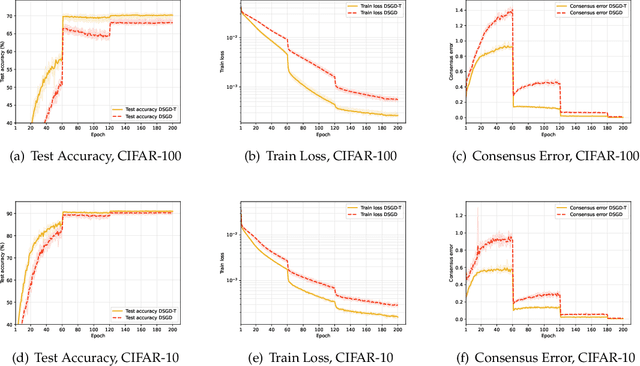
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework, named DSM, to analyze the global convergence of decentralized stochastic subgradient methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework encompasses a wide range of existing efficient decentralized subgradient methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGDm). In addition, we introduce SignSGD employing the sign map to regularize the update directions in DSGDm, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient methods with convergence guarantees in the training of nonsmooth neural networks.
Mipha: A Comprehensive Overhaul of Multimodal Assistant with Small Language Models
Mar 15, 2024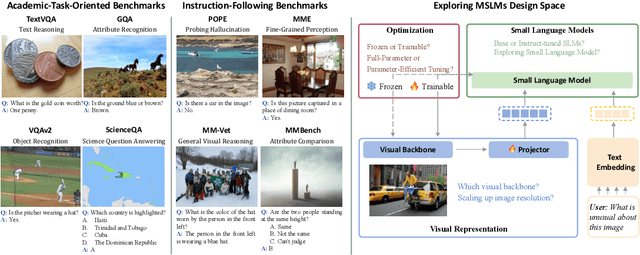
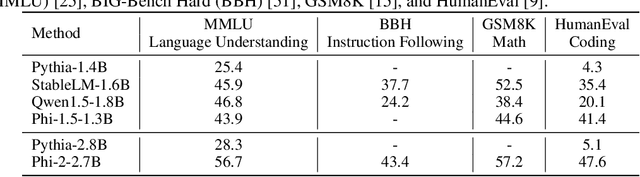
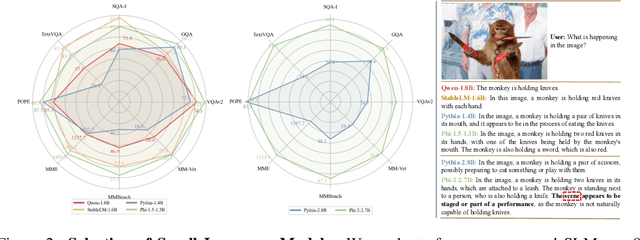
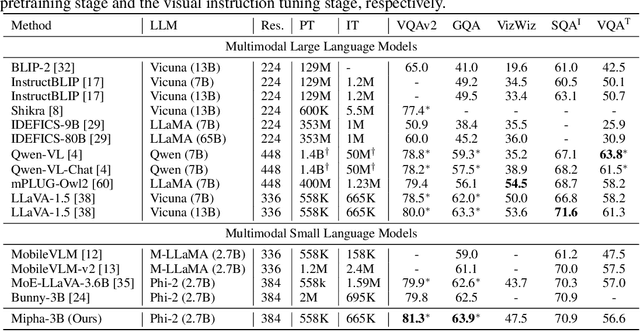
Multimodal Large Language Models (MLLMs) have showcased impressive skills in tasks related to visual understanding and reasoning. Yet, their widespread application faces obstacles due to the high computational demands during both the training and inference phases, restricting their use to a limited audience within the research and user communities. In this paper, we investigate the design aspects of Multimodal Small Language Models (MSLMs) and propose an efficient multimodal assistant named Mipha, which is designed to create synergy among various aspects: visual representation, language models, and optimization strategies. We show that without increasing the volume of training data, our Mipha-3B outperforms the state-of-the-art large MLLMs, especially LLaVA-1.5-13B, on multiple benchmarks. Through detailed discussion, we provide insights and guidelines for developing strong MSLMs that rival the capabilities of MLLMs. Our code is available at https://github.com/zhuyiche/Mipha.
Benchmarking Zero-Shot Robustness of Multimodal Foundation Models: A Pilot Study
Mar 15, 2024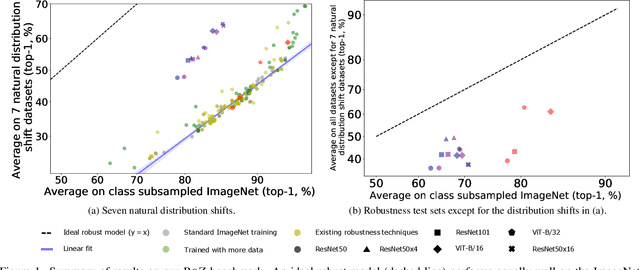
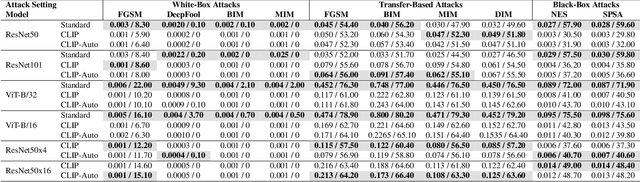
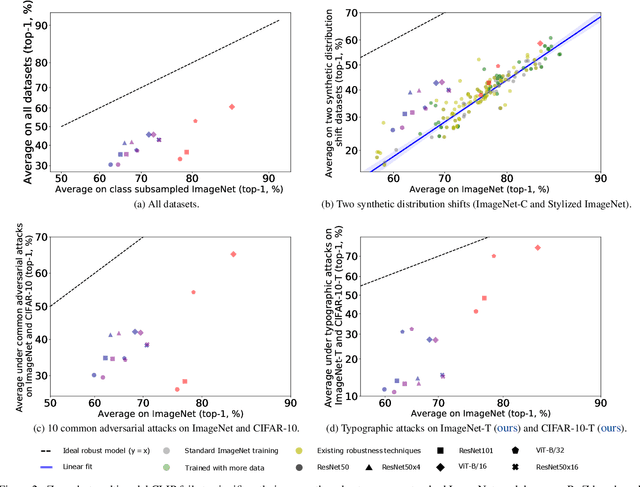
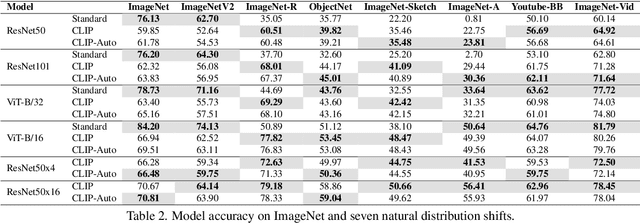
Pre-training image representations from the raw text about images enables zero-shot vision transfer to downstream tasks. Through pre-training on millions of samples collected from the internet, multimodal foundation models, such as CLIP, produce state-of-the-art zero-shot results that often reach competitiveness with fully supervised methods without the need for task-specific training. Besides the encouraging performance on classification accuracy, it is reported that these models close the robustness gap by matching the performance of supervised models trained on ImageNet under natural distribution shift. Because robustness is critical to real-world applications, especially safety-critical ones, in this paper, we present a comprehensive evaluation based on a large-scale robustness benchmark covering 7 natural, 3 synthetic distribution shifts, and 11 adversarial attacks. We use CLIP as a pilot study. We show that CLIP leads to a significant robustness drop compared to supervised ImageNet models on our benchmark, especially under synthetic distribution shift and adversarial attacks. Furthermore, data overlap analysis suggests that the observed robustness under natural distribution shifts could be attributed, at least in part, to data overlap. In summary, our evaluation shows a comprehensive evaluation of robustness is necessary; and there is a significant need to improve the robustness of zero-shot multimodal models.
Generation is better than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection
Mar 15, 2024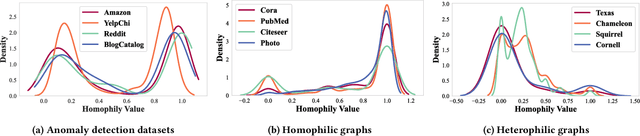
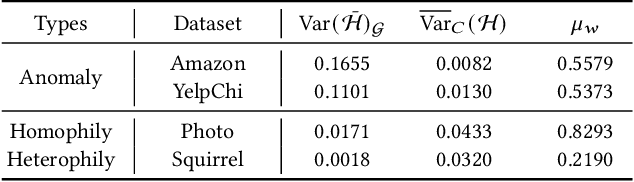
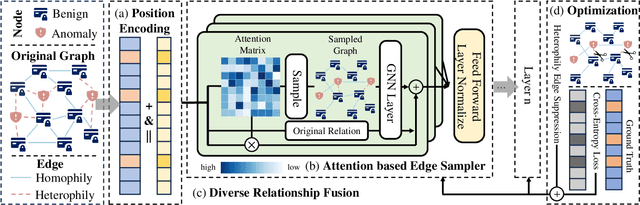
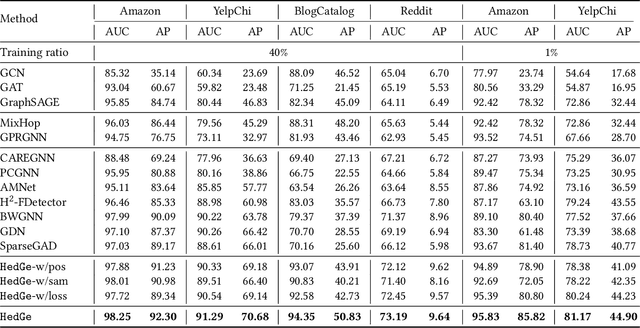
Graph-based anomaly detection is currently an important research topic in the field of graph neural networks (GNNs). We find that in graph anomaly detection, the homophily distribution differences between different classes are significantly greater than those in homophilic and heterophilic graphs. For the first time, we introduce a new metric called Class Homophily Variance, which quantitatively describes this phenomenon. To mitigate its impact, we propose a novel GNN model named Homophily Edge Generation Graph Neural Network (HedGe). Previous works typically focused on pruning, selecting or connecting on original relationships, and we refer to these methods as modifications. Different from these works, our method emphasizes generating new relationships with low class homophily variance, using the original relationships as an auxiliary. HedGe samples homophily adjacency matrices from scratch using a self-attention mechanism, and leverages nodes that are relevant in the feature space but not directly connected in the original graph. Additionally, we modify the loss function to punish the generation of unnecessary heterophilic edges by the model. Extensive comparison experiments demonstrate that HedGe achieved the best performance across multiple benchmark datasets, including anomaly detection and edgeless node classification. The proposed model also improves the robustness under the novel Heterophily Attack with increased class homophily variance on other graph classification tasks.